picoc编译器初始化过程分析
前面提过了最近在 分析picoc的源代码,这篇文章先对picoc的初始化流程做一个简要的分析,其中涉及到的知识点做一些简要的解释。
一、关键数据结构Picoc_Struct
Picoc是通过Picoc_Struct数据结构将整个编译过程组织起来的,其定义位于文件“interpreter.h”中。

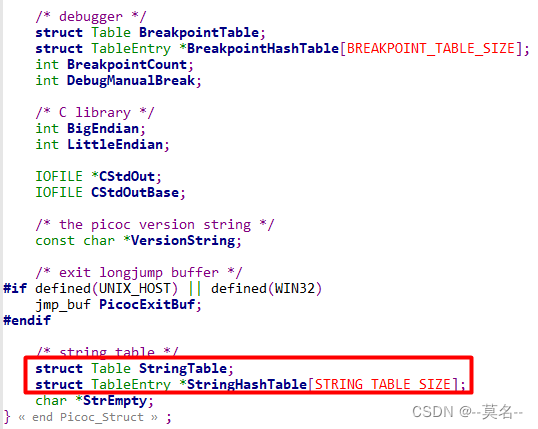
这个结构比较大,内容也比较多,这里只挑重要的截了两张图。主要需要注意的就是上面图中红框圈出的结构,整个picoc编译器就是依靠这些结构组织起来的,大部分的操作也是围绕着这些结构展开的。初始化流程中会这些结果的功能做介绍,这里先不介绍了。
二、初始化流程
Picoc启动后会对编译器进行初始化,由PicocInitialize()函数实现。由于过程比较清晰,这里就不画流程图了。初始化主要包括以下内容:
(1)平台初始化PlatformInit()
Picoc的平台初始化中只是将断点处理BreakHandler()与系统的程序终止信号SIGINT连接起来,以便使用断点调试功能。
(2)输入输出初始化BasicIOInit()
这个是将编译器的输入、输出和报错与系统的标准输入、输出和报错连接起来。
(3)栈初始化HeapInit()
为编译器使用的栈分配空间,将栈内存对齐,并进行初始化。
栈大小(StackSize):通过getenv获得系统环境变量“STACKSIZE”大小,系统未定义或设置为0则取编译器自定义的值PICOC_STACK_SIZE,大小为512KB,定义如下图。
![]()
注意:在C语言中栈(Stack)可以存放函数参数、局部变量、局部数组等作用范围在函数内部的数据,它的用途就是完成函数的调用。因此栈的大小决定了程序中能使用的变量的多少。对每个程序来说,栈能使用的内存是有限的,这个在这里由StackSize决定,程序运行期间不能再改变。如果程序使用的栈内存超出最大值,就会发生栈溢出(Stack Overflow)错误。如果没有改过的话,在 Windows下VS默认是 1MB,在 Linux下GCC默认是 8MB。
栈内存对齐:为什么要对齐?这个一是内存访问的性能原因,一是平台硬件限制原因。在Windows或Linux平台上,编译器默认程序访问的地址必须向8或16字节对齐,即能够被8或16整除,以便提高内存访问效率。当然这个是可以通过预编译命令来修改的。如果你是往非x86的其它平台上移植,需要关注一下这个问题。
从程序上看其实就是把栈帧指针、栈顶指针和栈底指针移到能够被8整除的位置。根据我在Ubuntu18.04上的测试,Picoc默认要是向8字节对齐的。

(4)共享字符串表初始化TableInit()
初始化用于存储共享字符串的表。
原理:需要注册的字符如果不在表中,则计算其哈希值,为其分配空间并将其存入表中;字符串在表中则返回该字符串对应的入口地址。
在table.c的TableSetIdentifier()函数中,当找不到对应的字符串时,重新分配空间。这个位置的分配空间操作有点技巧。先看一下结构定义:

再看下新字符串的空间分配:

新字符串的内存分配是从结构TableEntry的TableEntryPayload处开始,然后长度为IdentLen + 1,其中IdentLen为字符串长度,不含'\0'。然后将字符串值拷贝到该位置:

由于在TableEntry表中定义了一个TableEntryPayload的union,因此NewEntry中具体存储什么内容要看加入数据的时候用的是什么。这里使用的地址是“&NewEntry->p.Key[0]”,后续的代码中也有使用“&NewEntry->p.v.Key[0]”的情况。所以需要去看加入链表的时候给的是什么内容,注意不要搞混了。
这里简单解释一下:共用体union的所有成员占用同一段内存,修改一个成员会影响其余所有成员。结构体占用的内存大于等于所有成员占用的内存的总和(成员之间可能会存在缝隙),共用体占用的内存等于最长的成员占用的内存。共用体使用了内存覆盖技术,同一时刻只能保存一个成员的值,如果对新的成员赋值,就会把原来成员的值覆盖掉。
不清楚union结构的特点的朋友,可以看下这篇文章。
字符串的哈希值计算在函数TableHash()中。这个就是采用固定的计算规则获得字符串的Hash值,这里就不具体分析了,感兴趣的可以自己去看代码。
(5)变量初始化VariableInit()
初始化全局变量名表pc->GlobalTable和字符串名表pc->StringLiteralTable,以及对应的变量值表pc->GlobalHashTable和pc->StringLiteralHashTable。
Picoc这里为了节约空间,将变量的名字和值分开存储,即Table存储所有变量的名称,HashTable存储对应变量的值。
(6)词法分析初始化LexInit()
初始化词法分析相关的关键字表pc->ReservedWordTable和pc->ReservedWordHashTable,并将关键字与Token对应起来。
关键字在注册时会先检查其是否在共享字符串表中,有则直接使用。没找到则重新为其分配内存并存入pc->ReservedWordTable表中。
(7)类型初始化TypeInit()
初始化编译器支持的变量类型数据结构,将各种变量类型的信息存储到pc中对应的结构里。当前支持类型包括:int、short、char、long、unsigned int、unsigned short、unsigned long、unsigned char、void、function、macro、goto、label、double、pointer、array、struct、union、enum、type等。
(8)包含文件初始化IncludeInit()
初始化系统变量和库函数调用,即在编译器的列表pc->IncludeLibList中注册对应的头文件中提供的定义和系统函数,从而将编译器与系统提供的原型定义和函数库连接起来,编程时可以直接使用C语言的底层函数。主要头文件包括:ctype.h、errno.h、math.h、stdbool.h、stdio.h、stdlib.h、string.h、time.h、unistd.h(linux系统)。
(9)库初始化LibraryInit()
这个里面主要是定义了编译器的版本以及大小端的宏。
(10)平台库初始化PlatformLibraryInit()
初始化编译器本身提供的测试函数和打印行号的函数。
(11)调试初始化DebugInit()
初始化调试用断点的数据结构。
三、结论
总结一下,picoc的初始化过程主要是建立编译器运行所需的环境,初始化数据结构和变量定义,并将编译器与系统连接起来。重点需要关注的就是第一部分中提到的那些数据表和堆栈结构,后续会对相关的结构和操作进行详细分析。
这段时间其实一直在研究picoc,但是没有写文章,主要是觉得目前理解的比较浅,怕写错了误导大家^-^。目前基本上是当做学习笔记来写的,发出来是想给初学者理一理思路,有什么问题请大家批评指正~~~
-----------------------------------
原创不易,请多支持!