EM算法理解的九层境界
摘 要 EM算法是一种迭代算法,用于含有隐变量(Hidden Variable)的概率参数模型的最大似然估计或极大后验概率估计。本文将对EM算法从纵向进行九层境界的理解。
关键词 EM算法;K-Means;VBEM;Gibbs
0 引言
EM算法,Expectation Maximization Algorithm。期望最大算法是一种迭代算法,用于含有隐变量(Hidden Variable)的概率参数模型的最大似然估计或极大后验概率估计。本文将对EM算法从纵向进行九层境界的理解。
1 EM就是E+M
第一层境界,EM算法就是E期望+M最大化。
最经典的例子就是抛3个硬币,第一次抛硬币I决定C1和C2,然后抛C1或者C2决定正反面,然后估算3个硬币的正反面概率值。
这个例子之所以经典,是因为它告诉我们,当存在隐变量I的时候,直接的最大似然估计无法直接搞定。什么是隐变量?为什么要引入隐变量?对隐变量的理解是理解EM算法的第一要义。ChuongB Do & Serafim Batzoglou的Tutorial论文“What is the expectation maximization algorithm?”对此有详细的例子进行分析。具体例子如下。
场景:假设有两枚硬币(A,B),两枚硬币中,A朝上概率为 ,B朝上概率为 ,结果向上记为H(head),向下记为T(tail) 。
实验:随机选择其中1枚(我们不知道究竟选的是哪一枚),抛十次,其中选到A和B的概率均为50%;重复五次。最终得到5行10列的一个只包含正反面的结果序列。
目的:根据实验,判断出 和 的值。
因此,这里参数估计的目标参数为 和 ,隐变量为五次实验中,选择的是A还是B。
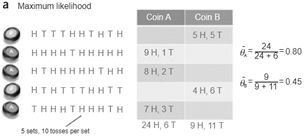
通过隐变量,我们第一次解读了EM算法的伟大,突破了直接MLE(Maximum Likelihood Estimate,极大似然估计)的限制。
至此,EM算法的第一层境界理解结束,只达到看山是山的层面。
2 EM是一种局部下限构造
第二层境界,EM算法是一种局部下限构造。
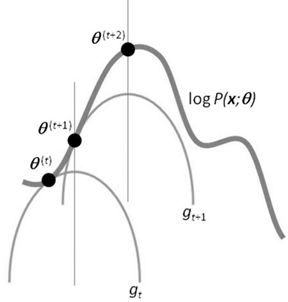
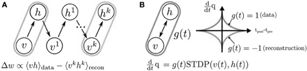
如果我们再深入到基于隐变量的EM算法的收敛性证明,基于log(x)函数的Jensen不等式构造,我们很容易证明,EM算法是在反复的构造新的下限,然后进一步求解。
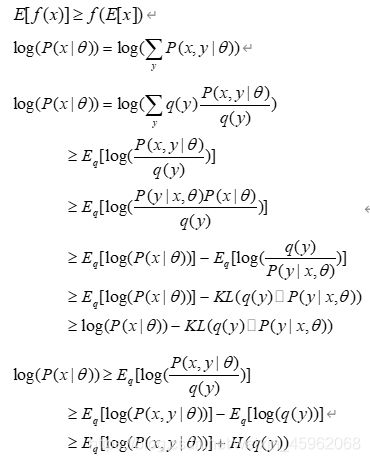
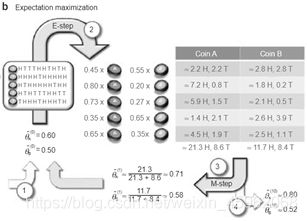
所以,先固定当前参数,计算得到当前隐变量分布的一个下界函数,然后优化这个函数,得到新的参数,然后循环继续。
也正是这个不停地构造下限的思想和VB方法联系起来。如果将上述了解透彻,则进入了理解EM算法的第二层境界,看山看石。
3 K-Means是一种Hard EM算法
第三层境界,K-均值方法是一种Hard EM算法。
在第二层境界的基础上,我们就可以遨游EM算法用到GMM(Gaussian Mixed Model,高斯混合模型)和HMM(Hidden Markov Model,隐含马尔科夫模型)模型中去了。尤其是GMM的深入理解之后,对于有隐变量的联合概率,如果利用高斯分布代入之后:

但是,能不能说K-均值就是高斯分布的EM算法呢?不是, 这里虽然拓展到了相同的距离公式, 但是背后逻辑还是不一样,不一样在哪里呢?K-均值在讨论隐变量的决定时候,用的是dirac delta 分布,这个分布是高斯分布的一种极限。
对其进行更为简单直观的理解,k-均值用的hard EM算法,而我们所说的EM算法是soft EM算法。所谓hard即一种非0即1的是非抉择。而soft是0.7占比的C1,0.3占比的是C2情况。如下图。
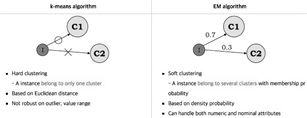
那么充分理解了k-均值和EM算法本身的演化和差异有什么帮助呢?是为了让你进一步理解到隐变量是存在一种分布的。
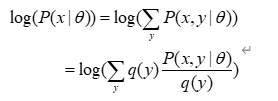
至此,上述为理解EM算法的第三层境界,看山看峰。
4 从EM到广义EM
通过前三层境界,我们对EM算法的理解要跨过隐变量,进入隐分布的境界。如果我们把前面的EM收敛证明稍微重复以下,引入隐分布。
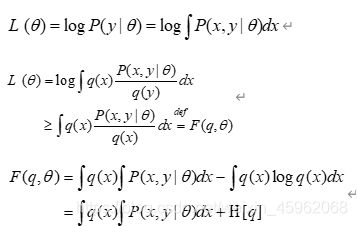
这样我们把Jensen不等式右边的部分定义为自由能。那么E步骤是固定参数优化隐分布,M步骤是固定隐分布优化参数,这就是广义EM算法。
自由能:
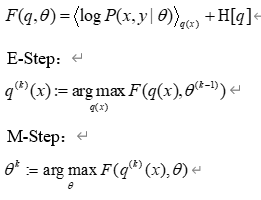
有了广义EM算法之后,我们对自由能深入挖掘, 发现自由能和似然度和KL距离之间的关系:
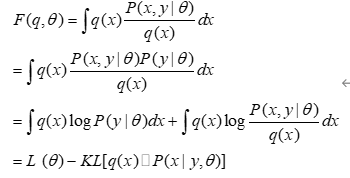
所以固定参数的情况下,那么只能最优化KL距离了,那么隐分布只能取如下分布:
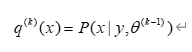
而这个在EM算法里面是直接给出的。所以EM算法是广义EM算法的天然最优的隐分布情况。 但是很多时候隐分布不是那么容易计算的。
前面的推理虽然很简单,但是要理解到位却实属不易,首先要深入理解KL距离是如何被引入的。
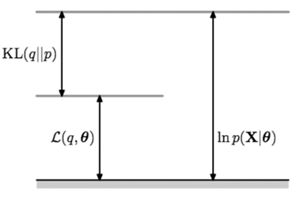
其次要理解,为什么传统的EM算法,而不存在第一个最优化?因为在没有限制的隐分布(天然情况下)情况下, 第一个最优就是要求:
![]()
而这个隐分布, EM算法里面是直接给出的,而不是让你证明得到的。
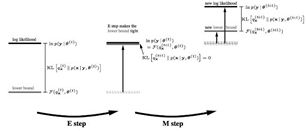
这样,在广义EM算法中,我们看到两个优化步骤,进入了两个优化步骤理解EM算法的境界, 即进入理解EM算法的第四层境界,有水有山
5 广义EM的一个特例是VBEM
在隐分布没有限制的时候,广义EM算法就是EM算法, 但是如果隐分布本身是有限制的呢?譬如有个先验分布的限制,譬如有计算的限制呢?
例如先验分布的限制:从pLSA到LDA就是增加了参数的先验分布。
例如计算上的限制:mean-field计算简化的要求,分量独立。
诸如此类限制,使得广义EM里面的第一步E优化不可能达到无限制最优,所以KL距离无法为0。
基于有限制的理解,再引入模型变分的思想, 根据模型m的变化,对应参数和隐变量都有相应的分布:

如果理解了上述,便进入理解EM算法的第五层境界,水转山回。
6 广义EM的另一个特例是WS算法
Hinton老爷子搞定VBEM算法后,并没有停滞,他在研究DBN和DBM的Fine-Tuning的史讳,提出了Wake-Sleep算法。我们知道在有监督的Fine-Tuning可以使用BP算法,但是无监督的Fine-Tuning,使用的是Wake-Sleep算法。

就是这个WS算法,也是广义EM算法的一种特例。WS算法分为认知阶段和生成阶段。
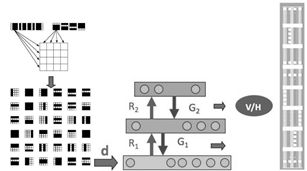
在前面自由能里面,我们将KL距离引入了,这里刚好这两个阶段分别优化了KL距离的两种形态。固定P优化Q,和固定Q优化P。
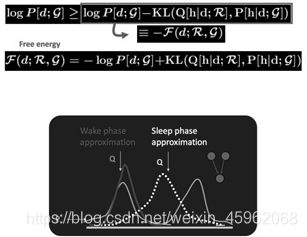
所以当我们取代自由能理解,全部切换到KL距离的理解,广义EM算法的E步骤和M步骤就分别是E投影和M投影。因为要求KL距离最优,可以等价于垂直。而这个投影,可以衍生到数据D的流形空间,和模型M的流形空间。
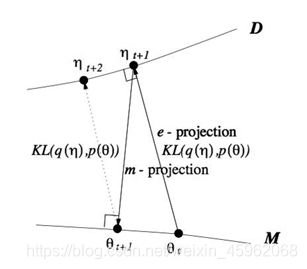
所以你认同WS算法是一种广义EM算法(GEM)之后,基于KL距离再认识GEM算法。引入了数据流形和模型流形。引入了E投影和M投影。
不过要注意的Wake识别阶段对应的是M步骤,而Sleep生成阶段对应的E步骤。所以WS算法对应的是广义ME算法。如果你理解了这个,恭喜你,进入理解EM算法的第六层境界,山高水深。
7 广义EM的再一个特例是Gibbs抽样算法
其实,前面基于KL距离的认知,严格放到信息理论的领域,对于前面E投影和M投影都有严格的定义。M投影的名称是类似的,但是具体是moment projection,但是E投影应该叫I投影,具体是information projection。
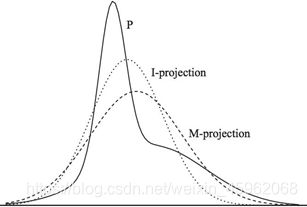
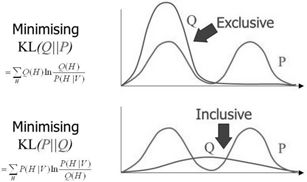
上面这种可能不太容易体会到M投影和I投影的差异,如果再回到最小KL距离,有一个经典的比较。可以体会M投影和I投影的差异。上面是I投影,只覆盖一个峰。下面是M投影,覆盖了两个峰。
当我们不是直接计算KL距离,而是基于蒙特卡洛抽样方法来估计KL距离。
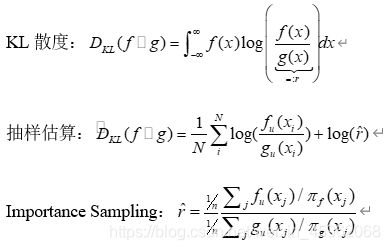
有兴趣对此深入的,可以阅读论文”On Monte Carlo methods for estimating ratios of normalizing constants”
这时候,广义EM算法,就是Gibbs Sampling了。所以Gibbs Sampling,本质上就是采用了蒙特卡洛方法计算的广义EM算法。
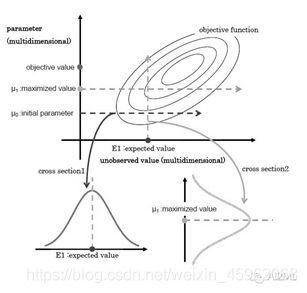
所以,如果把M投影和I投影看成是一个变量上的最小距离点,那么Gibbs Sampling和广义EM算法的收敛过程是一致的。
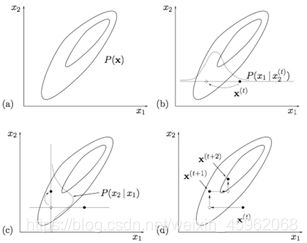
VAE的发明者,Hinton的博士后,Max Welling在论文”Bayesian K-Means as a ‘Maximization-Expectation’ Algorithm”中,对这种关系有如下很好的总结!
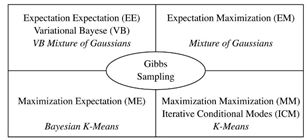
另外,Zoubin Ghahramani, Jordan的博士,在”Factorial Learning and the EM Algorithm”等相关论文也反复提到他们的关系。
这样,通过广义EM算法把Gibbs Sampling和EM,VB,K-Means和WS算法全部联系起来了。有了Gibbs Sampling的背书,你是不是能更好的理解,为什么WS算法可以是ME步骤,而不是EM的步骤呢?另外,我们知道坐标下降Coordinate Descent也可以看成一种Gibbs Sampling过程,如果有人把Coordinate Descent和EM算法联系起来,你还会觉得奇怪么?

现在我们发现VB和Gibbs Sampling都可以放到广义EM的大框架下,只是求解过程一个采用近似逼近,一个采用蒙特卡洛采样。有了EM算法和Gibbs Sampling的关系,现在你理解,为什么Hinton能够发明CD算法了么?细节就不展开了。
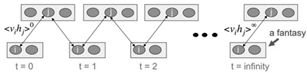
如果你理解了这个,恭喜你,进入理解EM算法的第七层境界,山水轮回。
8 WS算法是VAE和GAN组合的简化版
Jordan的弟子邢波老师,他的学生胡志挺,发表了一篇文章,On Unifying Deep Generative Models,试图通过WS算法,统一对VAE和GAN的理解。
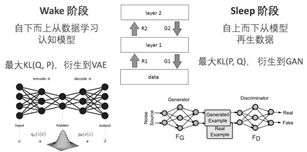
对VAE的理解,变了加了正则化的KL举例,而对于GAN的理解变成了加Jensen-Shannon散度。所以,当我们把广义EM算法的自由能,在WS算法中看成KL散度,现在看成扩展的KL散度。对于正则化扩展,有很多类似论文,”Mode Regularized Generative Adversarial Networks”, “Stabilizing Training of Generative Adversarial Networks through Regularization”有兴趣可以读读。
所以对于VAE,类比WS算法的Wake认知阶段,不同的是在ELBO这个VBEM目标上基础上加了KL散度作为正则化限制。再应用再参数化技巧实现了VAE。

而对应到GAN,类比Sleep阶段,正则化限制了换JSD距离,然后目标KL距离也随着不同GAN的变体也可以变化。
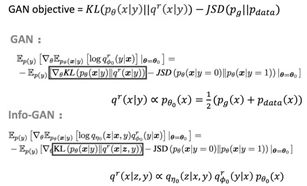
所以,VAE和GAN都可以理解为有特殊正则化限制的Wake-Sleep步骤,那么组合起来也并不奇怪。
这就是为什么那么多论文研究如何组合VAE/GAN到同一个框架下面去。目前对这方面的理解还在广泛探讨中。
如果你理解了这个,恭喜你,进入理解EM算法的第八层境界,水中有水、山外有山。
9 KL距离的统一
Jordan大佬的一篇论文,开启了KL距离的同意, “On surrogate loss functions and f-divergences”。里面对于所谓的正反KL距离全部统一到散度的框架下面。Jordan首先论述了对于损失函数统一的Margin理论的意义。
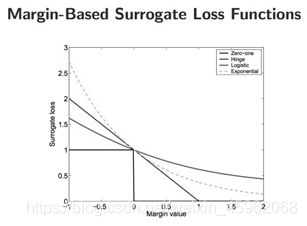
然后把这些损失函数也映射到f散度:
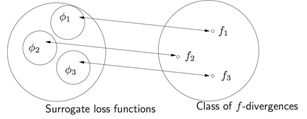
然后微软的Sebastian Nowozin,把f-散度扩展到GAN “f-GAN:Training Generative Neural Samplers using Variational Divergence Minimization”。

然后对正反KL散度也做了一次统一。
对于f-散度的理解离不开对Fenchel对偶的理解。
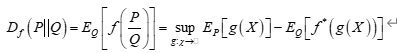
除了f-散度,还有人基于bregman散度去同意正反KL散度的认知。KL散度就是香农熵的bregman散度。
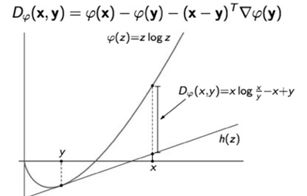
而Bregman散度本身是基于一阶泰勒展开的一种偏离度的度量。
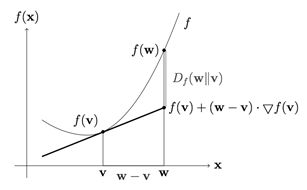
然后再基于Bregman举例去研究最小KL投影,函数空间采用香农熵。

无论f-散度还是bregman散度对正反KL距离的统一,之后的广义EM算法,都会变得空间的最优投影的交替出现。或许广义EM算法也成了不同流形空间上的坐标梯度下降算法而已coodinate descent。
如果你理解了这个,恭喜你,进入理解EM算法的第九层境界,山水合一。
10 KL距离的统一
这里浅薄的介绍了理解EM算法的9层境界,托名Hinton和Jordan,着实是因为佩服他们俩对此必定会有更为深刻的理解,很好奇会到何种程度。。。最后依然好奇,为啥只有他们两家的子弟能够不停的突破无监督深度学习?Hinton老仙说,机器学习的未来在于无监督学习!
欢迎大家加我微信学习讨论
