软件AI加速器:免费提升AI性能
目录
什么是“软件AI加速器”,它与硬件AI加速器相比如何?
人工智能软件生态系统——高性能、高效和开放
深度学习、机器学习和图形分析中的软件AI加速器
深度学习
机器学习
图分析
无处不在的人工智能——软件人工智能加速的应用
通知和免责声明
数据的指数级增长满足了人工智能的贪婪需求,并导致其从小众市场转变为无所不在。这个AI增长方程式的一个同样重要的方面是它对计算机系统要求的不断扩大的要求,以提供更高的AI性能。这不仅导致人工智能加速被整合到CPU、GPU和FPGA等常见芯片架构中,而且还催生了一类专门用于加速人工神经网络和机器学习应用的专用硬件人工智能加速器。虽然这些硬件加速器可以提供令人印象深刻的AI性能改进,但软件AI加速器需要提供更高数量级的AI性能对于相同的硬件设置,可以在深度学习、经典机器学习和图形分析方面获得收益。更重要的是,这种由软件优化驱动的AI性能提升是免费的,几乎不需要更改代码或开发人员时间,也不需要额外的硬件成本。
让我们试着想象一下,通过软件AI加速可以实现10-100倍的性能提升,可以实现的成本节约范围。例如,许多领先的流媒体服务拥有数万小时的可用内容。他们可能希望将图像分类和对象检测算法用于内容审核、文本识别和名人识别。根据当地习俗和政府法规,分类标准也可能因国家/地区而异,并且可能需要根据新计划和规则更改,每月对约10%的内容重复该过程。使用在领先的云服务提供商上运行这些AI算法的标价,**。
自动字幕生成和推荐引擎等其他AI服务也可以实现类似的成本节约,当然对于性能提升100倍的用例而言,节约的成本甚至更高。虽然您的特定AI工作负载可能明显较小,但您的节省仍可能相当可观。
软件决定了计算平台的最终性能,因此软件加速对于在娱乐、电信、汽车、医疗保健等领域实现“AI Everywhere”应用至关重要。
什么是“软件AI加速器”,它与硬件AI加速器相比如何?
软件AI加速器是一个术语,用于指代可以通过对相同硬件配置进行软件优化来实现的AI性能改进。软件AI加速器可以使平台在各种应用程序、模型和用例中的速度提高10-100倍以上。
AI工作负载的日益多样化使得业务需要各种AI优化的硬件架构。这些可以分为三大类:AI加速CPU、AI加速GPU和专用硬件AI加速器。我们在当今市场上看到了所有这三种硬件类别的多个示例,例如具有DL Boost的Intel Xeon CPU、具有神经引擎的Apple CPU、具有张量核心的Nvidia GPU、Google TPU、AWS Inferentia、Habana Gaudi和许多其他硬件。由传统硬件公司、云服务提供商和人工智能初创公司联合开发。
虽然AI硬件继续取得巨大进步,但AI模型复杂性的增长率远远超过了硬件的进步。大约三年前,像ELMo这样的自然语言AI模型“只有”9400万个参数,而今年,最大的模型达到了超过1万亿个参数。人工智能的指数级增长意味着即使计算性能提高1000倍,也可以轻松用于解决越来越复杂和有趣的用例。因此,只有通过软件AI加速器驱动的数量级性能增强,才能解决世界问题并达到“AI无处不在”的圣杯。
虽然硬件加速就像更新您的自行车以拥有最新和最强大的功能,但软件加速更像是拥有一种完全重新设想的旅行模式,例如超音速喷气式飞机。

本文专门列出了英特尔至强软件AI加速器的性能数据。但是,我们相信,从AI加速CPU和GPU到专用硬件AI加速器,其他AI平台也可以实现类似幅度的性能提升。我们打算在以后的文章中分享我们其他平台的性能数据,但我们也欢迎其他供应商分享他们的软件加速结果。
人工智能软件生态系统——高性能、高效和开放
随着人工智能用例和工作负载在视觉、语音、推荐系统等方面不断增长和多样化,英特尔的目标是提供无与伦比的人工智能开发和部署生态系统,让每个开发人员、数据科学家、研究人员尽可能无缝地使用它和数据工程师加速他们从边缘到云端的人工智能之旅。
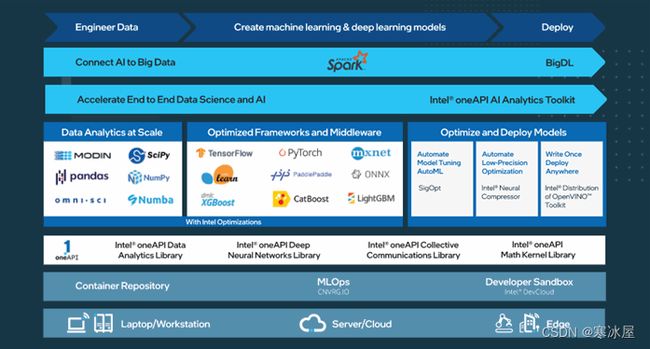
我们相信,建立在开放、基于标准、可互操作的编程模型基础上的端到端AI软件生态系统,是将AI和数据科学项目扩展到生产的关键。这一核心原则构成了我们三管齐下的人工智能战略的基础。
- 建立在广泛的人工智能软件生态系统之上——首先,拥抱当前的人工智能软件生态系统对我们来说至关重要。我们希望每个人都使用他们熟悉的深度学习、机器学习和数据分析软件,例如从TensorFlow和PyTorch、SciKit-Learn和XGBoost,到Ray和Spark。我们对这些框架和库进行了大量优化,以帮助将它们在英特尔平台上的性能提高几个数量级,这些平台旨在提供嵌入式10-100X软件AI加速。
- 实施端到端的数据科学和AI工作流程——其次,我们希望创新并提供一套丰富的优化工具,以满足您的所有AI需求,包括数据准备、训练、推理、部署和扩展。示例包括用于加速端到端数据科学和机器学习管道的英特尔oneAPI AI分析工具包、用于将高性能推理应用程序从设备部署到云的英特尔分发版OpenVINO工具包,以及用于无缝扩展您的AI模型的Analytics Zoo具有数千个节点的大数据集群,用于分布式训练或推理。
- 提供无与伦比的生产力和性能——最后,我们在开放、基于标准、统一的oneAPI编程模型和组成库的基础上构建了跨多种AI硬件的部署工具。当今市场上的众多硬件AI架构,每一个都有一个单独的软件堆栈,为开发者生态系统提供了一种低效且不可扩展的方法。oneAPI行业计划鼓励在oneAPI规范上进行跨行业协作,以提供跨所有加速器架构的通用开发人员体验。
深度学习、机器学习和图形分析中的软件AI加速器
让我们更深入地研究我们三管齐下的AI战略的第一个方面——软件AI加速器。我们广泛的软件优化工作为数据科学家提供了一种简单的方法来有效地实现他们的算法,这些算法由操作图或内核组成。我们的库和工具为单个操作提供内核优化(例如:在实现卷积时有效使用SIMD寄存器、向量化、缓存友好的数据访问)和图级优化(使用诸如batchnorm折叠、conv/ReLU融合和Conv/和融合)跨操作。有关我们的软件优化技术的更多详细信息,请参阅此演讲。
虽然你们中的一些人可能会发现实现细节很有趣,但我们已经为开发人员完成了抽象这些优化的繁重工作,因此他们不需要处理错综复杂的事情。无论是在深度学习、机器学习还是图形分析中,这些英特尔优化都是为大幅提升性能而设计的。
深度学习
英特尔通过oneDNN库进行的软件优化为几个流行的深度学习框架带来了数量级的性能提升,并且大多数优化已经被上传到默认框架分布中。但是,对于TensorFlow和PyTorch,我们还维护单独的Intel扩展作为尚未上传的高级优化的缓冲区。
- TensorFlow——英特尔优化在图像分类推理方面提供16倍增益,在对象检测方面提供10倍增益。基线是带有基本英特尔优化的TensorFlow,向上传输到TensorFlow Eigen库中的函数。
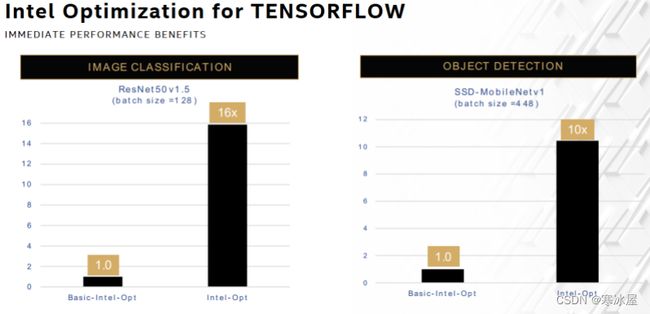
上图:Platinum 8380:1个节点,2个Intel Xeon Platinum 8380处理器,1 TB(16个插槽/64GB/3200)total DDR4内存,uCode 0xd000280,HT on,Turbo on,Ubuntu 20.04.1 LTS,5.4.0-73 -generic1,英特尔900GB SSD操作系统驱动器;ResNet50v1.5,FP32/INT8,BS=128,https://github.com/IntelAI/models/blob/master/benchmarks/image_recognition/tensorflow/resnet50v1_5/README.md;SSDMobileNetv1,FP32/INT8,BS=448, https://github.com/IntelAI/models/blob/master/benchmarks/object_detection/tensorflow/ssd-mobilenet/README.md。软件:适用于FP32的Tensorflow 2.4.0和适用于FP32和INT8的Intel-Tensorflow(icx-base),英特尔于2021年5月12日进行测试。结果可能会有所不同。有关工作负载和配置,请访问www.Intel.com/PerformanceIndex。
- PyTorch — 英特尔优化为图像分类提供了53倍的增益,为推荐系统提供了近5倍的增益。我们已将oneDNN的大部分优化上传到PyTorch,同时还为PyTorch维护了一个单独的英特尔扩展,作为尚未上传的高级优化的缓冲区。因此,对于这个比较,我们通过保持PyTorch仅使用基本的英特尔优化而不使用oneDNN创建了一个新基线。
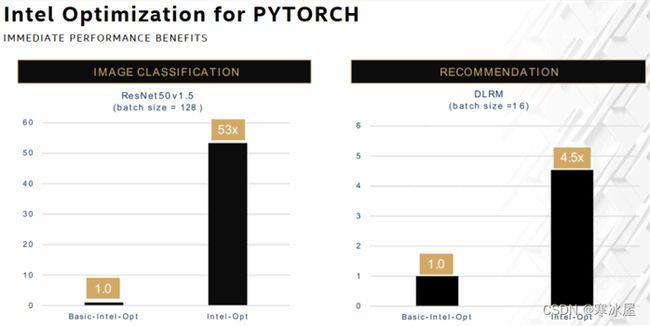
上图:Platinum 8380:1个节点,2个Intel Xeon Platinum 8380处理器,1 TB(16个插槽/64GB/3200)total DDR4内存,uCode 0xd000280,HT on,Turbo on,Ubuntu 20.04.1 LTS,5.4.0-73 -generic1,英特尔900GB SSD操作系统驱动器;ResNet50 v1.5,FP32/INT8,BS=128,https://github.com/IntelAI/models/blob/icx-launch-public/quickstart/ipex-bkc/resnet50-icx/inference;DLRM,FP32/INT8,BS=16,https://github.com/IntelAI/models/blob/icx-launch-public/quickstart/ipex-bkc/dlrm-icx/inference/fp32/README.md。软件:PyTorch v1.5 w/o DNNL build for FP32 & PyTorch v1.5 + IPEX (icx) for FP32 and INT8,英特尔于2021年5月12日进行测试。结果可能会有所不同。有关工作负载和配置,请访问www.Intel.com/PerformanceIndex。
- MXNet — 英特尔优化为图像分类提供了815倍和500倍的增益。MXNet的情况也不同于TensorFlow和PyTorch。我们已经使用oneDNN上传了所有优化。因此,对于这个比较,我们创建了一个没有任何英特尔优化的新基准。
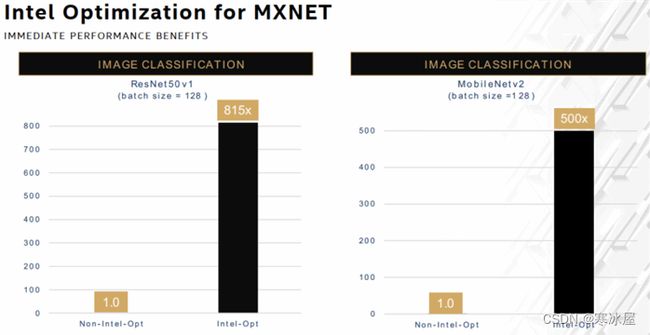
上图:Platinum 8380:1个节点,2个Intel Xeon Platinum 8380处理器,1 TB(16个插槽/64GB/3200)total DDR4内存,uCode 0xd000280,HT on,Turbo on,Ubuntu 20.04.1 LTS,5.4.0-73 -generic1,英特尔900GB SSD操作系统驱动器;ResNet50v1,FP32/INT8,BS=128,https://github.com/apache/incubatormxnet/blob/v2.0.0.alpha/python/mxnet/gluon/model_zoo/vision/resnet.py;MobileNetv2,FP32/INT8, BS=128,https://github.com/apache/incubatormxnet/blob/v2.0.0.alpha/python/mxnet/gluon/model_zoo/vision/mobilenet.py。软件:MXNet 2.0.0.alpha w/o DNNL build for FP32 & MXNet 2.0.0.alpha for FP32 and INT8,英特尔于2021年5月12日进行测试。结果可能会有所不同。有关工作负载和配置,请访问www.Intel.com/PerformanceIndex。
机器学习
Scikit-learn是一个流行的Python机器学习软件库。它具有各种分类、回归和聚类算法,包括支持向量机、随机森林、梯度提升和k-means。我们能够将这些流行算法的性能显着提高100-200倍。这些性能提升可通过英特尔Scikit-learn扩展和英特尔oneAPI数据分析库(oneDAL)获得。
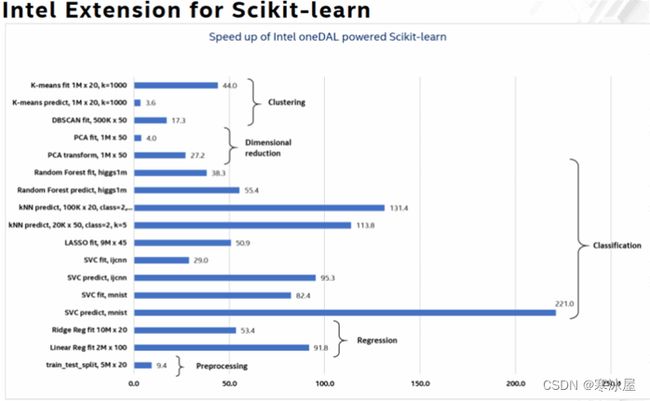
上图:Intel Xeon Platinum 8276L CPU @ 2.20 GHz,2个插槽,每个插槽28个内核;有关工作负载和配置,请访问www.Intel.com/PerformanceIndex。详情:https ://medium.com/intel-analytics-software/accelerate-your-scikit-learn-applications-a06cacf44912,https : //medium.com/intel-analytics-software/save-time-and-money- with-intel-extension-for-scikit-learn-33627425ae4和https://medium.com/intel-analytics-software/leverage-intel-optimizations-in-scikit-learn-f562cb9d5544
图分析
图分析是指用于探索大型图数据库(如社交网络、互联网和搜索、Twitter和维基百科)中条目之间关系的强度和方向的算法。广泛使用的图分析算法的示例包括单源最短路径、广度优先搜索、连接组件、页面排名、中介中心性和三角形计数。例如,英特尔优化显示了三角形计数算法的显着改进。随着图的变大,优化级别也会提高,对于接近5000万个顶点和18亿条边的最大图,最大性能提升为166倍。本文更全面地概述了英特尔针对其他几种图形分析算法进行的优化。
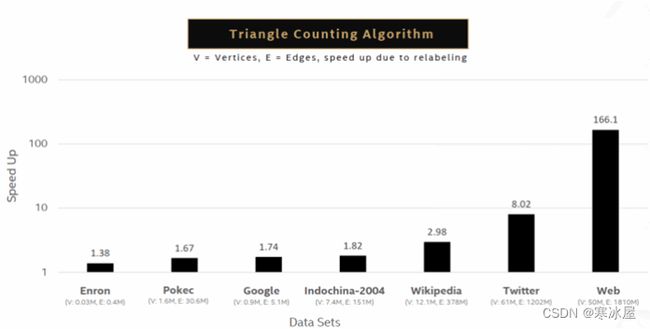
上图:Intel Xeon Platinum 8280 CPU @ 2.70 GHz,2×28 核,HT:开启;有关工作负载和配置,请访问www.Intel.com/PerformanceIndex。数据集:https ://gihub.com/sbeamer/gapbs | https://snap.Stanford.edu/data
无处不在的人工智能——软件人工智能加速的应用
要解决AI问题,需要端到端的工作流程。我们从数据开始,每个用例都有其独特的AI数据管道。人工智能从业者必须摄取数据,通过特征工程进行预处理,有时使用机器学习,使用深度学习或机器学习训练模型,然后部署模型。英特尔oneAPI AI分析工具包提供高性能API和Python包来加速这些管道的所有阶段,并通过软件AI加速实现大幅提速。在本文中,深入了解英特尔oneAPI AI分析工具包帮助数据科学家加速其AI管道的两个真实示例(美国人口普查和PLAsTiCC天文分类)。
虽然我们已经看到软件AI加速器已经提供了对AI的增长及其在每个领域和用例中的传播至关重要的性能改进,但我们还有机会在未来做更多的事情。英特尔正在研究编译器技术、内存优化和分布式计算,以进一步推动软件AI加速。整个AI软件社区也有机会合作,真正释放软件AI加速器的力量——英特尔和其他硬件供应商带头进行低级软件和框架优化,软件供应商领导更高级别的优化,这可以然后与行业标准的中间表示结合在一起。
我们还希望鼓励AI系统构建者更加重视软件,并鼓励开发人员和从业者不懈地追求AI性能加速机会。
(1) 始终使用最新版本的深度学习和机器学习框架(TensorFlow、PyTorch、MXNet、XGBoost、Scikit-learn等),这些框架已经有许多英特尔优化。
(2) 要获得更高的性能,请使用包含所有最新优化并与您现有工作流程完全兼容的框架的英特尔扩展。
详细了解构成英特尔AI软件套件的嵌入式框架优化和性能优化的端到端工具,并将您的AI工作流程提升多达100倍!
软件人工智能加速器与持续的硬件人工智能加速相结合,最终可以让我们走向一个“无处不在的人工智能”的未来,一个更智能、更互联、更适合所有居民的世界。
通知和免责声明
性能因使用、配置和其他因素而异。如需了解更多信息,请访问www.Intel.com/PerformanceIndex。性能结果基于截至配置中显示的日期的测试,可能无法反映所有公开可用的更新。有关配置详细信息,请参阅备份。没有任何产品或组件是绝对安全的。您的成本和结果可能会有所不同。英特尔技术可能需要启用硬件、软件或服务激活。©英特尔公司。英特尔、英特尔徽标和其他英特尔标志是英特尔公司或其子公司的商标。其他名称和品牌可能会被视为他人的财产。
**此计算是基于以下公开信息的近似值:(a)领先的流媒体提供商(例如但不限于Netflix、Amazon Prime、迪士尼等)的流媒体内容的小时数和运营国家以及(b)使用成本美国领先CSP上的计算机视觉和NLP AI服务,包括但不限于AWS、Microsoft Azure和Google Cloud。此估计仅用于说明问题的范围和潜在的成本节约,英特尔不保证其准确性。您的成本和结果可能会有所不同。
Wei Li是英特尔机器学习软件和性能副总裁兼首席架构师。
本文最初发布于https://venturebeat.com/2021/09/22/software-ai-accelerators-ai-performance-boost-for-free
https://www.codeproject.com/Articles/5330215/Software-AI-Accelerators-AI-Performance-Boost-for