「每周CV论文推荐」 初学深度学习单图三维人脸重建需要读的文章
基于图像的人脸三维重建在人脸分析与娱乐领域里有巨大的应用场景,本文来介绍初学深度学习单张图像人脸三维重建必须要读的文章。
作者&编辑 | 言有三
1 3DMM与数据集
虽然这里推荐的是深度学习三维人脸重建需要读的文章,但是因为经常需要用到经典的3DMM模型以及一些数据集,包括最著名的中性表情BFM模型及其2017年新增表情的版本,国内浙大开源的带表情的FareWareHouse数据集。
文章引用量:4000+
推荐指数:✦✦✦✦✦

[1] Blanz V, Vetter T. A morphable model for the synthesis of 3D faces[C]//Siggraph. 1999, 99(1999): 187-194.
[2] Cao C, Weng Y, Zhou S, et al. Facewarehouse: A 3d facial expression database for visual computing[J]. IEEE Transactions on Visualization and Computer Graphics, 2013, 20(3): 413-425.
2 3DMM CNN系列
3DMM CNN是早期使用CNN直接估计3DMM模型形状系数的方法,模型简单有效,使用了非对称损失提升性能。
在此之后,3DMM CNN的作者又水了姿态和表情系数的论文。
文章引用量:160+
推荐指数:✦✦✦✦✦

[3] Tuan Tran A, Hassner T, Masi I, et al. Regressing robust and discriminative 3D morphable models with a very deep neural network[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 5163-5172.
[4] Chang F J, Tuan Tran A, Hassner T, et al. Faceposenet: Making a case for landmark-free face alignment[C]//Proceedings of the IEEE International Conference on Computer Vision. 2017: 1599-1608.
[5] Chang F J, Tran A T, Hassner T, et al. ExpNet: Landmark-free, deep, 3D facial expressions[C]//2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018). IEEE, 2018: 122-129.
3 Volumetric CNN
既然CNN这么强大,为什么不直接预测3D坐标呢?Volumetric CNN就是这样的思路,简单直接预测每一个像素,将3D重建当作了一个图像分割问题
文章引用量:140+
推荐指数:✦✦✦✦✦
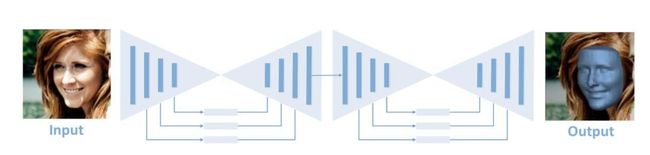
[6] Jackson A S, Bulat A, Argyriou V, et al. Large pose 3D face reconstruction from a single image via direct volumetric CNN regression[C]//Proceedings of the IEEE International Conference on Computer Vision. 2017: 1031-1039.
4 PRNet
三维重建需要预测mesh的顶点坐标,但是直接预测是有困难的,PRNet通过一个UV position map来进行表征,方法简单有效,UVMap对于一些其他的应用也是有启示的。
文章引用量:80+
推荐指数:✦✦✦✦✧

[7] Feng Y, Wu F, Shao X, et al. Joint 3d face reconstruction and dense alignment with position map regression network[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018: 534-551.
5 MoFa
真实的3D数据集获取成本非常高,因此研究人员常常采用仿真的数据集,但是仿真数据集精度不够。以MoFa为代表的这一类方法不依赖于现在的数据集,它通过将二维图像重建到3维,再反投影回2D图的方案,是非常值得研究的自监督重建方法。
文章引用量:160+
推荐指数:✦✦✦✦✦

[8] Tewari A, Zollhofer M, Kim H, et al. Mofa: Model-based deep convolutional face autoencoder for unsupervised monocular reconstruction[C]//Proceedings of the IEEE International Conference on Computer Vision. 2017: 1274-1283.
6 Survey
最后给大家推荐一个2019年关于3DMM模型的综述文章,作为一周的论文阅读来说,上面的内容已经足够多了。
三维人脸重建是一个很大的坑,Shape from Shading以及Structure from Motion等方法这一次没有介绍,后面再说。关于3DMM模型的基础公众号几年前有过简单的解读,之前的一个计算机视觉大综述也有介绍,大家可以快速参考。
「AI白身境」一文览尽计算机视觉研究方向
文章引用量:很新
推荐指数:✦✦✦✦✦

[9] Zheng X, Guo Y, Huang H, et al. A Survey to Deep Facial Attribute Analysis[J]. arXiv preprint arXiv:1812.10265, 2018.