论文浅尝 | TKGR with Low-rank and Model-agnostic Representations

笔记整理:李行,天津大学硕士
链接:https://arxiv.org/pdf/2204.04783v1.pdf
动机
现有MKGC方法中的知识转移效率低下,因为它们分别对每个KG进行编码并通过强制对齐的实体共享相同的嵌入来转移知识。
亮点
本文的亮点主要包括:
(1)通过将实体对齐视为一种新的边缘类型并引入关系感知注意机制来控制知识传播来处理 MKGC 的知识不一致问题;
(2)提出了一种新的具有自我监督的对齐对生成机制,以缓解种子对齐的稀缺性;
(3)构建了一个新的工业级多语种电子商务知识图谱;
(4)大量实验验证了 SSAGA 在公共和工业数据集中的有效性。
概念及模型
本文为MKGC引入SS-AGA,由图2中的两个交替训练组件(a)和(b)组成:(a)一个新的对齐对生成模块,用于缓解![]() 中的有限种子对齐。具体来说,本文在fuseKG中屏蔽一些种子对齐以获得
中的有限种子对齐。具体来说,本文在fuseKG中屏蔽一些种子对齐以获得 并训练生成器
并训练生成器![]() 来恢复它们。然后,经过训练的生成器将基于学习到的实体嵌入提出新的边,这些边将作为
来恢复它们。然后,经过训练的生成器将基于学习到的实体嵌入提出新的边,这些边将作为![]() 并入
并入![]() ,用于MKG嵌入模型
,用于MKG嵌入模型![]() 在下一次迭代中;(b)一种新的关系感知MKG嵌入模型
在下一次迭代中;(b)一种新的关系感知MKG嵌入模型![]() ,用于解决多语言KG之间的知识不一致问题。具体来说,本文通过将对齐视为一种新的边类型,将不同的KG融合为一个整体图
,用于解决多语言KG之间的知识不一致问题。具体来说,本文通过将对齐视为一种新的边类型,将不同的KG融合为一个整体图![]() 。然后
。然后![]() 使用可学习的关系感知注意力权重计算每个节点的上下文嵌入,这些权重不同于从多个对齐对接收到的影响。最后,KGC解码器
使用可学习的关系感知注意力权重计算每个节点的上下文嵌入,这些权重不同于从多个对齐对接收到的影响。最后,KGC解码器![]() 计算三重分数。
计算三重分数。
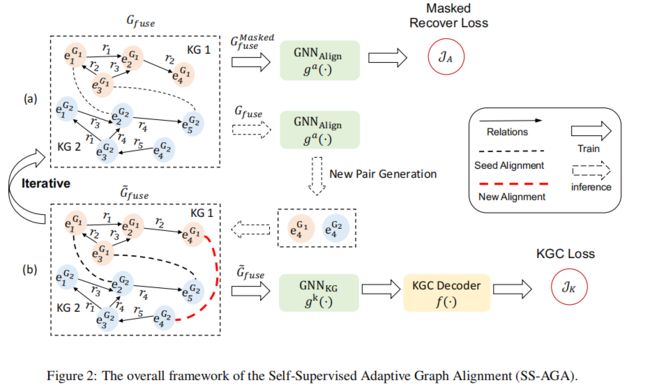
关系感知 MKG 嵌入
为了处理知识不一致,本文首先将所有KG融合为一个整体,从而放松了实体与关系事实的对齐。然后,本文设计了一个基于注意力的关系感知GNN来学习实体的上下文化MKG嵌入,这可以区分来自具有可学习注意力权重的多个对齐源的影响。之后,本文在上下文嵌入上应用KGC解码器,以获得关系事实的三重分数。
自我监督的新对生成
在多语言KG中,只提供有限的种子对齐对来促进知识转移,因为它们的获取成本很高,甚至有时会产生噪音。为了应对这样的挑战,本文提出了一种自我监督的新对齐对生成器。在每次迭代中,生成器识别新的对齐对,这些对齐对将被馈送到GNN编码器![]() 以在下一次迭代中生成上下文化实体嵌入。生成器的训练以自我监督的方式进行,其中生成器需要恢复掩蔽的对齐对。
以在下一次迭代中生成上下文化实体嵌入。生成器的训练以自我监督的方式进行,其中生成器需要恢复掩蔽的对齐对。
训练
整体损失函数是KG完成损失方程和自监督对齐损失方程的组合。如下所示
![]()
其中λ>0是一个正超参数,用于平衡两种损失。
理论分析
实验
数据集:
本文对两个真实世界的数据集进行实验。
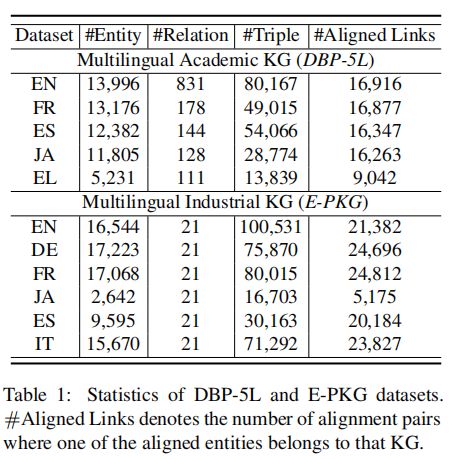
(1)DBP-5L包含来自五种特定语言的KG,即英语(EN)、法语(FR)、西班牙语(ES)、日语(JA)、希腊语(EL)。
(2)E-PKG是一个新的工业多语种电子商务产品知识图谱数据集,它描述了来自电子商务平台的电话相关产品信息,涵盖六种不同的语言:英语(EN)、德语(DE)、法语(FR),日语(JA),西班牙语(ES),意大利语(IT)。
统计数据如表1所示。
评价方案:
在测试阶段,给定每个查询![]() ,计算由测试候选集中每个可能的尾实体eet形成的三元组的合理性分数
,计算由测试候选集中每个可能的尾实体eet形成的三元组的合理性分数![]() 并对它们进行排名。报告平均倒数排名(MRR)、准确度(Hits@1)和排名前10名(Hits@10)中的正确答案比例以供测试。
并对它们进行排名。报告平均倒数排名(MRR)、准确度(Hits@1)和排名前10名(Hits@10)中的正确答案比例以供测试。
基线:
• 单语基线。(i)TransE将关系建模为欧几里得空间中的平移;(ii)RotatE将关系建模为复杂空间中的旋转;(iii)DisMult使用简单的双线性公式;(iv)KG-BERT基于关系和实体的文本信息,采用预先训练的语言模型来完成知识图谱。
• 多语言基线。(i)KEnS将所有KG嵌入到一个统一的空间中,并利用集成技术进行知识转移;(ii)CG-MuA是一种基于GNN的具有集体聚合的KG对齐模型。修改它的损失函数来进行MKGC。(iii)AlignKGC联合训练KGC损失与实体和关系对齐损失。
实验结果:
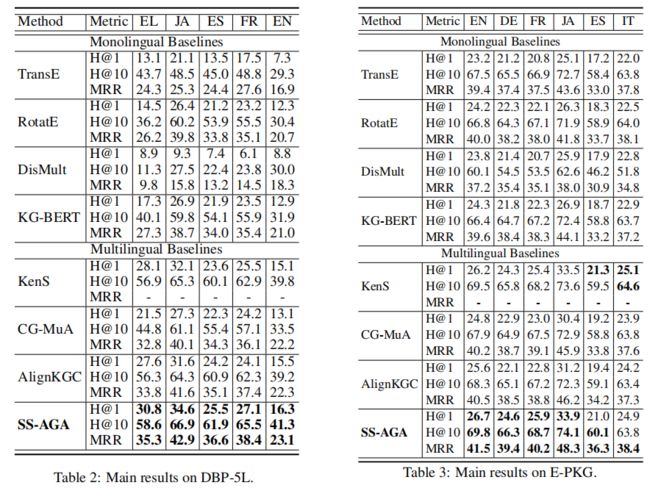
主要结果如表2和表3所示。首先,通过比较多语言和单语言KG模型,可以观察到多语言方法可以取得更好的性能。这表明,与独立推断每个KG相比,利用多个KG源进行KG补全背后的直觉确实是有益的。值得注意的是,多语言模型往往会为DBP-5L中的希腊语等资源较少的KG带来更大的性能提升,预计这是因为低资源KG远未完成,有效的外部知识转移可以带来潜在的好处。在多语言模型中,本文提出的方法SS-AGA在大多数情况下可以在不同的指标、语言和数据集上取得更好的性能,这验证了SS-AGA的有效性。
总结
本文提出了用于多语言知识图谱补全(MKGC)的SS-AGA。它通过融合所有KG并利用GNN编码器来学习具有可学习注意力权重的实体嵌入,从而解决知识不一致问题,该权重不同于多个对齐源的影响。它具有以自我监督学习方式进行的新一代配对,以解决有限的种子对齐问题。包括一个新创建的电子商务数据集在内的两个真实世界数据集的广泛结果验证了SS-AGA的有效性。当前的方法可能无法充分利用实体和关系文本的好处。未来,可以计划研究更有效的方法将文本数据与图形数据结合起来,以获得更好的模型性能。也可以研究没有给出对齐对的MKGC,这是一个非常实用的设置,本文当前的模型无法处理。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。