论文阅读:Neural Code Comprehension: A Learnable Representation of Code Semantics--NeurIPS 2018
摘要:
大多数作品直接处理代码或者使用语法树表示,然而因为程序的一些结构特征,像函数调用、分支、以及语句顺序的可替换性,现有的方法没有足够地理解程序语义的鲁棒性。本文提出了一种新的技术去学习代码语义,并将其应用于各种程序分析任务中。具体来说,首先规定一个适应于人类和机器生成的程序的健壮的代码分布假设,根据这个假设定义一个基于代码中间(IR,独立于源代码编程语言)表示的嵌入空间inst2vec。利用程序的数据流和控制流,我们为IR提供了一个新的上下文表示的定义,XFG。然后使用类比和聚类的方法对嵌入进行定性分析,并对三个不同的高级任务的学习表示进行评估。实验表明,即使没有微调,单个RNN架构和固定inst2vec嵌入也优于性能预测(计算设备映射、最佳线程粗化)和原始代码(104个类)的算法分类的专用方法。
现有方法的缺陷:
①??源程序设计语言固定
②顺序处理token,主要以功能的、无循环的代码为目标,这些代码并不能代表大多数应用程序。
总体结构
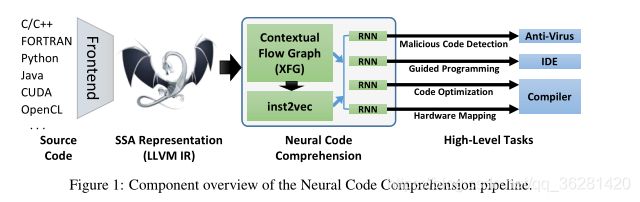
主要过程
源代码(不限制语言)->IR(通过LLVM编译器表示成中间表示)->XFGs(使用数据流和控制流构造,所以支持循环和函数调用)->使用XFG训练单个语句的嵌入空间(inst2vec)->RNNs
本篇文章的不同之处在于:
以往的模型都是使用token或者statements的粒度,直接嵌入像java的高维度的程序语言,没有尝试过IR(代码的中间表示)嵌入。
使用contextual flow区别于已有的方法( lexicographical locality、代码的结构如使用DFG,CFG,AST,AST的路径,或者an augmented AST)
contxtual flow可以捕获数据依赖和控制依赖
an augmented AST,比如使用附加的边来连接不同的用途,并更新与变量对应的语法标记。
嵌入质量的衡量
以前使用代码嵌入的工作并不是根据其自身的优点来评估训练空间的质量,而是通过后续(下游)任务的性能来评估。一个例外是Allamanis等人。[2] ,他们提供了相似方法名向量相似性的经验证据。据我们所知,我们首先以聚类、句法类比、语义类比和分类距离测试的形式量化代码嵌入空间本身的质量。
一个具有健壮性的代码分布假设
Statements that occur in the same contexts tend to have similar semantics.
上下文:我们将上下文直接定义为其执行直接依赖于彼此的语句。
如:一个变量的定义和使用。
对于代码语句的上下文,我们不能像自然语言一样,直接取前面几个单词,后面几个单词,要根据代码的特点来定义上下文,在这一方面已经有了一下工作,比如使用抽象语法树,数据流动图等方式来定义代码的上下文,具体可以看论文中的Related Work部分,在作者看来,代码语句的上下文必须体现数据的依赖性和执行的依赖性
但是定义可能是在第一行,使用可能是在最后一行,所以会出现RNN的梯度消失。
数据依赖和执行依赖
通过分析数据流可以确定每个语句的数据依赖关系,但是分支和函数的调用不一定会生成这样的依赖关系。它可以用来补充数据流。另一种表示执行依赖的方法是通过“因果关系”的概念,发生的先后关系。
在我们的表示中,上下文是数据依赖性和执行依赖性的结合,因此捕获了这两种关系
相似性:要定义相似性,首先需要定义语句的语义。
语义的定义
我们从程序设计语言理论中的操作语义学中定义了语义,它指的是给定程序中每个计算步骤的影响(例如,先决条件、后决条件)。
在本文中,我们特别假设每个语句以某种方式修改系统状态(例如,添加两个数字)并消耗资源(例如,使用寄存器和浮点单元)。
因此,语义相似度可以通过使用相同资源的两个语句或以类似的方式修改系统状态来定义。使用此定义,具有不同变量类型的同一算法的两个版本将是同义的。
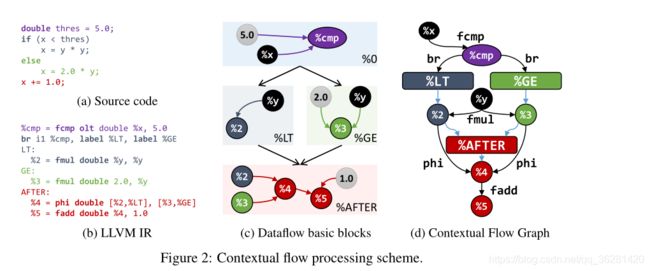
Figures 2a and 2b depict an example code and its LL VM
IR equivalent, and the structure of an LL VM IR statement is shown in Fig. 3.

在LLVM的基础设施中,IR以SSA 静态单次分配的形式给出
简而言之,SSA-IR确保每个变量只分配一次,这使得跟踪IR语句之间的数据流变得容易,如图4所示。为了克服由控制流(如循环)引起的分析问题,SSA定义了∅-表达式。这个表达式枚举了运行时的控制流可能产生的所有的可能的变量,可用于跨分支优化代码。
![]()
为了分析数据流进行优化,LLVM将IR语句划分为不包含控制流的“基本块”,如图2c所示
==???==即使是在有条件的情况下,SSA也会以输入标识符的形式来列出数据依赖项,并将结果分配给标识符,所以语句可以自然地创建可跟踪数据流。
但是数据流不足以用来提供句子的上下文信息,所以本文设计了结合数据流和控制流的conteXtual Flow Graph,XFG
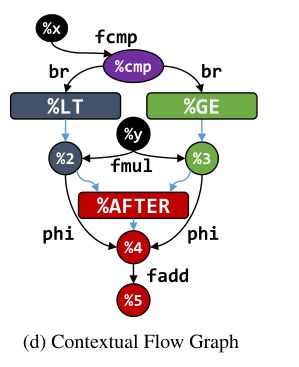
XFG是有向多重图,两个结点之间可以有多条边连接。结点可以是变量或者标识符的标签(如函数名、基本块),如图中的椭圆、长方形
黑色的边表示为数据依赖,带有一个LLVM IR语句,蓝色的边表示为执行依赖。
XFG的构建
增量生成XFG:
①一次读完所有的LLVM IR语句,存储函数名和返回语句
②再次遍历所有的语句,按照如下规则添加图的结点和边:
(a)连接一个基本块中的数据依赖
(b)内嵌的依赖关系,如∅-expressions都是通过标识符的标签直接连接
??(c) Identifiers without a dataflow parent are connected to their root (label or program root)
接下来,XFG通过数据流及分支、循环、和函数(包括递归)创建路径。
?? n个SSA语句时间复杂度是O(n)
external code的调用有两类:静态、动态调用
inst2vec
XFG提供上下文的概念
训练一个嵌入空间来表示独立的句子,这样的嵌入空间需要满足:
(1)临近的句子应该在一个系统上应该有类似的工作(如使用相同的资源)
(2)为不同的指令更改相同的属性(例如,数据类型)应该会在空间中产生类似的偏移
使用skip-gram model来训练LLVM IR语句嵌入,经过预处理来限制词汇表的大小
预处理
首先:过滤掉句子里的注释和元数据(数据是指普通文件中的实际数据,而元数据指用来描述一个文件的特征的系统数据,诸如访问权限、文件拥有者以及文件数据块的分布信息(inode…)等等)
然后:标识符用%ID来替代,直接数值,如数值常量和字符串等常量用
最后:数据结构被“内联”,也就是说,它们的内容被编码在语句中。

图片最后一行是如何处理的???

结论
本篇文章证明,语句的语义可以从它们的上下文中恢复。
这种恢复依赖于适当的粒度,(这个地方我们建议使用经过过滤的LLVM IR指令)和语句的分组(混合使用数据流和控制流)。
文章使用他们提出的表示法来执行三个高级分类和预测任务,表现优于所有手工提取的特征,并获得与两个本质上不同的专业DNN解决方案相当(甚至更好)的结果