CV入门(1)——权重初始化
Reference
神经网络中的权重初始化:从基础到 Kaiming 的旅程(强烈推荐)
Go
最近学习到了stylegan中的EqualConv2d卷积操作,实在无法理解其中为什么对参数w增添了一个放缩系数scale。故各种找资料想要理解这么做的目的。然后就翻到了参考中的文章,让我眼前一新,以前只是知道网络模型需要初始化,但完全没法理解为什么?现在,让我们重新认识一些,本文主要是对reference的总结与复现。
1. 首先——为什么需要初始化权重
权重初始化的目的是防止层激活输出在通过深度神经网络的前向传播过程中爆炸或者消失。以上任何一种情况发生都不利于梯度的传播,如果损失梯度太小,网络就需要更长的时间来收敛,如果损失梯度太大,网络就可能直接崩溃。
矩阵乘法是神经网络的基本数学运算,我们使用最基础的神经网络模拟一个多层深度神经网络,为了进一步简化网络结构,我们首先不加入激活函数,仅仅只是通过单纯的矩阵运算。
我们假设我们有一个包含一些网络输入的向量x,一般来说,我们的输入向量需要落在平均值为0,标准差为1的正态分布内。
x = torch.randn(512)
此外,我们假设我们的输入经过了100层的简单网络,每一层都包含一个权重矩阵a。为了完成单次前向传递,我们需要执行100次连续的矩阵乘法。
for i in range(100):
a = torch.randn(512, 512)
x = a @ x
print(x.mean(),x.std())
(tensor(nan),tensor(nan))
事实证明,我们将输入和权重都缩放到标准的正太分布下不是一个好主意。在这100层矩阵乘法的某个地方,层输入变得十分大,计算机直接识别成nan了,为了确切的了解,多少层开始,矩阵大小就已经变得无法计算了。
import torch
x = torch.randn(512)
for i in range(100):
a = torch.randn(512, 512)
x = a @ x
if torch.isnan(x.std()):
print(i)
break
print(x.mean(),x.std())
27
tensor(nan) tensor(nan)
我们看到,在第28层矩阵运算的时候,输出已经无法计算。因此,我们应该明白我们的初始化权重太大。
此外,我们还需要担心输出消失,也就是梯度消失。为了了解梯度消失,我们可以将我们的简略网络的初始权重设置很小。比如平均值是0,标准差是0.01。
import torch
x = torch.randn(512)
for i in range(100):
a = torch.randn(512, 512) * 0.01
x = a @ x
print(x.mean(),x.std())
tensor(0.) tensor(0.)
我们可以发现,当初始化权重比较小的时候,输出开始全部变成0,梯度消失。
综上所述,如果权重初始化太大,网络会发生梯度爆炸,当权重初始化过小,网络会发生梯度消失。
2. 那么我们如何找到最佳初始化
请记住,如上所述,完成神经网络前向传递所需的数学运算只需要一系列矩阵乘法。如果我们的输出y是输入向量x和权重矩阵a之间的矩阵乘积,则y中的每个元素i定义为 y i = ∑ k = 0 n − 1 a i , k x k y_{i}=\sum_{k=0}^{n-1} a_{i, k} x_{k} yi=k=0∑n−1ai,kxk其中i是权重矩阵a的给定行索引,k是权重矩阵a中的给定列索引,又是输入向量x中的元素索引,n是x中元素的范围或总数。
y[i]=sum([c * d for c,d in zip(a[i], x])
我们可以证明,在给定的层,我们从标准正态分布初始化的输入x和权重矩阵a的矩阵乘积,平均而言,标准偏差非常接近输入通道的平方根,在这个例子中是 512 \sqrt{512} 512
import math
import torch
mean = 0.
var = 0.
for i in range(10000):
x = torch.randn(512)
a = torch.randn(512, 512)
y = a @ x
mean += y.mean().item()
var += y.pow(2).mean().item()
print(mean/10000, math.sqrt(var/10000))
print('sqrt512:',math.sqrt(512))
-0.002526797866821289 22.61723591646642
sqrt512: 22.627416997969522
如果我们根据矩阵乘法的定义来看待这个属性,这并不奇怪:为了计算y,我们将输入x的一列元素与权重a的一行的元素相乘的512个乘积累加。其中,x服从标准正态分布,a服从标准正态分布,且互相独立。
对于a中的点与x中点相乘,可以粗略看完两个正态分布相乘。
对于两个独立的正态分布相乘。
令 X ∼ N ( μ 1 , σ 1 2 ) , Y ∼ N ( μ 2 , σ 2 2 ) 令 X \sim N\left(\mu_{1}, \sigma_{1}^{2}\right), Y \sim N\left(\mu_{2}, \sigma_{2}^{2}\right) 令X∼N(μ1,σ12),Y∼N(μ2,σ22), X, Y 独立.
var ( X Y ) = E [ ( X Y ) 2 ] − ( E [ X Y ] ) 2 = E [ X 2 Y 2 ] − ( E [ X Y ] ) 2 \operatorname{var}(X Y)=E\left[(X Y)^{2}\right]-(E[X Y])^{2}=E\left[X^{2} Y^{2}\right]-(E[X Y])^{2} var(XY)=E[(XY)2]−(E[XY])2=E[X2Y2]−(E[XY])2
然后就容易了, E [ X 2 ] = μ 1 2 + σ 1 2 , E [ Y 2 ] = μ 2 2 + σ 2 2 E\left[X^{2}\right]=\mu_{1}^{2}+\sigma_{1}^{2}, E\left[Y^{2}\right]=\mu_{2}^{2}+\sigma_{2}^{2} E[X2]=μ12+σ12,E[Y2]=μ22+σ22
代进去, var ( X Y ) = ( μ 1 2 + σ 1 2 ) ( μ 2 2 + σ 2 2 ) − ( μ 1 μ 2 ) 2 \operatorname{var}(X Y)=\left(\mu_{1}^{2}+\sigma_{1}^{2}\right)\left(\mu_{2}^{2}+\sigma_{2}^{2}\right)-\left(\mu_{1} \mu_{2}\right)^{2} var(XY)=(μ12+σ12)(μ22+σ22)−(μ1μ2)2
本文全部是标准正态分布, μ = 0 , σ = 1 \mu=0,\sigma=1 μ=0,σ=1,所以每个点还是服从标准正态分布,但是我们最终要求这512个点的和,512个点都服从标准正态分布,按照上述公式,同样的推,可得
E ( X + Y ) = μ 1 + μ 2 E(X+Y)=\mu_1+\mu_2 E(X+Y)=μ1+μ2 var ( X + Y ) = σ 1 + σ 2 \operatorname{var}(X +Y)=\sigma_{1}+\sigma_{2} var(X+Y)=σ1+σ2
则512个标准正态分布相加,点集就服从 ( 0 , 512 2 ) (0,\sqrt{512}^2) (0,5122)
也就是说,当我们进行了一次矩阵运算之后,输出就已经服从 ( 0 , 512 2 ) (0,\sqrt{512}^2) (0,5122)的正态分布了,当这样的矩阵运算多来几次,输出的分布就已经开始变得巨大。就导致了上述示例中,在27层矩阵乘法运算之后,梯度爆炸的产生,同理,当输出的分布小于 ( 0 , 1 ) (0,1) (0,1)分布,经过多层矩阵运算之后,梯度会消失。
然而,我们的期望是什么,我们希望网咯的输出分布还是能够保持在正态分布中,那么,在这100层矩阵乘法中,我们怎么保证我们的输出最终还是符合标准正态分布勒?很显然,我们只需要将我们的权重按 1 / 512 1/\sqrt{512} 1/512缩放就好。
import math
import torch
mean = 0.
var = 0.
for i in range(10000):
x = torch.randn(512)
a = torch.randn(512, 512) / math.sqrt(512)
y = a @ x
mean += y.mean().item()
var += y.pow(2).mean().item()
print(mean/10000, math.sqrt(var/10000))
-0.0007218372397474013 0.9998939706858075
让我们再次运行我们的100层简略网络。
import math
import torch
x = torch.randn(512)
for i in range(100):
a = torch.randn(512, 512) / math.sqrt(512)
x = a @ x
print(x.mean(), x.std())
tensor(0.0217) tensor(0.9125)
可以发现,我们的经过100层矩阵运算之后的层输出服从的分布还是接近标准正态分布,因此消灭了梯度爆炸和梯度消失。
到此,我们的初步网络已经可以手工了,但是在现实中,我们真正使用神经网络的时候,我们还需要应用到激活函数,从而达到非线性的映射关系。也得益于非线性激活函数放置在网络层的尾部,深度神经网络能够创建描述现实世界现象的复杂函数的近似值,从而得到惊人的结果。
3. Xavier 初始化
神经网络初期阶段,最常用的激活函数都是关于给定值对称的,并且具有渐进接近于该点中点正负一定距离的值的范围。tanh()和softsign()就是这样的函数。
import numpy as np
import torch
import matplotlib.pyplot as plt
import mpl_toolkits.axisartist as axisartist
# 创建一个画板
fig = plt.figure('activate', (10,8))
ax = axisartist.Subplot(fig, 1,1,1)
fig.add_axes(ax)
ax.axis[:].set_visible(False)
ax.axis["x"] = ax.new_floating_axis(0, 0)
ax.axis["y"] = ax.new_floating_axis(1, 0)
#新建可移动的坐标轴
ax.axis["x"].set_axis_direction('top')
ax.axis["y"].set_axis_direction('left')
x = torch.arange(-10, 10, 0.01)
y_t = torch.tanh(x)
y_s = torch.nn.functional.softsign(x)
plt.xticks(torch.arange(-10, 11, 2))
plt.yticks(torch.arange(-1,1,0.25))
plt.scatter(x, y_t)
plt.scatter(x, y_s)
plt.legend(labels=('softsign', 'tanh'), loc='upper left', prop = {'size':16})
plt.show()
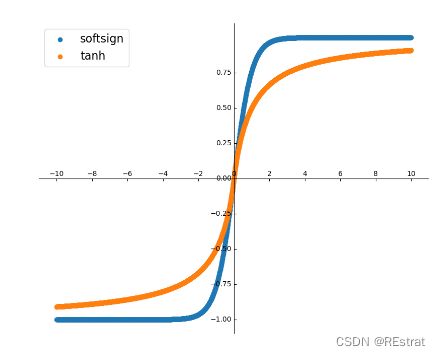
让我们为我们的100层简略网络添加一个激活函数,假设我们使用双正切激活函数tanh,其中层权重,我们依然保持 1 / n 1/\sqrt{n} 1/n的缩放。
import math
import numpy as np
import torch
import matplotlib.pyplot as plt
import mpl_toolkits.axisartist as axisartist
x = torch.randn(512)
for i in range(100):
a = torch.randn(512, 512) / math.sqrt(512)
x = a @ x
x = torch.tanh(x)
print(x.mean(), x.std())
tensor(-0.0015) tensor(0.0836)
你可以发现,此时输出的方差已经变得很小了,如果继续下去,我们的梯度就会消失。
事实上,在大概2010年,传统的初始化权重还不是我们刚才举的那个例子,比较常用的初始化是从[-1,1] 采样和然后按 1/√ n缩放。
事实证明,这种标准方法实际上没有那么好用。
import math
import numpy as np
import torch
import matplotlib.pyplot as plt
import mpl_toolkits.axisartist as axisartist
x = torch.randn(512)
for i in range(100):
a = torch.Tensor(512, 512).uniform_(-1, 1) * math.sqrt(1.0/512)
x = a @ x
x = torch.tanh(x)
print(x.mean(), x.std())
tensor(2.8467e-26) tensor(1.8184e-24)
你会发现它的表现甚至还不如我们刚才提出的初始化权重,梯度基本已经消失。
这种糟糕的性能促进了Xavier Glorot 和 Yoshua Bengio 发表了他们具有里程碑意义的论文Understanding the difficulty of training deep feedforward neural networks,,
他们在论文中将其称为”标准初始化“,现在通常称为”Xavier“初始化。
Xavier初始化将层的权重设置为从介于传入网络通道和输出通道两者之间的随机均匀分布中选择的值。
± 6 n i + n i + 1 \pm \frac{\sqrt{6}}{\sqrt{n_{i}+n_{i+1}}} ±ni+ni+16
Glorot和Bengio认为Xavier权重初始化将保持激活的方差和方向传播的梯度一直保持相近的向上或向下的梯度传播。在他们的实验中,他们观察到Xavier初始化使5层网络能够保持其跨层权重梯度的几乎相同的方差。
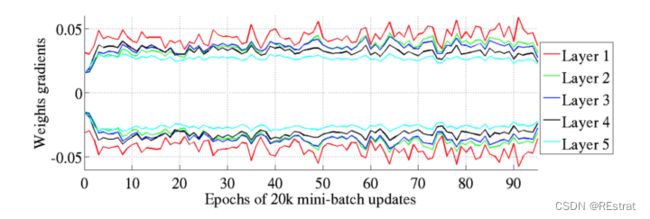
相反,实验证明,使用均值初始化会使网络较高层的梯度接近于0。
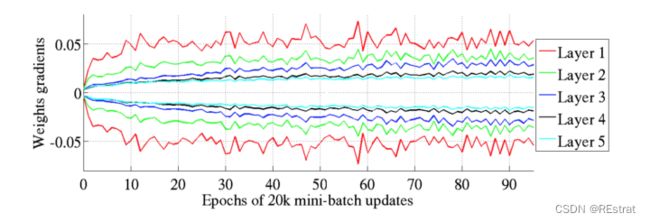
让我们使用Xavier初始化,再次运行我们的100层tanh网络,
def xavier(in_channels, out_channels):
return torch.Tensor(in_channels,out_channels).uniform_(-1, 1) * math.sqrt(6.0 / (in_channels + out_channels))
x = torch.randn(512)
for i in range(100):
a = xavier(512, 512)
x = a @ x
x = torch.tanh(x)
print(x.mean(), x.std())
tensor(-0.0014) tensor(0.0540)
此时,使用Xavier初始化后,得到的均值和方差跟我们的方法差不多了。
4. Kaiming 初始化
从概念上讲,当我们使用关于零对称且在[-1, 1]内具有输出的激活函数(例如softsign和tanh)时,我们希望每一层的激活输出的平均值为0和平均标准差在1左右。这正是我们的基本方法和Xavier都能实现的。
但是如果使用现在更加流行的Relu或者LeakyRelu等其他函数呢?我们使用同样的方法放缩权重是否仍有意义。
# 创建一个画板
import math
import numpy as np
import torch
import matplotlib.pyplot as plt
import mpl_toolkits.axisartist as axisartist
fig = plt.figure('activate', (10,8))
ax = axisartist.Subplot(fig, 1,1,1)
fig.add_axes(ax)
ax.axis[:].set_visible(False)
ax.axis["x"] = ax.new_floating_axis(0, 0)
ax.axis["y"] = ax.new_floating_axis(1, 0)
#新建可移动的坐标轴
ax.axis["x"].set_axis_direction('top')
ax.axis["y"].set_axis_direction('left')
x = torch.arange(-5, 5, 0.01)
y_t = torch.relu(x)
plt.xticks(torch.arange(-5, 6, 2))
plt.yticks(torch.arange(0,7,2))
plt.scatter(x, y_t, label='Relu')
plt.legend(loc='upper left', prop = {'size':16})
plt.show()
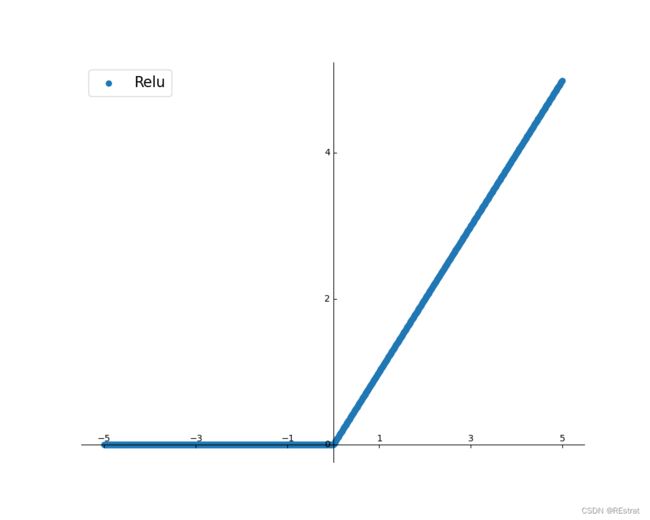
R = m a x ( 0 , x ) R=max(0,x) R=max(0,x)
为了探究使用Relu之后,Xavier初始化是否还有作用,我们讲tanh函数改为relu之后,再次运行我们的100层简单网络。
import math
import numpy as np
import torch
import matplotlib.pyplot as plt
import mpl_toolkits.axisartist as axisartist
def xavier(in_channels, out_channels):
return torch.Tensor(in_channels,out_channels).uniform_(-1, 1) * math.sqrt(6.0 / (in_channels + out_channels))
x = torch.randn(512)
for i in range(100):
a = xavier(512, 512)
x = a @ x
x = torch.relu(x)
print(x.mean(), x.std())
tensor(2.1620e-16) tensor(3.2313e-16)
我们再次发现梯度消失现象,说明Xavier初始化并不能满足relu函数的要求
让我们深度探究一下为什么,同样我们采取如何推导出我们的基本初始化方法一样的办法。我们先看一下,加了Relu函数之后的输出的标准偏差。
import math
import numpy as np
import torch
import matplotlib.pyplot as plt
import mpl_toolkits.axisartist as axisartist
mean = 0
var = 0
for i in range(10000):
x = torch.randn(512)
a = torch.randn(512, 512)
y = torch.relu(a @ x)
mean += y.mean().item()
var += y.pow(2).mean().item()
print(mean/10000, math.sqrt(var/10000))
print(math.sqrt(512/2))
9.025176297998428 16.00142959816968
16.0
可以发现,当使用Relu激活时候,平均而言,单层的标准偏差非常接近输入连续数除以2的总体平方根。
我们再次使用 512 / 2 \sqrt{512/2} 512/2去初始化权重。
import math
import numpy as np
import torch
import matplotlib.pyplot as plt
import mpl_toolkits.axisartist as axisartist
def xavier(in_channels, out_channels):
return torch.Tensor(in_channels,out_channels).uniform_(-1, 1) * math.sqrt(6.0 / (in_channels + out_channels))
mean = 0
var = 0
for i in range(10000):
x = torch.randn(512)
a = torch.randn((512, 512)) * math.sqrt(2/512.)
y = torch.relu(a @ x)
mean += y.mean().item()
var += y.pow(2).mean().item()
print(mean/10000, math.sqrt(var/10000))
0.563040738016367 0.9990654915916081
可以发现,这样得到的输出基本都是符合标准正态分布的。正如我们之前所展示的,将层激活的标准偏差保持在 1 左右将允许我们在深度神经网络中堆叠更多层,而不会出现梯度爆炸或消失。
import math
import numpy as np
import torch
import matplotlib.pyplot as plt
import mpl_toolkits.axisartist as axisartist
x = torch.randn(512)
for i in range(100):
a = torch.randn((512, 512)) * math.sqrt(2/512.)
x = a @ x
x = torch.relu(x)
print(x.mean(), x.std())
tensor(0.4214) tensor(0.5959)
我们发现,当使用这样的权重初始化后,我们的100层经过Relu激活函数的矩阵运算,仍然还有相当强大的梯度回传能力。
这种探索如何在具有类似 ReLU 的激活的网络中最好地初始化权重是 何凯明等人的动机——Kaiming初始化,该方案专为使用这些不对称、非线性激活的深度神经网络量身定制。
在他们 2015 年的论文中,证明如果采用以下输入权重初始化策略,深度网络(例如 22 层 CNN)会更早收敛:
- 在给定层创建一个尺寸适合权重矩阵的张量,并用从标准正态分布中随机选择的数字填充它。
- 将每个随机选择的数字乘以 2 / n \sqrt{2/n} 2/n,其中n是输入通道数。
- 偏置张量初始化为零。
5. Equalized Learning Rate(GAN)
ELR是StyleGan中引入的一个训练技巧,用于稳定和改进训练。
这个想法是在每次通过的前向传播之前缩放每一层的参数。缩放多少取决于输入特征的计算统计量,
class EqualConv2d(nn.Module):
def __init__(self, in_channel, out_channel, kernel_size, stride=1, padding=0, bias=True):
super().__init__()
self.weight = nn.Parameter(torch.randn(out_channel, in_channel, kernel_size, kernel_size))
self.scale = 1 / math.sqrt(in_channel * kernel_size ** 2)
self.stride = stride
self.padding = padding
if bias:
self.bias = nn.Parameter(torch.zeros(out_channel))
else:
self.bias = None
def forward(self, input):
return F.conv2d(input, self.weight * self.scale, bias=self.bias, stride=self.stride, padding=self.padding)
def __repr__(self):
return (
f'{self.__class__.__name__}({self.weight.shape[1]}, {self.weight.shape[0]},'
f' {self.weight.shape[2]}, stride={self.stride}, padding={self.padding})'
)
class EqualLinear(nn.Module):
def __init__(self, in_dim, out_dim, bias=True, bias_init=0, lr_mul=1, activation=None):
super().__init__()
self.weight = nn.Parameter(torch.randn(out_dim, in_dim).div_(lr_mul))
if bias:
self.bias = nn.Parameter(torch.zeros(out_dim).fill_(bias_init))
else:
self.bias = None
self.activation = activation
self.scale = (1 / math.sqrt(in_dim)) * lr_mul
self.lr_mul = lr_mul
def forward(self, input):
if self.activation:
out = F.linear(input, self.weight * self.scale)
out = fused_leaky_relu(out, self.bias * self.lr_mul)
else:
out = F.linear(input, self.weight * self.scale, bias=self.bias * self.lr_mul)
return out
def __repr__(self):
return (f'{self.__class__.__name__}({self.weight.shape[1]}, {self.weight.shape[0]})')
具体来说,我是这样理解的(个人理解,我还是没太懂),我们前面学习了Kaiming初始化,kaiming初始化主要是将每个随机选择的数字乘以 2 / n \sqrt{2/n} 2/n,其中n是输入通道数。当然,前面我们主要分析的是深度神经网络,现在回到深度卷积网络,假设输入是(b,c,h,w)。那么参数量就是chw,按照karming初始化,我们需要讲正态分布的参数除以 2 / c h w \sqrt{2/chw} 2/chw。从而完成参数初始化。
而ELR更像是给各个卷积层都加上了一个永久的初始化,使得网络更好训练。
另外一个可能是说对于不同大小的卷积加上了不同尺度的学习率,使得越大的卷积学习率越小,从而降低GAN网络动不动就崩溃的问题吧。