DSSM原理解读与工程实践
推荐算法实践
DSSM原理解读与工程实践
一、原理
DSSM(Deep Structured Semantic Model),由微软研究院提出,利用深度神经网络将文本表示为低维度的向量,应用于文本相似度匹配场景下的一个算法。不仅局限于文本,在其他可以计算相似性计算的场景,例如推荐系统中。
其实我们现在来说一件事就是推荐系统和搜索引擎之间的关系。他们两者之间很相似,都是根据满足用户需求,根据用户喜好给出答案,但又不是完全相同,只不过推荐系统更难,因为推荐系统需要挖掘用户潜在喜好来推荐内容和物品给用户。这是因为搜索引擎和推荐系统的关系之间相似性,所以适用于文本匹配的模型也可以应用到推荐系统中。
二、模型结构
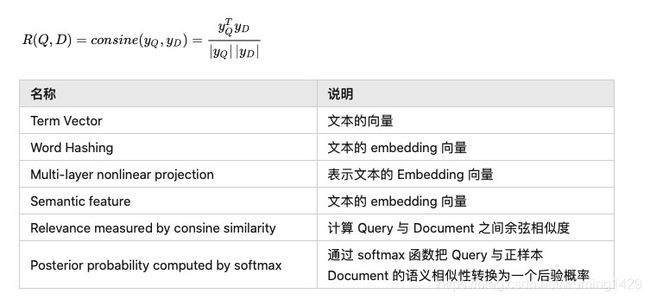
我们还是先看网络结果,网络结果比较简单,是一个由几层全连接组成网络,我们将要搜索文本(Query)和要匹配的文本(Document)的 embedding 输入到网络,网络输出为 128 维的向量,然后通过向量之间计算余弦相似度来计算向量之间距离,可以看作每一个 D 和 Q 之间相似分数,然后在做 softmax ,网络结构如下图
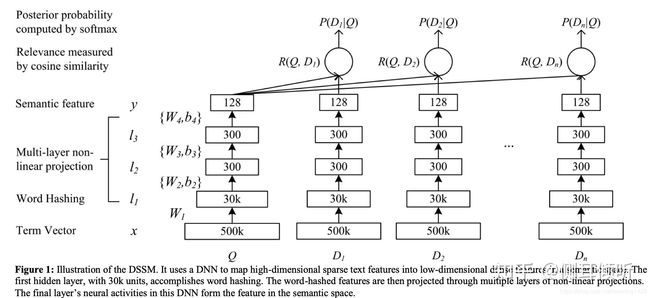
其中Q代表Query信息,D表示Document信息。


三、DSSM 模型在推荐召回环节的应用
1)DSSM 模型在推荐召回环节的结构
DSSM 模型的最大特点就是 Query 和 Document 是两个独立的子网络,后来这一特色被移植到推荐算法的召回环节,即对用户端(User)和物品端(Item)分别构建独立的子网络塔式结构。该方式对工业界十分友好,两个子网络产生的 Embedding 向量可以独自获取及缓存。目前工业界流行的 DSSM 双塔网络结构如图所示(美图DSSM架构图)。

双塔模型两侧分别对(用户,上下文)和(物品)进行建模,并在最后一层计算二者的内积。
2)候选集合召回
当模型训练完成时,物品的 Embedding 是可以保存成词表的,线上应用的时候只需要查找对应的 Embedding 即可。因此线上只需要计算 用户塔 一侧的 Embedding,基于 Milvus 或 Faiss 技术索引得到用户偏好的候选集。
四、DSSM召回实战
下面使用ml-1m数据集,实践一下DSSM召回模型。该模型的实现主要参考:python软件的DeepCtr和DeepMatch模块。
- u2i召回
DSSM模型训练完成可得到用户和物品的Embedding向量,再利用向量最近邻的方法(如局部敏感哈希LSH、kd树、annoy、milvus、faiss等)可计算出与每个用户最相似(向量相似度最高)的top-m个物品。线上召回时输入用户特征给模型,模型预测得到用户向量,利用向量检索工具召回M个相似物品作为候选物品作为该路召回的结果,进入后续的排序阶段。
- I2I召回
DSSM模型训练完成后输入物品特征会生成每个物品的Embedding向量,再利用向量最近邻的方法(如局部敏感哈希LSH、kd树、annoy、milvus、faiss等)可计算出与每个物品最相似(向量相似度最高)的top-m个物品。线上召回时可根据用户最近操作(如点击)过的N个物品,分别召回k个相似物品,一共N*k个作为候选物品作为该路召回的结果,进入后续的排序阶段。
3)两种召回方式效果对比
u2i召回:
对用户行为预测为一个向量后再召回用户向量的topN个物品
i2i召回:
用户最近L个行为物品一一召回k个物品,总体再求topN个物品
用开源数据集ml-1m测试得到的结果如下:
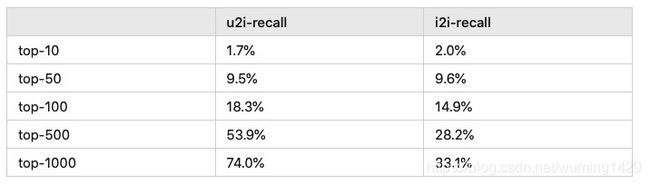
由上述结果可知,对ml-1m数据集u2i召回方式效果要好于i2i召回方式。
完整代码如下:
import faiss
import pandas as pd
from deepctr.feature_column import SparseFeat, VarLenSparseFeat
from preprocess import gen_data_set, gen_model_input
from sklearn.preprocessing import LabelEncoder
from tensorflow.python.keras import backend as K
from tensorflow.python.keras.models import Model
from deepmatch.models import *
import numpy as np
from tqdm import tqdm
from deepmatch.utils import recall_N
import os
data_path = "../"
unames = ['user_id','gender','age','occupation','zip']
user = pd.read_csv(data_path+'ml-1m/users.dat',sep='::',header=None,names=unames,engine='python')
rnames = ['user_id','item_id','rating','timestamp']
ratings = pd.read_csv(data_path+'ml-1m/ratings.dat',sep='::',header=None,names=rnames,engine='python')
mnames = ['item_id','title','genres']
movies = pd.read_csv(data_path+'ml-1m/movies.dat',sep='::',header=None,names=mnames,engine='python')
data = pd.merge(pd.merge(ratings,movies),user)
sparse_features = ["item_id", "user_id", "gender", "age", "occupation", "zip", ]
SEQ_LEN = 50
negsample = 3
# 1.稀疏特征编码,生成训练和测试集
features = ['user_id', 'item_id', 'gender', 'age', 'occupation', 'zip']
feature_max_idx = {}
for feature in features:
lbe = LabelEncoder()
data[feature] = lbe.fit_transform(data[feature]) + 1
feature_max_idx[feature] = data[feature].max() + 1
user_profile = data[["user_id", "gender", "age", "occupation", "zip"]].drop_duplicates('user_id')
item_profile = data[["item_id"]].drop_duplicates('item_id')
user_profile.set_index("user_id", inplace=True)
user_item_list = data.groupby("user_id")['item_id'].apply(list)
train_set, test_set = gen_data_set(data, negsample)
train_model_input, train_label = gen_model_input(train_set, user_profile, SEQ_LEN)
test_model_input, test_label = gen_model_input(test_set, user_profile, SEQ_LEN)
# 2.配置稀疏特征维度及emb维度
embedding_dim = 32
user_feature_columns = [SparseFeat('user_id', feature_max_idx['user_id'], 16),
SparseFeat("gender", feature_max_idx['gender'], 16),
SparseFeat("age", feature_max_idx['age'], 16),
SparseFeat("occupation", feature_max_idx['occupation'], 16),
SparseFeat("zip", feature_max_idx['zip'], 16),
VarLenSparseFeat(SparseFeat('hist_item_id', feature_max_idx['item_id'], embedding_dim,
embedding_name="item_id"), SEQ_LEN, 'mean', 'hist_len'),
]
item_feature_columns = [SparseFeat('item_id', feature_max_idx['item_id'], embedding_dim)]
# 3.定义模型并训练
K.set_learning_phase(True)
import tensorflow as tf
if tf.__version__ >= '2.0.0':
tf.compat.v1.disable_eager_execution()
model = DSSM(user_feature_columns, item_feature_columns)
model.compile(optimizer='adagrad', loss="binary_crossentropy", metrics=['accuracy'])
history = model.fit(train_model_input, train_label, # train_label,
batch_size=256, epochs=10, verbose=1, validation_split=0.2, )
# 4. 生成用户emb和物品emb,用于召回
test_user_model_input = test_model_input
all_item_model_input = {"item_id": item_profile['item_id'].values,}
user_embedding_model = Model(inputs=model.user_input, outputs=model.user_embedding)
item_embedding_model = Model(inputs=model.item_input, outputs=model.item_embedding)
user_embs = user_embedding_model.predict(test_user_model_input, batch_size=2 ** 12)
item_embs = item_embedding_model.predict(all_item_model_input, batch_size=2 ** 12)
test_user_np = test_user_model_input['user_id']
all_item_np = all_item_model_input['item_id']
test_user_emb_all = np.hstack((test_user_np.reshape(-1, 1),user_embs))
all_item_all = np.hstack((all_item_np.reshape(-1, 1),item_embs))
np.savetxt('user_embs.csv', test_user_emb_all, delimiter = ',')
np.savetxt('item_embs.csv', all_item_all, delimiter = ',')
idex = np.lexsort([all_item_all[:, 0]])
sorted_item_embs = all_item_all[idex, :]
sorted_item_embs2 = sorted_item_embs[:,1:]
np.savetxt('sorted_item_embs.csv', sorted_item_embs, delimiter = ',')
np.savetxt('sorted_item_embs2.csv', sorted_item_embs2, delimiter = ',')
print("sorted_item_emb.shape = ",sorted_item_embs.shape)
print("sorted_item_emb2.shape = ",sorted_item_embs2.shape)
print(test_user_emb_all.shape)
print(all_item_all.shape)
test_true_label = {line[0]:[line[2]] for line in test_set}
# 5、faiss 创建索引 插入item_embs
index = faiss.IndexFlatIP(embedding_dim)
# faiss.normalize_L2(item_embs)
index.add(item_embs)
# 6、根据user_emb 检索物品列表
# faiss.normalize_L2(user_embs)
D, I = index.search(np.ascontiguousarray(user_embs), 1000)
s1000 = []
s500 = []
s100 = []
s50 = []
s10 = []
hit = 0
filename = 'user_emb_rec_list.txt'
if os.path.exists(filename):
os.remove(filename)
with open(filename, 'a') as f:
for i, uid in tqdm(enumerate(test_user_model_input['user_id'])):
pred = [item_profile['item_id'].values[x] for x in I[i]]
item_list = ",".join('%s' %x for x in pred)
filter_item = None
recall_score_1000 = recall_N(test_true_label[uid], pred, N=1000)
recall_score_500 = recall_N(test_true_label[uid], pred, N=500)
recall_score_100 = recall_N(test_true_label[uid], pred, N=100)
recall_score_50 = recall_N(test_true_label[uid], pred, N=50)
recall_score_10 = recall_N(test_true_label[uid], pred, N=10)
s1000.append(recall_score_1000)
s500.append(recall_score_500)
s100.append(recall_score_100)
s50.append(recall_score_50)
s10.append(recall_score_10)
# if test_true_label[uid] in pred:
# hit += 1
f.write("{} {}\n".format(uid, item_list))
print("recall1000", np.mean(s1000))
print("recall500", np.mean(s500))
print("recall100", np.mean(s100))
print("recall50", np.mean(s50))
print("recall10", np.mean(s10))
# print("hit rate", hit / len(test_user_model_input['user_id']))
# 7、根据item_emb 检索物品列表生成I2I倒排索引
# faiss.normalize_L2(item_embs)
D, I = index.search(np.ascontiguousarray(item_embs), 50)
s1000 = []
s500 = []
s100 = []
s50 = []
s10 = []
hit = 0
i2i_dict = {}
filename = 'item_item_list.txt'
if os.path.exists(filename):
os.remove(filename)
with open(filename, 'a') as f:
for i, item_id in tqdm(enumerate(all_item_model_input['item_id'])):
pred = [item_profile['item_id'].values[x] for x in I[i] ]
pred2 = [x for x in pred if x != item_id]
item_list = ",".join('%s' % x for x in pred2)
# i2i倒排索引
i2i_dict[item_id] = [x for x in pred2]
f.write("{} {}\n".format(item_id, item_list))
# 不改变顺序去重
def dupe(items):
seen = set()
for item in items:
if item not in seen:
yield item
seen.add(item)
# 8、根据用户最近操作的50个物品检索物品列表
data.sort_values("timestamp", inplace=True, ascending=False)
filename = 'user_action_rec_list.txt'
if os.path.exists(filename):
os.remove(filename)
filename2 = 'user_action_rec_list2.txt'
if os.path.exists(filename2):
os.remove(filename2)
filename3 = 'user_action_list.txt'
if os.path.exists(filename3):
os.remove(filename3)
with open(filename, 'a') as f, open(filename2,'a') as f2, open(filename3,'a') as f3:
for uid, hist in tqdm(data.groupby('user_id')):
pred = []
result = []
# 截取最近50个物品
pos_list = hist['item_id'].tolist()[1:51]
act_list = ",".join('%s' % x for x in pos_list)
# 根据这50个物品检索物品列表
for item_id in pos_list:
pred = pred + i2i_dict[item_id]
result.append(str(item_id) + ":[" + ",".join('%s' % x for x in i2i_dict[item_id]) + "]")
pred = list(dupe(pred))
pred = pred[:1000]
item_list = ",".join('%s' % x for x in result)
item_list2 = ",".join('%s' % x for x in pred)
filter_item = None
recall_score_1000 = recall_N(test_true_label[uid], pred, N=1000)
recall_score_500 = recall_N(test_true_label[uid], pred, N=500)
recall_score_100 = recall_N(test_true_label[uid], pred, N=100)
recall_score_50 = recall_N(test_true_label[uid], pred, N=50)
recall_score_10 = recall_N(test_true_label[uid], pred, N=10)
s1000.append(recall_score_1000)
s500.append(recall_score_500)
s100.append(recall_score_100)
s50.append(recall_score_50)
s10.append(recall_score_10)
# if test_true_label[uid] in pred:
# hit += 1
f.write("{} {}\n".format(uid, item_list))
f2.write("{} {}\n".format(uid, item_list2))
f3.write("{} {}\n".format(uid, act_list))
print("recall1000", np.mean(s1000))
print("recall500", np.mean(s500))
print("recall100", np.mean(s100))
print("recall50", np.mean(s50))
print("recall10", np.mean(s10))
五、相关思考
1)上下文特征是放到用户塔还是物品塔?
2)新物品如何计算其Embeding?
3) 在此基础上如何进一步优化其效果?有哪些思路?
4)线上如何部署?