fcos:fully convolutional one-stage object detection
mmdetection最小复刻版(六):FCOS深入可视化分析 - 知乎0 概要论文名称: FCOS: A simple and strong anchor-free object detector 论文地址: https://arxiv.org/pdf/2006.09214v3.pdf 论文名称: FCOS: Fully Convolutional One-Stage Object Detection 论文地址: ht… https://zhuanlan.zhihu.com/p/267346645轻松掌握 MMDetection 中常用算法(三):FCOS - 知乎文@ 0000070 摘要在前系列文章中,我们选择了主流一阶段算法 RetinaNet 和二阶段算法 Faster R-CNN/Mask R-CNN 进行了详细解读,但是其都属于 anchor-based 算法,随着 anchor-free 思路的兴起,出现了一些性能…https://zhuanlan.zhihu.com/p/358056615FCOS算法详解_AI之路-CSDN博客_fcos论文:FCOS: Fully Convolutional One-Stage Object Detection论文链接:https://arxiv.org/abs/1904.01355代码链接:https://github.com/tianzhi0549/FCOS/这篇是发表在CVPR2019的目标检测论文,主要创新点在于去掉了anchor做检测,也就是常说anchor free,这是最近一...https://blog.csdn.net/u014380165/article/details/90962991
https://zhuanlan.zhihu.com/p/267346645轻松掌握 MMDetection 中常用算法(三):FCOS - 知乎文@ 0000070 摘要在前系列文章中,我们选择了主流一阶段算法 RetinaNet 和二阶段算法 Faster R-CNN/Mask R-CNN 进行了详细解读,但是其都属于 anchor-based 算法,随着 anchor-free 思路的兴起,出现了一些性能…https://zhuanlan.zhihu.com/p/358056615FCOS算法详解_AI之路-CSDN博客_fcos论文:FCOS: Fully Convolutional One-Stage Object Detection论文链接:https://arxiv.org/abs/1904.01355代码链接:https://github.com/tianzhi0549/FCOS/这篇是发表在CVPR2019的目标检测论文,主要创新点在于去掉了anchor做检测,也就是常说anchor free,这是最近一...https://blog.csdn.net/u014380165/article/details/90962991
现在看很多anchor-free的方法都有east的影子,和east都很像。点的预测其实就是anchor=1.anchor-based向anchor-free进步的关键其实就在正负样本的分配问题,如何定义正负样本,正负样本的分布,分配,loss设计都是关键,在cascade rcnn通过不断的控制IOU对正负样本进行筛选来设计样本分布,在retinanet中通过sigmoid-based的focal loss来抑制负样本中的简单样本占据梯度的问题,在centernet中,由于是anchor-free的方法,anchor-free可以理解成一个点就是一个anchor,因此正样本就是中心点,负样本就是中心点之外的点,用gaussian focal loss对中心点附近的样本进行降权,它本身不存在正负样本分配问题,但是极少量的正样本和负样本还是会对训练造成影响,centernet收敛及其缓慢,而且不做0/1,还是用高斯核产生0-1分布,另外由于centernet本身中心点重叠不严重(coco上不到0.1%),fcos的正负样本是强制在FPN上的预测范围来控制的,fcos上正样本是gt框内以中心点采样的一个范围的点,负样本是采样范围外的点(中心采样),正负样本基本是均衡的(一张图上目标区域和非目标区域面积相差不大),它要处理两框重叠的问题,因此通过超参强制在不同层预测不同尺度目标还缓解这个问题,之前在retinanet中5个fpn的输出图是非强制预测,在小stride上预测出大目标也是有可能的,最后能不能出框区域于nms(预测置信度够不够高),fcos扩大了正样本的范围,和centernet高斯核的思路一样,但是centernet的高斯也会有中心点为正样本,fcos扩大了正样本范围,那么就会带来正样本重叠问题,因此必须要通过分层FPN预测来解决。
1.Introduction
1.检测性能对anchor的size,aspect ratios(纵横比)很敏感,在reinanet中,coco上,改变这些超参数对AP有4%的影响。2.即便有很好的设计,由于anchor的scale和aspect ratio是保持固定的,检测器在处理具有较大形状变化的候选对象时会有困难,预定义的anchor伤害了检测器的泛化能力(yolov2有anchor类聚),在不同目标尺寸或者aspect ratios上的新检测任务上需要重新设计anchor。3.为了实现高召回,基于anchor的检测器需要在输入图像上密集的设置anchor,在一张短边800的输入图像的FPN上有超过180k个anchor。大多数这些anchor在训练时被标记为负样本,过多的负样本加剧了训练中的正负样本不均衡。4.anchor涉及比较复杂的计算,比如计算anchor和gt之间的IOU。
2.our approach
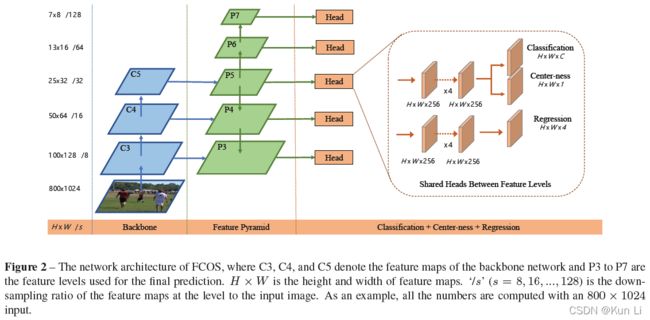
网络结构和retinanet相似,backbone+fpn+分类回归支路,centerness有两种做法,一种是和分类共享子网权重,一种是和回归共享子网权重,在后续的优化中,其实采用的是后者,mmdet中也是后者。
2.1 fully convolutional one-stage object detector
对每一个特征层Fi,s是步长,输入图像的真实边界框定义Bi,Bi=(x0,y0,x1,y1,c),其中(x0,y0)是左上角坐标,(x1,y1)是右下角坐标,c是类别,coco中就是80,对于特征图上的每个位置(x,y),可以将其映射回输入图像为:
![]()
它是原图上的感受野。fcos直接将位置视为训练样本,这些位置是在不同的特征图上的,映射回原图也是有一定的感受野区域的。位置即是点的坐标,fcos作为fcn形式的一种,本质还是做点的分类和回归,其实类似的思路在文本检测上确实很常见的,从east开始就是基于pixel的检测方法。
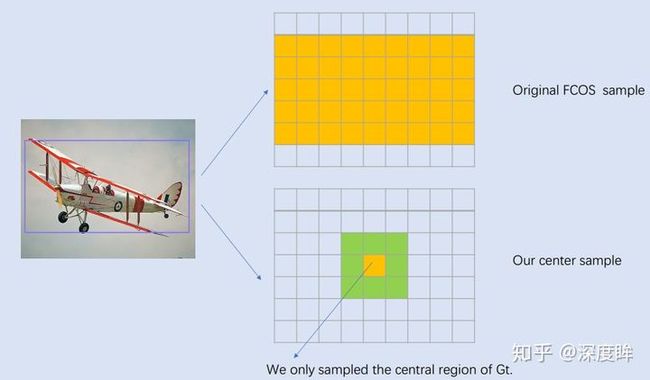
具体来说,(x,y)落在gt框内即是正样本,类别c是gt的类别,否则就是负样本,当然后续的改进版本不是这样的,后续的改进版本是有一个中心采样的策略,并不是落在框内的就是正样本,中心采样很重要,下面这个例子,bbox标注通常都有噪声或者会框住很多无关区域,如果这些无关区域也负责回归则比较奇怪,和之前的centernet做高斯核和中心区域做权重是类似,不过用全框会有很多噪声,会回归产生难度,因此用了一个中心采样,只取中心一块区域。

除了分类分支,还有一个4D的回归分支,分别回归(l,t,r,b),这里的四个值分别对应到边界框四条边的距离,如下所示,

不过值得注意的是,如果一个位置落入了多个边界框,它会被认为是不明确的样本,我们只需要选择面积最小的边界框作为其回归目标。 上图中红蓝色交织的就是重叠点,这后续会通过fpn分层预测来处理,这种现象几乎不会影响性能。

It is worth noting that FCOS can leverage as many foreground samples as possible to train the regressor. 值得注意的是fcos可以利用尽可能多的前景样本来训练回归器,anchor-based只会选择有足够IOU阈值的做正样本,但是fcos中心采样之后的区域都是正样本,因此正样本更多,也更准,这里面和后面的分层fpn预测结合起来,也会产生更多的正样本区域。
network outputs
网络的最后一层输出80D的类别标签p和4D的边界框(l,t,r,b),我们训练和C个二分类,而不是多分类,这里和retinanet是一致的,fcos比基于anchor-based的一个像素点有9个anchor的方法在网络输出变量上要小9倍,因为fcos只对一个像素进行分类回归。这里用的sigmod-based的检测器的cls的score普遍偏低,因为想召回更多的框,值高了很容易漏掉。
loss function:

Lcls是focal loss,Lreg是IOU loss,求和是在特征图的所有位置,但是归一只在正样本上。
Inference
推理时选择的分类分支分数p>0.05的框来做预测框。
2.2 multi-level prediction with fpn for fcos
应用多级fpn预测可能用于处理的两个问题是:
1.The large stride (16 stride) of the final feature maps in a CNN can result in a relatively low best possible recall (BPR). 在最终的特征图最大stride=16会不会导致一个低的召回。对于anchor-based的方法,低召回可以通过降低正样本的IOU阈值来缓解(包括anchor越密集,理论上召回也是越高的),fcos,因此降采样的步长比较大,可能没有办法召回在最终特征图上没有位置编码的对象,原图的尺寸到stride很大的特征图是变小的,因此原图上的目标可能经过多个降采样之后在最终的特征图上就没有位置了,因此召不回来,

上图中的带有fpn的retinanet,low-quality matches就是retinanet中的min_pos_iou参数,默认是0,如果gt bbox和所有的anchor的最大iou值大于等于0,那么该gt所对应的anchor也是正样本,用gt和所有的anchor比的话,就是为了保证所有的gt都至少有一个anchor与之匹配。不使用的话,对于某些gt,如果其和anchor的最大iou没有超过正样本阈值的话,它就是负样本,它是正样本阈值的下限,从图中可知,retinanet从不使用,到设为0.4,到设为0,其召回上涨到99.32%,fcos在不用fpn时,也很高,因为其bbox中心范围内都算正样本,所以召回肯定也不低,通过多级fpn预测可以进一步改善召回,可以匹配retinanet。
2.gt框的重叠会导致难以处理的歧义,即重叠的某个位置应该回归哪个边界框?这个问题确实会导致检测器性能下降,fpn中,我们在不同级别的特征图上检测不同大小的对象,用了5个层级的特征图,p3,p4,p5,p6,p7,p3,p4,p5是backbone产生的C3,C4,C5通过1x1conv得到,p6,p7是在p5,p6上用stride=2的conv得到的,因此5个层级的stride分别为8,16,32,64,128.在anchor-based的方法中,一般通过在不同的stride的特征图上设定不同尺寸的anchor实现不同尺度目标的预测,但是这种方式本身不是强制的,也就是说有一些大目标在浅层预测也是也可以得到的,但是fcos不一样,fcos是更加明确的预测任务分配,是强制的,Unlike anchor-based detectors, which assign anchor boxes with different sizes to different feature levels, we directly limit the range of bounding box regression for each level.与anchor-based不同,直接限制了每个fpn的特征图能够回归的box的范围,we firstly compute the regression targets l, t, r and b for each location on all feature levels.在所有的特征图的每个位置上计算了l,t,r,b,这四个值是对应四条边的距离,这max(l,t,r,b)的值就对应在么个fpn上回归的范围值,作者在fcos上设定了5个范围,分别是p1负责(0,64),p2负责(64,128),p3负责(128,256),p4负责(256,512),p5负责(512,inf),Since objects with different sizes are assigned to different feature levels and most overlapping happens between objects with considerably different sizes.因为具有不同大小的对象被分配到不同的特征级别,并且大多数重叠发生在具有显著不同大小的对象之间,如果一个位置,使用了多级预测,仍然分配多个gt框,在同一个层级的特征图上,我们就选择面积最小的做它的gt(类别gt)。
这个地方也是有几点需要讨论的:
1.两个视角,第一全部映射到input image上,正样本区域内的坐标点到边框的距离的范围只有一个,如果是63,就在第一个fpn上预测,如果是68,就在第二个fpn上预测,第二,将gt映射到5个特征图上,中心采样之后,点到四边的max是不一样的,有的可能在63,在第一个fpn上,但是同样的点在第二层可能在65就满足了第二层,所以5个特征图是存在跨层同一个gt的多个正样本的,论文说的其实就第二个视角。
2.对于同一个gt bbox,首先映射到每一个输出层,利用center_sampling_ratio值计算出该gt bbox在每一层的正样本区域以及对应的l,t,r,b的值,此时是在5个特征图上都计算了gt bbox的正样本区域。对于每个输出层的正样本区域,遍历每个point的位置,计算其max(l,t,r,b)的值是否在指定的范围内,不再范围内的就是背景,注意理论上应该一个gt多对应的点的只在fpn的一层被指定为正样本,在其他层都是负样本,同一个gt的不同框在不同层都有正样本也不是坏事,这种先映射的方法也是论文的方法其实是增加了更多的正样本区域,所有的gt被映射到不同层,在5个层中都中心采样正样本的话,max的值是不同的,stride大的层的max肯定要stride小的层的max值要小,即便是范围没有交集,对同一个gt仍然有可能是跨层分配的,但是这种增加正样本的手段会不会对重叠gt所对应的点呢?不会的,重叠gt有影响的是不同类的,同一个类是没有影响的。

正样本区域重叠的情况占了23.16%,通常分层fpn,这种歧义样本降低到7.14%,在进一步,假如歧义样本所属的类别一致,这对分类没影响,对回归可能会有一些影响,把这样样本如果去掉,则比重降低到3.75%,可见影响越来越小。
在不同特征级别之间共享head,retinanet也是这么做的,检测和回归的head是共享的,但是4层的conv是不共享的。然后回归不同的大小范围是需要不同的特征级别的,例如p3是0-64,p4是64-128,因此对于不同的特征级别使用相同的head是不合理的,在exp(x)上,我们使用exp(s*x)来自动调整特征级别p的指数函数的基数,这个方法和人脸中基于margin的arcface中的s有一致,||w||,||x||都做归一化之后,rescale个s,再计算角度空间的cos(x+m)。这种方式要记住,exp可以将原本有正有负的分支结果都转成正的,但是exp(x)是x越大,指数越强,因此他有对值比较大的正数有增强的效果就是波峰过大,可以考虑除一个T来减弱波峰,在阿里的hybrid-bandit的视觉排序函数中就用了个T来调节softamx的结果,不要让类别之间的差值过大,梯度容易回传不上来,两边饱和度,没梯度了。
2.3 center-ness for fcos
远离对象中心的位置产生了很多低质量的预测边界框。在不引入 centerness 分支情况下,作者发现推理时候在 gt bbox 附近会预测出一些低质量的 bbox,原因是训练时候对于回归分支,正样本区域的权重是一样的,导致那些虽然是正样本但是离 gt bbox 中心比较远的点对最终 loss 产生了比较大的影响,这看起来不太合理。 作者解决办法是引入额外的 centerness 分类分支,该分支的 target 是离 gt bbox 中心点越近,该值越大,范围是 0-1。虽然这是一个回归问题,但是作者采用的依然是 bce loss,并且 centerness 分支也仅仅对正样本点进行训练。该分支训练时候loss下降的特别慢,其实这是非常正常的,这其实是整图回归问题,在每个点处都要回归出对应值其实是一个密集预测问题,难度是很大的,loss下降慢非常正常。这个分支的target如下,
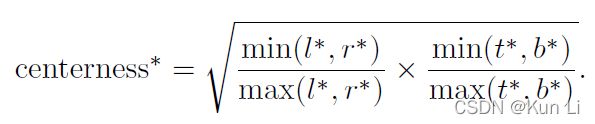
在bce中监督学习这个centerness,这个值本身学出来也是在0-1之间的,论文给了两种做法,第一种是和cls相乘,作监督,第二种是和回归的bbox相乘,作监督,一个是centerness loss,另一个是就是本身预测出来的这个值和分类和回归像个分支再乘一下作监督,其实这个和centernet中的gaussian focal loss中的(1-Yxyc)^β很像,都是对距离中心距离不同的样本进行loss调整。mmdet中选择的是添加在回归分支上。
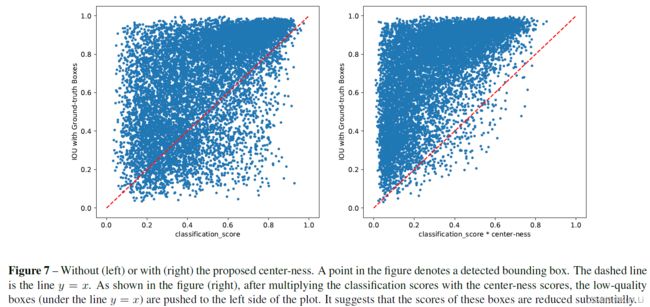
上图中,横坐标是分类分数,纵坐标是回归的正样本的框和gt的IOU,可见有了centerness之后效果更好。
4.experiment
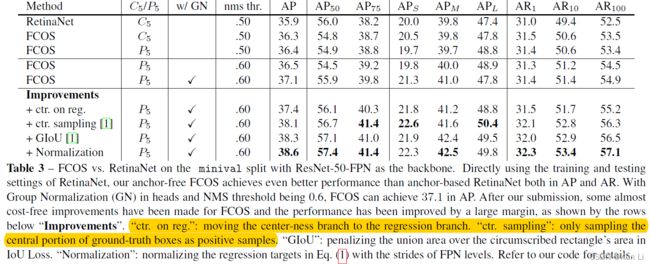

整体看本文,就是pixel-based的方法,其实论文第一版和最终版差距还是很大的,最终版本用了很多的trick,将map做了进一步的提升,目标检测的核心问题离不开正负样本的问题,如何定义正负样本,如何分配,以及平衡loss设计,fcos定义中心点采样为正样本,其余为负样本,都是点级别的,其实第一版中是目标框内是正样本,目标框外是负样本,后来改了,改成中心采样了,当然更合理了,不过也带来了一个center_sampling_ratio的超参,定义了正负样本之后,因为是区域了,不点centernet中的点了,因此会有不同类别目标框重叠,像素点到底回归哪一类的问题,这个问题在centernet中因为只考虑中心点,coco上中心点重合的不到0.1%,但是区域的话有23.16%,在这里采用fpn分层预测,不同的fpn的层负责预测不同尺度的目标框,在原图中可能球拍和人重叠了,但是在stride=128的图上可能是检测人的,在stride=16的图上只检测球拍,通过这种方式分离开,从而解决这个问题。最后在各种trick的加持下,也实现了很好的效果。