用Python构建Amazon产品推荐系统!这项目价值能有2000吗?
引言
该项目的目标是部分重建Amazon电子类产品的推荐系统。
现在是十二月!你是什么类型的购物者?双十二都购买了吗?你是把当天想购买的所有产品都保存起来,还是宁愿打开网站,查看带有巨大折扣的现场优惠呢?
尽管网店在过去十年中取得了令人难以置信的成功,显示出巨大的潜力和增长势头,但实体店和网店的基本区别之一却是消费者的冲动购买。
如果你主动向客户展示了一系列产品,他们更有可能购买他们原本没有计划购买的产品。冲动购买的现象受到网店配置的极大限制。同样的情况在实体店却不会发生。最大的实体零售连锁店让顾客走一条精确的路径,以确保他们在离开商店之前参观商店的每一条货架间的过道。
像Amazon这样的网店可以通过推荐系统重现冲动购买现象。推荐系统识别客户刚刚购买或观看的最相似或互补的产品。其目的是将网店通常缺乏的随机购买现象最大化。
在Amazon 上购买使我对机制非常感兴趣,我想重新创建(实际上是部分重新)他们推荐系统的结果。
根据博客“Recostream”,亚马逊产品推荐系统有三种依赖关系,其中一种是产品对产品的推荐。当用户实际上没有历史搜索记录时,该算法将产品聚类在一起,并根据项目的元数据将其推荐给同一用户。
数据
项目的第一步是收集数据。幸运的是,圣地亚哥加州大学的研究人员有一个可以让学生和组织外的个人使用数据进行研究和项目的存储库。可以通过以下链接(http://jmcauley.ucsd.edu/data/amazon/links.html)访问数据以及与推荐系统相关的许多有趣的数据集[2][3]。产品元数据上次更新于2014年;很多产品今天可能都没有了。
电子类元数据包含了498196条记录,共有8列:
-
asin—与每个产品关联的唯一ID
-
imUrl—与每个产品关联的图像URL链接
-
description—产品说明
-
categories —每个产品所属类别的python列表
-
title—产品的名称
-
price—产品的价格
-
salesRank—特定类别中每个产品的排名
-
related —与每个产品相关的客户查看和购买的产品
-
brand—产品的品牌。
你将注意到该文件是“松散”的JSON格式,其中每一行都是一个JSON,它包含了前面提到的所有列以作为其中一个字段。我们将在代码部署部分了解如何处理此问题。
EDA
让我们从快速探索性数据分析开始。在清理了其中一列中至少包含NaN值的所有记录后,我为电子类产品创建了可视化。
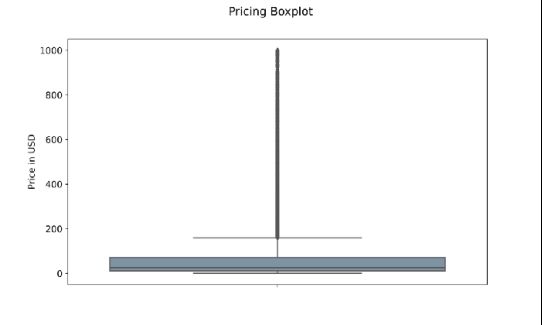
带异常值的价格箱形图——图像由作者提供
第一个图表是显示每个产品的最高、最低、第25百分位、第75百分位和平均价格的箱形图。例如,我们知道一个产品的最高价值是1000美元,而最低价值大约是1美元。160美元标记上方的线是由点组成的,每个点都标识一个异常值。在整个数据集中,异常值表示只发生一次的记录。因此,我们只知道一种定价在1000美元左右的产品。
平均价格似乎在25美元左右。需要注意的是,matplotlib以选项showfliers=False自动排除异常值,为了使框图看起来更清晰,我们可以将参数设置为false。

价格箱形图——图像由作者提供
结果是一个不带异常值的更清晰的箱形图。该图表还表明,绝大多数电子产品的价格在1美元至160美元之间。
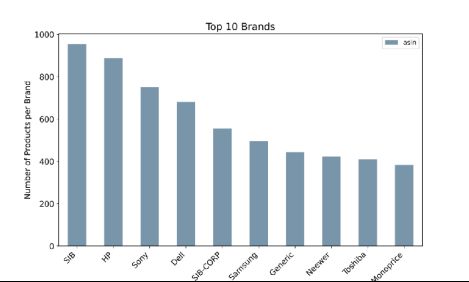
产品数量排名前十的品牌——作者图片
该图表显示了在Amazon上销售的电子类产品中排名前十的品牌。其中包括惠普、索尼、戴尔和三星。
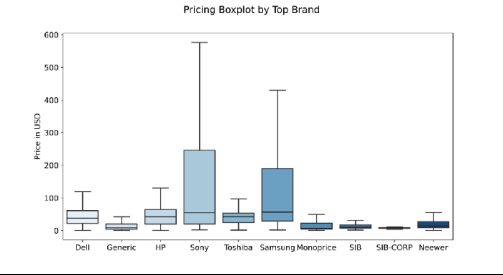
十大零售商价格箱形图
最后,我们可以看到前十名卖家的价格分布形式。索尼和三星提供的产品种类繁多,从几美元到500美元和600美元不等,因此,它们的平均价格高于大多数顶级竞争对手。有趣的是,SIB和SIB-CORP提供了更多的产品,但平均价格更实惠。
该图表还告诉我们,索尼提供的产品大约占数据集中价格最高产品的60%。
余弦相似性
一种通过产品的特性将产品聚集在一起的方案就是余弦相似性。我们需要彻底理解这个概念,才能构建我们的推荐系统。
余弦相似性度量两个数字序列的“接近”程度。它如何适用于我们的案例?令人惊讶的是,句子可以转换成数字,或者更好地转换成向量。
余弦相似度可以取-1和1之间的值,其中1表示两个向量在形式上相同,而-1表示它们尽可能不同。
数学上,余弦相似性是两个多维向量的点积除以其大小的乘积[4]。我知道这里有很多难以理解的词,让我们用一个实际的例子来解释一下吧。

由Embed Fun提供
假设我们正在分析文档A和文档B。文档A有三个最常见的术语:“今天”、“好”和“阳光”,它们分别出现4次、2次和3次。文档B中这三个术语出现了3、2和2次。因此,我们可以这样写:
A=(2,2,3);B=(3,2,2)
两个向量的点积公式可以写成:

由Embed Fun提供
向量点积:2x3+2x2+3x2=16
另一方面,单向量值的计算如下:
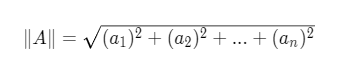
应用以上公式可得:||A|| = 4.12 ; ||B|| = 4.12
因此它们的余弦相似性为:16 / 17 = 0.94 = 19.74°
这两个向量非常相似。
到目前为止,我们只计算了两个三维向量之间的值。实际上,一个词向量可以有无限个维度(取决于它包含的单词数量),但这个过程背后的逻辑在数学上是相同的。在下一节中,我们将了解如何在实践中应用所有概念。
代码编写
让我们进入代码编写阶段——在数据集上构建推荐系统。
每个数据科学笔记本的第一个单元都应该导入数据库,我们项目需要的代码是:
#Importing libraries for data management
import gzip
import json
import pandas as pd
from tqdm import tqdm_notebook as tqdm
#Importing libraries for feature engineering
import nltk
import re
from nltk.corpus import stopwords
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.metrics.pairwise import cosine_similarity-
gzip:解压数据文件
-
json :解码
-
pandas:将JSON数据转换为更易于管理的数据帧格式
-
tqdm:创建进度条
-
nltk :处理文本字符串
-
re:提供正则表达式支持
-
sklearn :文本预处理
读取数据
如前所述,数据以松散的JSON格式上传。解决此问题的方法首先是使用命令 json.dumps将文件转换为JSON可读格式行。然后,我们可以将此文件设置为换行符,并将其转换为由JSON行组成的python列表。最后,我们可以将每一行添加到数据空列表中,同时使用命令 json.loads 将其以JSON的格式读取。
使用命令pd.DataFrame,数据列表被读取为数据帧,我们现在可以使用它来构建推荐器。
#Creating an empty list
data = []
#Decoding the gzip file
def parse(path):
g = gzip.open(path, 'r')
for l in g:
yield json.dumps(eval(l))
#Defining f as the file that will contain json data
f = open("output_strict.json", 'w')
#Defining linebreak as '\n' and writing one at the end of each line
for l in parse("meta_Electronics.json.gz"):
f.write(l + '\n')
#Appending each json element to the empty 'data' list
with open('output_strict.json', 'r') as f:
for l in tqdm(f):
data.append(json.loads(l))
#Reading 'data' as a pandas dataframe
full = pd.DataFrame(data)为了让你了解数据列表的每一行,我们运行了一个简单的命令print(data[0]),在索引0处控制台打印即可。
print(data[0])
output:
{
'asin': '0132793040',
'imUrl': 'http://ecx.images-amazon.com/images/I/31JIPhp%2BGIL.jpg',
'description': 'The Kelby Training DVD Mastering Blend Modes in Adobe Photoshop CS5 with Corey Barker is a useful tool for...and confidence you need.',
'categories': [['Electronics', 'Computers & Accessories', 'Cables & Accessories', 'Monitor Accessories']],
'title': 'Kelby Training DVD: Mastering Blend Modes in Adobe Photoshop CS5 By Corey Barker'
}正如你所看到的一样,输出的是一个JSON文件,它有{}来打开和关闭字符串,每个列名后面都跟着相应的字符串。你可以注意到,第一个产品缺少price、 salesRank、related和brand这些列将自动填充NaN值。
一旦我们用dataframe阅读整个列表,电子产品将显示以下八个特征:
| asin | imUrl | description | categories |
|--------|---------|---------------|--------------|
| price | salesRank | related | brand |
|---------|-------------|-----------|---------|特征工程
特征工程负责清理数据和创建专栏,我们将在其中计算余弦相似性分数。由于RAM内存的限制,我不希望专栏特别长,正如评论或产品描述一样。相反,我决定用categories、 title、 和brand 创建一个“数据包”。但在此之前,我们需要消除这三列中任一包含NaN值的行。
所选栏目以我们推荐人所需文本的形式包含有价值的重要信息。描述列也可能是一个潜在的候选项,但字符串通常太长,并且没有在数据集中进行标准化。对于我们正在努力实现的目标来说,它并不代表足够可靠的信息。
#Dropping each row containing a NaN value within selected columns
df = full.dropna(subset=['categories', 'title', 'brand'])
#Resetting index count
df = df.reset_index()在运行第一部分代码后,行数从498196惊人地减少到大约142000,这是一个很大的变化。只有在这一点上,我们才能创建所谓的数据包:
#Creating datasoup made of selected columns
df['ensemble'] = df['title'] + ' ' +
df['categories'].astype(str) + ' ' +
df['brand']
#Printing record at index 0
df['ensemble'].iloc[0]
output:
"Barnes & Noble NOOK Power Kit in Carbon BNADPN31
[['Electronics', 'eBook Readers & Accessories', 'Power Adapters']]
Barnes & Noble"因为标题并不总是包含其名称,所以需要添加品牌名称。
现在我可以进入清理部分了。text_cleaning函数负责从集合列中删除每个 amp字符串。除此之外,字符串[^A-Za-z0–9]过滤掉所有的特殊字符。最后,函数的最后一行消除了字符串包含的每个停止语。
#Defining text cleaning function
def text_cleaning(text):
forbidden_words = set(stopwords.words('english'))
text = re.sub(r'amp','',text)
text = re.sub(r'\s+', ' ', re.sub('[^A-Za-z0-9]', ' ',
text.strip().lower())).strip()
text = [word for word in text.split() if word not in forbidden_words]
return ' '.join(text)使用lambda函数,我们可以将 text_cleaning应用于称为ensemble 中,我们可以通过调用iloc并指示随机记录的索引来随机选择随机产品的数据包。
#Applying text cleaning function to each row
df['ensemble'] = df['ensemble'].apply(lambda text: text_cleaning(text))
#Printing line at Index 10000
df['ensemble'].iloc[10000]
output:
'vcool vga cooler electronics computers accessories
computer components fans cooling case fans antec'第10001行的记录(索引从0开始)是Antec的vcool VGA cooler。这是一个标题不包括品牌的例子。
余弦运算和推荐函数
余弦相似性的运算从建立一个包含集合列中出现的所有单词的矩阵开始。我们将使用的方法称为“计数矢量化”,或者更常见的“单词包”。
由于RAM的限制,余弦相似性分数仅在预处理阶段后可用的142000条记录中的前35000条记录上进行运算。这很可能会影响推荐者的最终表现。
#Selecting first 35000 rows
df = df.head(35000)
#creating count_vect object
count_vect = CountVectorizer()
#Create Matrix
count_matrix = count_vect.fit_transform(df['ensemble'])
# Compute the cosine similarity matrix
cosine_sim = cosine_similarity(count_matrix, count_matrix)顾名思义,命令cosine_similarity计算count_matrix中每一行的余弦相似度。count_matrix上的每一行都是一个向量,其中包含集合列中出现的每个单词的字数。
#Creating a Pandas Series from df's index
indices = pd.Series(df.index, index=df['title']).drop_duplicates()在运行实际的推荐系统之前,我们需要确保创建一个索引,并且该索引没有重复项。
只有通过这,我们才能定义content_recommender功能。它有4个参数:title 、cosine_sim、 df和 indices。在调用函数时,标题将是唯一要输入的元素。
content_recommender的工作方式如下:
-
查找与用户提供的标题相关联的产品索引
-
在余弦相似度矩阵中搜索产品的索引,并收集所有产品的所有得分
-
将所有得分从最相似的产品(接近1)排序到最不相似的(接近0)
-
选择前30种最相似的产品
-
添加一个索引并以结果的形式返回pandas序列
# Function that takes in product title as input and gives recommendations
def content_recommender(title, cosine_sim=cosine_sim, df=df,
indices=indices):
# Obtain the index of the product that matches the title
idx = indices[title]
# Get the pairwsie similarity scores of all products with that product
# And convert it into a list of tuples as described above
sim_scores = list(enumerate(cosine_sim[idx]))
# Sort the products based on the cosine similarity scores
sim_scores = sorted(sim_scores, key=lambda x: x[1], reverse=True)
# Get the scores of the 30 most similar products. Ignore the first product.
sim_scores = sim_scores[1:30]
# Get the product indices
product_indices = [i[0] for i in sim_scores]
# Return the top 30 most similar products
return df['title'].iloc[product_indices]现在让我们在“Vcool VGA冷却器”上测试它。我们想要三十种类似并且客户会有兴趣购买的产品。通过运行命令content_recommender(product_title) ,该函数将返回一个包含三十条建议的列表。
#Define the product we want to recommend other items from
product_title = 'Vcool VGA Cooler'
#Launching the content_recommender function
recommendations = content_recommender(product_title)
#Associating titles to recommendations
asin_recommendations = df[df['title'].isin(recommendations)]
#Merging datasets
recommendations = pd.merge(recommendations,
asin_recommendations,
on='title',
how='left')
#Showing top 5 recommended products
recommendations['title'].head()在5种最相似的产品中,我们发现了其他Antec产品,如Tricool电脑机箱风扇、扩展槽冷却风扇等等。
1 Antec Big Boy 200 - 200mm Tricool Computer Case Fan
2 Antec Cyclone Blower, Expansion Slot Cooling Fan
3 StarTech.com 90x25mm High Air Flow Dual Ball Bearing Computer Case Fan with TX3 Cooling Fan FAN9X25TX3H (Black)
4 Antec 120MM BLUE LED FAN Case Fan (Clear)
5 Antec PRO 80MM 80mm Case Fan Pro with 3-Pin & 4-Pin Connector (Discontinued by Manufacturer)原始数据集中的相关列中包含了消费者购买、一起购买和观看VGA cooler后购买的产品列表。
#Selecting the 'related' column of the product we computed recommendations for
related = pd.DataFrame.from_dict(df['related'].iloc[10000], orient='index').transpose()
#Printing first 10 records of the dataset
related.head(10)通过在该列中打印python字典的头部,控制台将返回以下数据集。
| | also_bought | bought_together | buy_after_viewing |
|---:|:--------------|:------------------|:--------------------|
| 0 | B000051299 | B000233ZMU | B000051299 |
| 1 | B000233ZMU | B000051299 | B00552Q7SC |
| 2 | B000I5KSNQ | | B000233ZMU |
| 3 | B00552Q7SC | | B004X90SE2 |
| 4 | B000HVHCKS | | |
| 5 | B0026ZPFCK | | |
| 6 | B009SJR3GS | | |
| 7 | B004X90SE2 | | |
| 8 | B001NPEBEC | | |
| 9 | B002DUKPN2 | | |
| 10 | B00066FH1U | | |让我们测试一下我们的推荐怎么样。让我们看看建议中是否包含了also_bought 列表中的一些asin ID。
#Checking if recommended products are in the 'also_bought' column for
#final evaluation of the recommender
related['also_bought'].isin(recommendations['asin'])我们正确地推荐了44种产品中的5种。
[True False True False False False False False False False True False False False False False False True False False False False False False False False True False False False False False False False False False False False False False False False False False]我不同意这是最佳的结果,但考虑到我们在整个数据集中仅使用了498196行中的35000行,这是还是可以接受的。它当然有很大的改进空间。如果目标列的NaN值不那么频繁,甚至不存在,那么建议可能会更准确,甚至更接近Amazon 的实际值。其次是访问更大的RAM内存,甚至是分布式计算,这可以让从业者计算更大的矩阵。
结论
我希望你喜欢这个项目并对将来的任何使用是有用的。
如本文所述,通过将数据集的所有行包含在余弦相似度矩阵中,可以进一步改进最终结果。除此之外,我们还可以通过将元数据数据集与仓库中的其他数据集合并来添加每个产品的审查平均。我们可以在余弦相似度的计算中包含价格。另一种可能是完全基于每个产品的描述性图像来构建推荐系统。点击下方小卡片可以获取源代码,小编推荐一套零基础入门的视频,非常适合零基础看!
进一步改进的主要方案已列出。从未来实施到实际生产的角度来看,其中大多数值得探索。