聚类算法之K-means算法与聚类算法衡量指标
原文出处:http://blog.csdn.net/weiyongle1996/article/details/77925325
聚类就是按照某个特定标准(如距离准则)把一个数据集分割成不同的类或簇,使得同一个簇内的数据对象的相似性尽可能大,同时不在同一个簇中的数据对象的差异性也尽可能地大。即聚类后同一类的数据尽可能聚集到一起,不同数据尽量分离。聚类算法属于无监督学习,即事先不会给出标记信息,通过对无标记样本的学习来解释数据的内在性质及规律,为进一步的数据分析提供基础。
一、K-means(k均值)算法
k-means是划分方法中较经典的聚类算法之一。由于该算法的效率高,所以在对大规模数据进行聚类时被广泛应用。目前,许多算法均围绕着该算法进行扩展和改进。
k-means算法以k为参数,把n个样本分成k个簇,使簇内具有较高的相似度,而簇间的相似度较低。k-means算法的处理过程如下:首先,随机地 选择k个样本,每个样本初始地代表了一个簇的平均值或中心;对剩余的每个样本,根据其与各簇中心的距离,将它赋给最近的簇;然后重新计算每个簇的平均值。 这个过程不断重复,直到准则函数收敛。
算法步骤为:
1、选择初始的k个类别中心u1u2……uk
2、对于每个样本,将其标记为距离类别中心最近的类别,即:
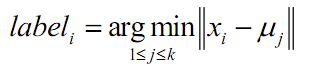
3、将每个类别中心更新为隶属该类别的所有样本的均值
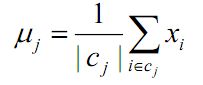
4、重复最后两步,直到类别中心的变化小于某阈值
伪代码如下:

具体k-means算法的执行过程可以参加下图:
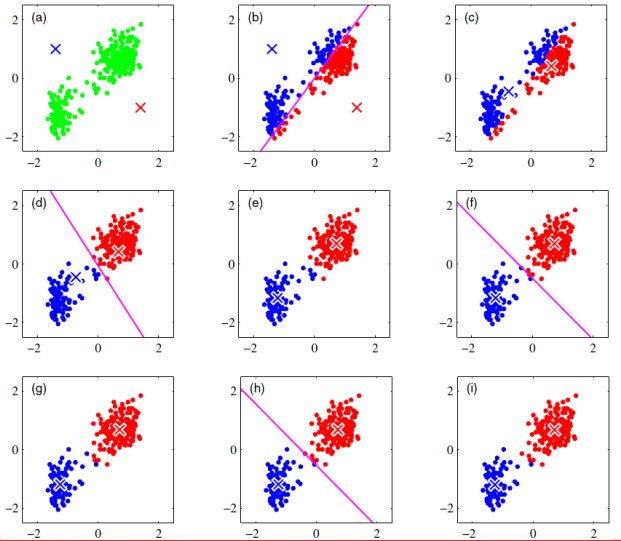
k-means算法的问题:K-means算法是将簇中左右点的均值做为新的质心,但是当有异常值是,质心可能就会离大多数点比较远。比如1,2,3,4,100五个样本,均值是22,这样类别中心就离样本较远,这时选取中位数做为质心是更好的选择,这就是k-Mediods(k-中值)聚类算法。同时k-means是初值敏感的,即当选取不同的初始值时分类结果可能不同,如下图:
K-means算法公式化解释
记k个簇中心分别为u1,u2,u3……uk,每个簇的样本数目为N1、N2……Nk。
使用平方误差做为误差函数,得:
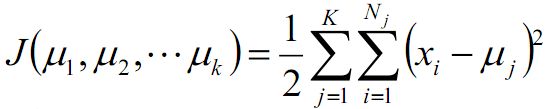
将该函数做为目标函数,求解该函数的最小值。可以使用梯度下降法求,该函数为凸函数,驻点为:

可以看到,要想使损失函数最小,聚类中心要为各簇中样本点的平均值。由此可以看出,K-means算法在每次迭代更新时使用各簇中样本点的平均值为聚类中心是有道理的。
K-means聚类方法总结
优点:
1、解决聚类问题的经典算法,简单、快速
2、当处理大数据集时,该算法保持可伸缩性和高效率
3、当簇近似为高斯分布时,它的效果较好
缺点:
1、在簇的平均值可被定义的情况下才能使用,可能不适用于某些应用
2、必须实现给出k(要生成簇的数目),而且对初值敏感,即对于不同的初值,可能会导致不同结果
3、不适合非凸形状的簇或者大小差别很大的簇
4、对噪声和孤立点敏感
二 、Canopy算法
Canopy算法也可以划分为聚类算法,其算法描述如下:

r1为较小的数,当样本xj与样本c的距离小于r1时样本xj只属于以样本c为聚类中心的簇,当样本xj与样本c的距离大于r1小于r2时,样本cj部分属于以样本c为聚类中心的簇。这里部分属于的意思是样本cj即会属于以样本c 为聚类中心的簇,也会属于其他的簇。
算法结束后,每个样本xj对应的列表Cc中的样本c即为其所属的簇中心,以为Cj中的c可能会有多个,所以样本xj可能会属于多个簇。
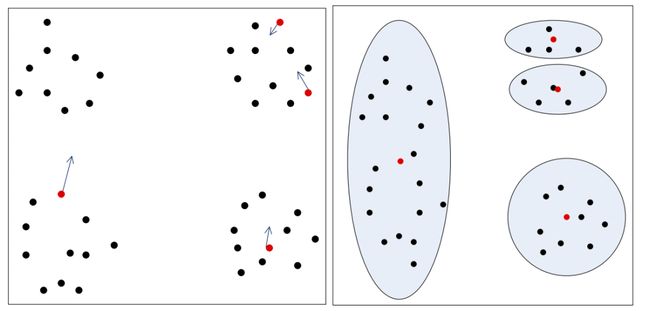
下图是一个聚类后的样本分布图:
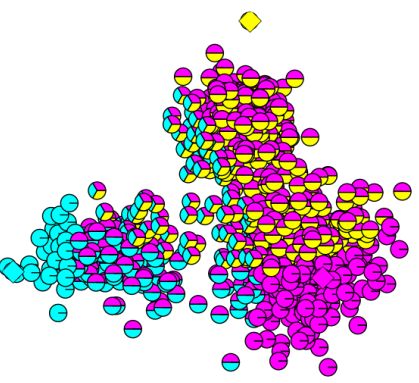
样本点只有一个颜色的表示只属于一个簇,有多个颜色表示属于多个簇。
三、聚类衡量指标
均一性:一个簇只包含一个样本则满足均一性
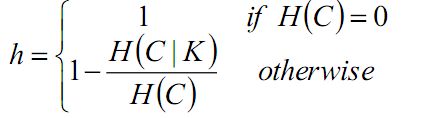
完整性:同类别样本被归到同一个簇中则满足完整性
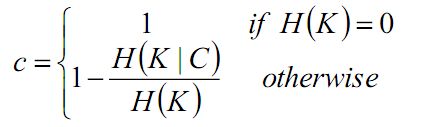
V-measure 均一性和完整性的加权平均:
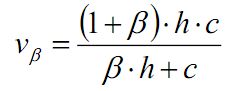
ARI:两个不同的聚类结果之间相似性的度量
数据集S共有N个元素,两个聚类结果分别为X:{X1,X2……Xr},Y:{Y1,Y2,……Ys},X和Y的元素个数分别为:a={a1,a2……ar},b={b1,b2……bs},它们之间关系如下图:

其中nij为即属于Xi有属于Yj的。
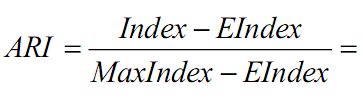
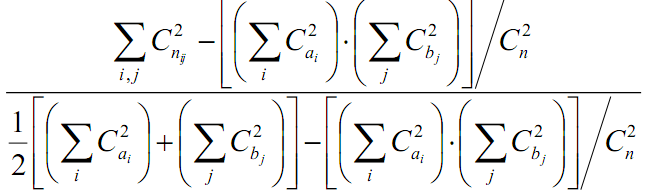
上式的含义为:(指数-期望指数)/(最大的指数-期望指数)
AMI:使用与AMI相同的符号,将上图中的nij看成是随机变量,更具信息熵,则有互信息:
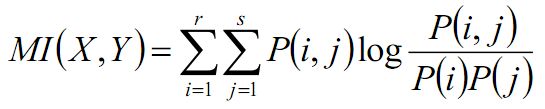
对其进行正则化得正则化互信息:
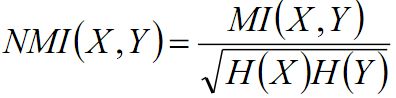
X服从超几何分布,求互信息的期望为:
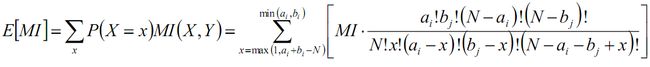
借鉴ARI有:
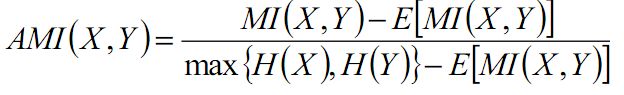
轮廓系数:对聚类结果有效性的解释和验证
首先定义簇内不相似度和簇间不相似度。
簇内不相似度:计算样本i到该簇内其他样本点的平均距离ai,ai越小则聚类结果越好,ai即为该样本的簇内不相似度。该簇内所有样本的ai的均值即为该簇的簇内不相似度。
簇间不相似度:计算样本i到其他簇Cj的所有样本的平均距离bij,成为样本i与簇Cj的簇间不相似度。定义样本i的簇间不相似度为:
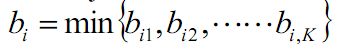
bi越大,说明样本i越不属于其他簇。
下面来看轮廓系数,根据样本的簇内不相似度ai和簇间不相似度bi,定义样本i的轮廓系数如下:
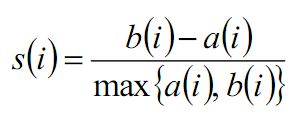
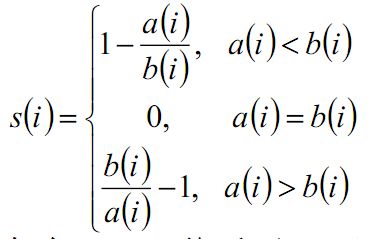
si越接近1说明样本i聚类越合理,越接近-1,则说明样本i更应该被分到另外的簇,近似为0说明在两个簇的边界上。
所有样本的si的均值称为聚类结果的轮廓系数,是该聚类分类是否合理、有效的度量。
参考:
周志华《机器学习》
邹博 机器学习