全连接神经网络学习MNIST实现手写数字识别
神经网络的学习步骤
神经网络的学习分成下面4个步骤:
步骤1(mini-batch)
从训练数据中随机选出一部分数据,这部分数据称为mini-batch。我们的目标是减小mini-batch的损失函数的值。
步骤2(计算梯度)
为了减小mini-batch的损失函数的值,需要求出各个权重参数的梯度。梯度表示损失函数的值减小最多的方向。
步骤3(更新参数)
将权重参数沿梯度方向进行微小更新。
步骤4(重复)
重复步骤1、步骤2、步骤3。
神经网络的学习按照上面4个步骤进行。这个方法通过梯度下降法更新参数,不过因为这里使用的数据是随机选择的mini batch数据,所以又称为随机梯度下降法(stochastic gradient descent)。“随机”指的是“随机选择的”的意思,因此,随机梯度下降法是“对随机选择的数据进行的梯度下降法”。我们这里以2层神经网络(隐藏层为1层的网络)为对象,使用MNIST数据集进行学习。
2层神经网络的类
首先初始化权重,初始化两层权重和偏置。params[‘W1’]是第1层的权重,params[‘b1’]是第1层的偏置。params[‘W2’]是第2层的权重,params[‘b2’]是第2层的偏置。
def __init__(self, input_size, hidden_size, output_size, weight_init_std=0.01):
# 初始化权重
self.params = {'W1': weight_init_std * np.random.randn(input_size, hidden_size), 'b1': np.zeros(hidden_size),
'W2': weight_init_std * np.random.randn(hidden_size, output_size), 'b2': np.zeros(output_size)}
接下来进行推理(识别),sigmoid是第一层的激活函数,softmax是输出层的激活函数。如果需要设置多层神经网络就多初始化几层权重和偏置,这里多加几层推理(识别)。
def predict(self, x):
W1, W2 = self.params['W1'], self.params['W2']
b1, b2 = self.params['b1'], self.params['b2']
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
y = softmax(a2)
return y
损失函数,梯度,识别精度不过多介绍。训练完成后保存训练参数,以及测试泛化能力读取训练参数。
def save_params(self, file_name="params.pkl"):
params = {}
for key, val in self.params.items():
params[key] = val
with open(file_name, 'wb') as f:
pickle.dump(params, f)
def load_params(self, file_name="params.pkl"):
with open(file_name, 'rb') as f:
params = pickle.load(f)
for key, val in params.items():
self.params[key] = val
完整实现如下:
# coding: utf-8
import pickle
import sys, os
sys.path.append(os.pardir) # 为了导入父目录的文件而进行的设定
from common.functions import *
from common.gradient import numerical_gradient
class TwoLayerNet:
def __init__(self, input_size, hidden_size, output_size, weight_init_std=0.01):
# 初始化权重
self.params = {'W1': weight_init_std * np.random.randn(input_size, hidden_size), 'b1': np.zeros(hidden_size),
'W2': weight_init_std * np.random.randn(hidden_size, output_size), 'b2': np.zeros(output_size)}
def predict(self, x):
W1, W2 = self.params['W1'], self.params['W2']
b1, b2 = self.params['b1'], self.params['b2']
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
y = softmax(a2)
return y
# x:输入数据, t:监督数据
def loss(self, x, t):
y = self.predict(x)
return cross_entropy_error(y, t)
def accuracy(self, x, t):
y = self.predict(x)
y = np.argmax(y, axis=1)
t = np.argmax(t, axis=1)
accuracy = np.sum(y == t) / float(x.shape[0])
return accuracy
# x:输入数据, t:监督数据
def numerical_gradient(self, x, t):
loss_W = lambda W: self.loss(x, t)
grads = {'W1': numerical_gradient(loss_W, self.params['W1']),
'b1': numerical_gradient(loss_W, self.params['b1']),
'W2': numerical_gradient(loss_W, self.params['W2']),
'b2': numerical_gradient(loss_W, self.params['b2'])}
return grads
def gradient(self, x, t):
W1, W2 = self.params['W1'], self.params['W2']
b1, b2 = self.params['b1'], self.params['b2']
grads = {}
batch_num = x.shape[0]
# forward
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
y = softmax(a2)
# backward
dy = (y - t) / batch_num
grads['W2'] = np.dot(z1.T, dy)
grads['b2'] = np.sum(dy, axis=0)
da1 = np.dot(dy, W2.T)
dz1 = sigmoid_grad(a1) * da1
grads['W1'] = np.dot(x.T, dz1)
grads['b1'] = np.sum(dz1, axis=0)
return grads
def save_params(self, file_name="params.pkl"):
params = {}
for key, val in self.params.items():
params[key] = val
with open(file_name, 'wb') as f:
pickle.dump(params, f)
def load_params(self, file_name="params.pkl"):
with open(file_name, 'rb') as f:
params = pickle.load(f)
for key, val in params.items():
self.params[key] = val
学习MNIST
从训练数据中随机选出一部分数据,求出各个权重参数的梯度,梯度表示损失函数的值减小最多的方向,将权重参数沿梯度方向进行微小更新,重复这个过程。神经网络学习的最初目标是掌握泛化能力,因此,要评价神经网络的泛化能力,就必须使用不包含在训练数据中的数据。在进行学习的过程中,会定期地对训练数据和测试数据记录识别精度。这里,每经过一个epoch,我们都会记录下训练数据和测试数据的识别精度。细思极恐,这只有两层神经网络,识别率到了0.94。
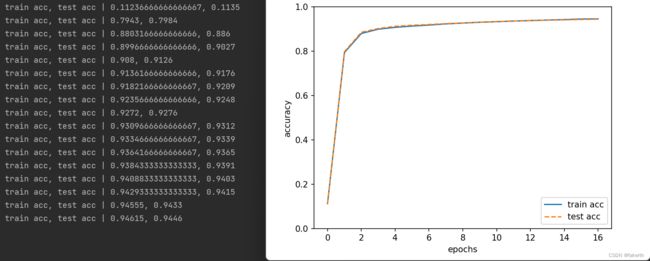
学习代码如下:
# coding: utf-8
import os
import sys
sys.path.append(os.pardir) # 为了导入父目录的文件而进行的设定
import numpy as np
import matplotlib.pyplot as plt
from dataset.mnist import load_mnist
from two_layer_net import TwoLayerNet
# 读入数据
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label=True)
network = TwoLayerNet(input_size=784, hidden_size=50, output_size=10)
iters_num = 10000 # 适当设定循环的次数
train_size = x_train.shape[0]
batch_size = 100
learning_rate = 0.1
train_loss_list = []
train_acc_list = []
test_acc_list = []
iter_per_epoch = max(train_size / batch_size, 1)
for i in range(iters_num):
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
# 计算梯度
# grad = network.numerical_gradient(x_batch, t_batch)
grad = network.gradient(x_batch, t_batch)
# 更新参数
for key in ('W1', 'b1', 'W2', 'b2'):
network.params[key] -= learning_rate * grad[key]
loss = network.loss(x_batch, t_batch)
train_loss_list.append(loss)
if i % iter_per_epoch == 0:
train_acc = network.accuracy(x_train, t_train)
test_acc = network.accuracy(x_test, t_test)
train_acc_list.append(train_acc)
test_acc_list.append(test_acc)
print("train acc, test acc | " + str(train_acc) + ", " + str(test_acc))
# 保存参数
network.save_params("params.pkl")
print("Saved Network Parameters!")
# 绘制图形
markers = {'train': 'o', 'test': 's'}
x = np.arange(len(train_acc_list))
plt.plot(x, train_acc_list, label='train acc')
plt.plot(x, test_acc_list, label='test acc', linestyle='--')
plt.xlabel("epochs")
plt.ylabel("accuracy")
plt.ylim(0, 1.0)
plt.legend(loc='lower right')
plt.show()
测试泛化能力
训练好的参数总得拿出来用一用吧,对于mnist测试数据和训练数据直接导入参数文件,推理(识别)就行了。
def train_img():
(x_train, t_train), (x_test, t_test) = load_mnist(flatten=True, normalize=False)
network = TwoLayerNet(input_size=784, hidden_size=50, output_size=10)
network.load_params("params.pkl")
img = x_train[2]
label = t_train[2]
a = network.predict(img)
ans = np.argmax(np.array(a))
print("训练集图片预测值:", ans, "标签值:", label)
# img = img.reshape(28, 28) # 把图像的形状变为原来的尺寸
# img_show(img) # 显示图像
def test_img():
(x_train, t_train), (x_test, t_test) = load_mnist(flatten=True, normalize=False)
network = TwoLayerNet(input_size=784, hidden_size=50, output_size=10)
network.load_params("params.pkl")
img = x_test[2]
label = t_test[2]
a = network.predict(img)
ans = np.argmax(np.array(a))
print("测试集图片预测值:", ans, "标签值:", label)
# img = img.reshape(28, 28) # 把图像的形状变为原来的尺寸
# img_show(img) # 显示图像
为什么不测试一下自己手写的呢?自己手写了10个数字。

对于自己手写的图片要进行处理。首先从RBG和BGR颜色空间转换到灰度空间;然后利用阈值,根据设定的值处理图像的灰度值去除背景;再然后,腐蚀毛刺;再利用阈值,根据设定的值处理图像的灰度值实现黑白反转(我们手写的数字是黑的,而训练用的黑色背景白色字体);最后缩小成28*28。因为我很少接触过图像处理,凭感觉觉得最后缩小图片比开始缩小图片处理的效果好。
def else_img(filename, img_width, img_height, threshold, kernel_size): # 测试模型的泛化能力
network = TwoLayerNet(input_size=784, hidden_size=50, output_size=10)
network.load_params("params.pkl")
img_original = cv2.imread(filename)
# img_show(img_original)
# img = cv2.resize(img_original, (img_width, img_width), fx=1, fy=1) # 图片缩放 1:1缩放
img_gray = cv2.cvtColor(img_original, cv2.COLOR_BGR2GRAY) # 从RBG和BGR颜色空间转换到灰度空间
# img_show(img_gray)
ret, thresh2 = cv2.threshold(img_gray, threshold, 255, cv2.THRESH_BINARY) # 像素值>threshold设为255 其他0
# 阈值的作用是根据设定的值处理图像的灰度值,比如灰度大于某个数值像素点保留。通过阈值以及有关算法可以实现从图像中抓取特定的图形,比如去除背景等。
# img_show(thresh2)
kernel = np.ones(kernel_size, np.uint8)
thresh2 = cv2.erode(thresh2, kernel, iterations=1)
# img_show(thresh2)
# 腐蚀毛刺 膨胀用来处理缺陷问题; 腐蚀用来处理毛刺问题
ret, thresh2 = cv2.threshold(thresh2, threshold, 255, cv2.THRESH_BINARY_INV) # 像素值>threshold设为0 其他255
# img_show(thresh2)
thresh2 = cv2.resize(thresh2, (img_width, img_width), fx=1, fy=1) # 图片缩放 1:1缩放
thresh2 = thresh2.reshape(1, img_width * img_width)
network.load_params("params.pkl")
a = network.predict(thresh2)
label = np.argmax(np.array(a))
return label
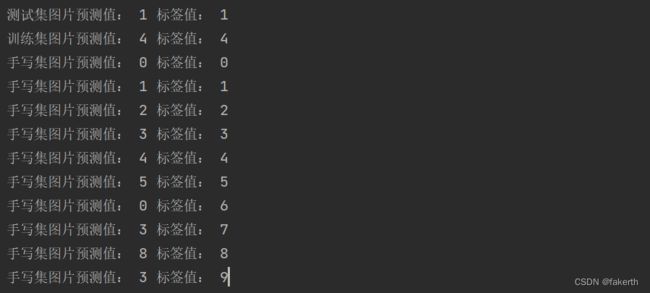
最后的识别结果如下,手写的10个数字错了3个,图像处理的问题应该也占了一部分原因。
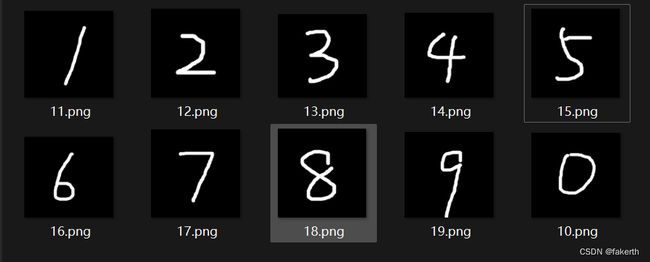
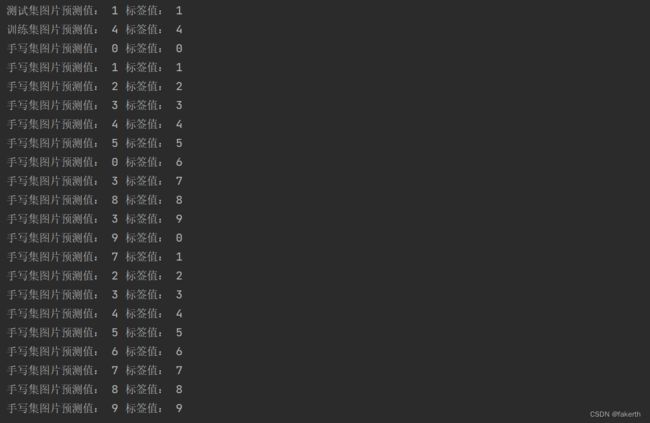
改用这10个数字试一下,手写的10个数字错了2个,而且是易混的错。9和0,1和7,毕竟只有两层,这种效果很可以了。
完整程序实现如下:
import cv2
import numpy as np
# coding: utf-8
import os
import sys
sys.path.append(os.pardir) # 为了导入父目录的文件而进行的设定
import numpy as np
from dataset.mnist import load_mnist
from PIL import Image
from two_layer_net import TwoLayerNet
def img_show(img):
pil_img = Image.fromarray(np.uint8(img))
pil_img.show()
def train_img():
(x_train, t_train), (x_test, t_test) = load_mnist(flatten=True, normalize=False)
network = TwoLayerNet(input_size=784, hidden_size=50, output_size=10)
network.load_params("params.pkl")
img = x_train[2]
label = t_train[2]
a = network.predict(img)
ans = np.argmax(np.array(a))
print("训练集图片预测值:", ans, "标签值:", label)
# img = img.reshape(28, 28) # 把图像的形状变为原来的尺寸
# img_show(img) # 显示图像
def test_img():
(x_train, t_train), (x_test, t_test) = load_mnist(flatten=True, normalize=False)
network = TwoLayerNet(input_size=784, hidden_size=50, output_size=10)
network.load_params("params.pkl")
img = x_test[2]
label = t_test[2]
a = network.predict(img)
ans = np.argmax(np.array(a))
print("测试集图片预测值:", ans, "标签值:", label)
# img = img.reshape(28, 28) # 把图像的形状变为原来的尺寸
# img_show(img) # 显示图像
def else_img(filename, img_width, img_height, threshold, kernel_size): # 测试模型的泛化能力
network = TwoLayerNet(input_size=784, hidden_size=50, output_size=10)
network.load_params("params.pkl")
img_original = cv2.imread(filename)
# img_show(img_original)
# img = cv2.resize(img_original, (img_width, img_width), fx=1, fy=1) # 图片缩放 1:1缩放
img_gray = cv2.cvtColor(img_original, cv2.COLOR_BGR2GRAY) # 从RBG和BGR颜色空间转换到灰度空间
# img_show(img_gray)
ret, thresh2 = cv2.threshold(img_gray, threshold, 255, cv2.THRESH_BINARY) # 像素值>threshold设为255 其他0
# 阈值的作用是根据设定的值处理图像的灰度值,比如灰度大于某个数值像素点保留。通过阈值以及有关算法可以实现从图像中抓取特定的图形,比如去除背景等。
# img_show(thresh2)
kernel = np.ones(kernel_size, np.uint8)
thresh2 = cv2.erode(thresh2, kernel, iterations=1)
# img_show(thresh2)
# 腐蚀毛刺 膨胀用来处理缺陷问题; 腐蚀用来处理毛刺问题
ret, thresh2 = cv2.threshold(thresh2, threshold, 255, cv2.THRESH_BINARY_INV) # 像素值>threshold设为0 其他255
# img_show(thresh2)
thresh2 = cv2.resize(thresh2, (img_width, img_width), fx=1, fy=1) # 图片缩放 1:1缩放
thresh2 = thresh2.reshape(1, img_width * img_width)
a = network.predict(thresh2)
label = np.argmax(np.array(a))
return label
def deal_img2(filename):
img = cv2.imread(filename)
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 从RBG和BGR颜色空间转换到灰度空间
thresh2 = cv2.resize(img_gray, (28, 28), fx=1, fy=1) # 图片缩放 1:1缩放
thresh2 = thresh2.reshape(1, 28 * 28)
return thresh2
def else_img2(filename):
network = TwoLayerNet(input_size=784, hidden_size=50, output_size=10)
network.load_params("params.pkl")
img_out = deal_img2(filename)
a = network.predict(img_out)
label = np.argmax(np.array(a))
return label
test_img()
train_img()
t = np.arange(10)
x = ["0.png", "1.png", "2.png", "3.png", "4.png", "5.png", "6.png", "7.png", "8.png", "9.png"]
x1 = ["10.png", "11.png", "12.png", "13.png", "14.png", "15.png", "16.png", "17.png", "18.png", "19.png"]
for i in range(0, 10):
print("手写集图片预测值:", else_img(x[i], 28, 28, 127, (3, 3)), "标签值:", t[i])
for i in range(0, 10):
print("手写集图片预测值:", else_img2(x1[i]), "标签值:", t[i])