Spark-3.1.2编译适应 CDH-5.16.2
Spark-3.1.2编译适应 CDH-5.16.2
这是仓库地址:gitee 3.1.2-cdh5.16.2,下载完成后直接运行
build-run.sh即可
编译教程
pom.xml配置修改
修改Spark根目录下的pom文件,添加 cloudera镜像(mirror)
<repository>
<id>gcs-maven-central-mirrorid>
<name>GCS Maven Central mirrorname>
<url>https://maven-central.storage-download.googleapis.com/maven2/url>
<releases>
<enabled>trueenabled>
releases>
<snapshots>
<enabled>falseenabled>
snapshots>
repository>
<repository>
<id>alimavenid>
<name>aliyun mavenname>
<url>http://maven.aliyun.com/nexus/content/groups/public/url>
repository>
<repository>
<id>clouderaid>
<name>cloudera repositoryname>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/url>
repository>
修改pom文件中的hadoop版本
默认是带的hadoop 3.2 ,需要将 hadoop.version 属性改为 2.6.0-cdh5.16.2
注意3:如果scala 版本为2.10.x ,需要进行
./dev/change-scala-version.sh 2.10
如果为2.11.x,需要进行
./dev/change-scala-version.sh 2.11
编译指令
./dev/make-distribution.sh \
--name 2.6.0-cdh5.16.2 --tgz -Pyarn -Phadoop-2.7 \
-Phive -Phive-thriftserver -Dhadoop.version=2.6.0-cdh5.16.2 -X
我用的是spark的make-distribution.sh脚本进行编译,这个脚本其实也是用maven编译的,
- –tgz 指定以tgz结尾
- –name后面跟的是我们Hadoop的版本,在后面生成的tar包我们会发现名字后面的版本号也是这个(这个可以看make-distribution.sh源码了解)
- -Pyarn 是基于yarn
- -Dhadoop.version=2.6.0-cdh5.16.2 指定Hadoop的版本。
- -X 编译时候打印更完整的日志
解压安装
以下为编译成功界面
# 部署
tar -zxvf spark-3.1.2-bin-2.6.0-cdh5.16.2 -C /opt/spark3
将CDH集群的 spark-env.sh 复制到/data/software/spark/conf 下
cp /etc/spark/conf/spark-env.sh /opt/spark3/conf/
然后设置添加一下 spark-env.sh部分环境变量
export SPARK_HOME=/opt/spark3 # 你的spark路径
export JAVA_HOME=/usr/java/jdk1.8.0_181-cloudera # 你的Java路径
export HADOOP_HOME=/opt/cloudera/parcels/CDH/lib/hadoop # 你的hadoop路径
export HADOOP_CONF_DIR="/etc/hadoop/conf:/opt/cloudera/hive2/conf/" # 你的hadoop与hive的配置文件路径
# 如果用的CDH的Hadoop(这边是启动时加载必须的jar包)
#export SPARK_DIST_CLASSPATH=$(paste -sd: "/etc/spark/conf/classpath.txt")
#export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/opt/cloudera/parcels/GPLEXTRAS/lib/hadoop/lib/native
这样就可以直接连接hive了,我这边配置的hive是连接新集成的hive2.3.9
常见问题
- 无法编译yarn
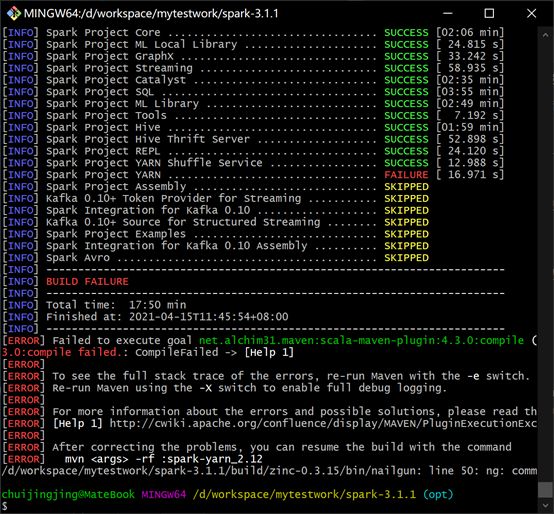
原因:Spark3.x 对hadoop2.x 支持有问题,需要手动修改以下路径源码
resource-managers/yarn/src/main/scala/org/apache/spark/deploy/yarn/Client.scala
在文件中搜索到如下代码:
sparkConf.get(ROLLED_LOG_INCLUDE_PATTERN).foreach { includePattern =>
try {
val logAggregationContext = Records.newRecord(classOf[LogAggregationContext])
logAggregationContext.setRolledLogsIncludePattern(includePattern)
sparkConf.get(ROLLED_LOG_EXCLUDE_PATTERN).foreach { excludePattern =>
logAggregationContext.setRolledLogsExcludePattern(excludePattern)
}
appContext.setLogAggregationContext(logAggregationContext)
} catch {
case NonFatal(e) =>
logWarning(s"Ignoring ${ROLLED_LOG_INCLUDE_PATTERN.key} because the version of YARN " +
"does not support it", e)
}
}
appContext.setUnmanagedAM(isClientUnmanagedAMEnabled)
sparkConf.get(APPLICATION_PRIORITY).foreach { appPriority =>
appContext.setPriority(Priority.newInstance(appPriority))
}
appContext
}
将其修改为:
sparkConf.get(ROLLED_LOG_INCLUDE_PATTERN).foreach { includePattern =>
try {
val logAggregationContext = Records.newRecord(classOf[LogAggregationContext])
// These two methods were added in Hadoop 2.6.4, so we still need to use reflection to
// avoid compile error when building against Hadoop 2.6.0 ~ 2.6.3.
val setRolledLogsIncludePatternMethod =
logAggregationContext.getClass.getMethod("setRolledLogsIncludePattern", classOf[String])
setRolledLogsIncludePatternMethod.invoke(logAggregationContext, includePattern)
sparkConf.get(ROLLED_LOG_EXCLUDE_PATTERN).foreach { excludePattern =>
val setRolledLogsExcludePatternMethod =
logAggregationContext.getClass.getMethod("setRolledLogsExcludePattern", classOf[String])
setRolledLogsExcludePatternMethod.invoke(logAggregationContext, excludePattern)
}
appContext.setLogAggregationContext(logAggregationContext)
} catch {
case NonFatal(e) =>
logWarning(s"Ignoring ${ROLLED_LOG_INCLUDE_PATTERN.key} because the version of YARN " +
"does not support it", e)
}
}
appContext
}
编译
spark-3.1.2-bin-2.6.0-cdh5.16.2.tgz
口令
p0kd8e
参考资料
源码编译搭建Spark3.x环境
Spark-3.1.1编译流程及踩坑记录