第二章 【数据分析师---数据可视化2】 Plotly绘图基础篇
数据分析可视化2---Plotly
- 第一节 什么是Plotly
-
- 安装使用
-
- 安装
- 使用
- 第二节 使用Plotly绘制散点图和饼图
-
- 散点图
- 饼图
- 第三节 使用自定义的数据进行plotly绘制
- 第四节 plotly高级图形的绘制
-
- density密度图
- 3D 散点图
- 使用chart_studio
- 第五节 Plotly绘制金融数据图
-
- 1.简单绘制
- 2.拖动的时间划轴
-
- 时间快速选择按钮
- 3.绘制蜡烛图
- 4.使用cufflinks模块绘制金融指标图
-
- (1)趋势图
- (2)绘制MACD指标图
- (3)绘制RSI指标图
- (4)绘制布林带指标图
- 第六节 绘制高级散点图和热力图
-
- 1.使用heatmap绘制热力图
- 2.使用scatter功能绘制散点图
- 3.使用scatter_matrix功能绘制散点矩阵
-
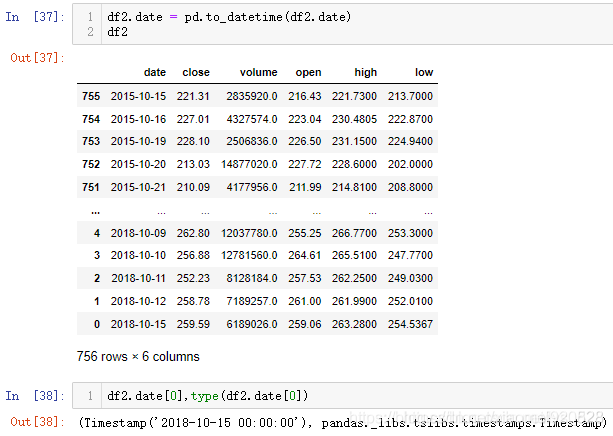
- 花卉练习
- 4.使用scatter_geo功能绘制地理分布图
第一节 什么是Plotly
matplotlib画的是静态的图片,与人没什么交互。plotly提供了高度交互式界面,便于做出更有吸引力的统计图表。在web开发、机器学习以及量化投资方面也有很好的应用场景。
安装使用
安装
pip install plotly
查看使用版本
print (plotly.__version__)
使用
之前的matplotlib
import matplotlib.pyplot as plt
现在的plotly
import plotly
#plotly.offline 离线版本 plot,iplot 离线画,在线画
from plotly.offline import download_plotlyjs , init_notebook_mode, plot,iplot
init_notebook_mode(connected=True)
dict1 = { 'x': [1,2,3,4] , 'y':[5,6,7,8]}
iplot([dict1])
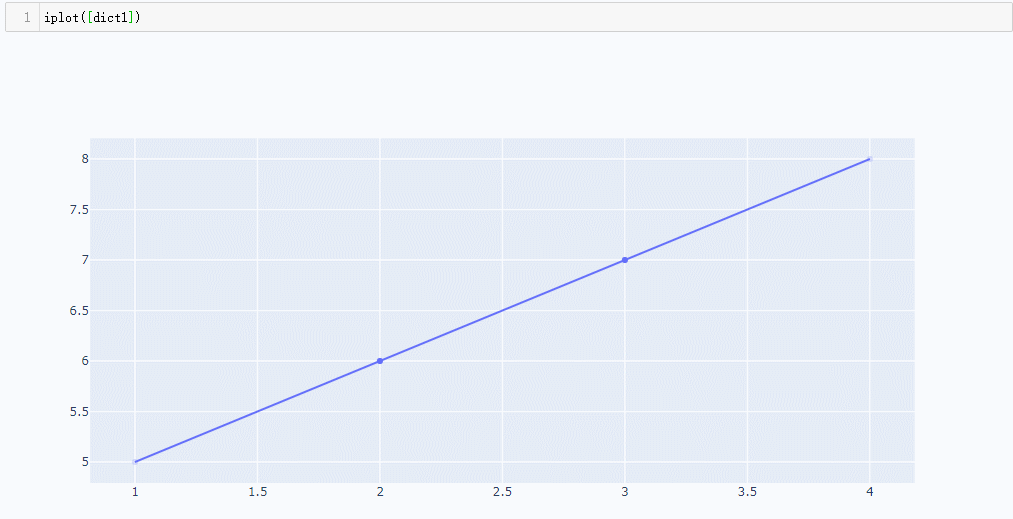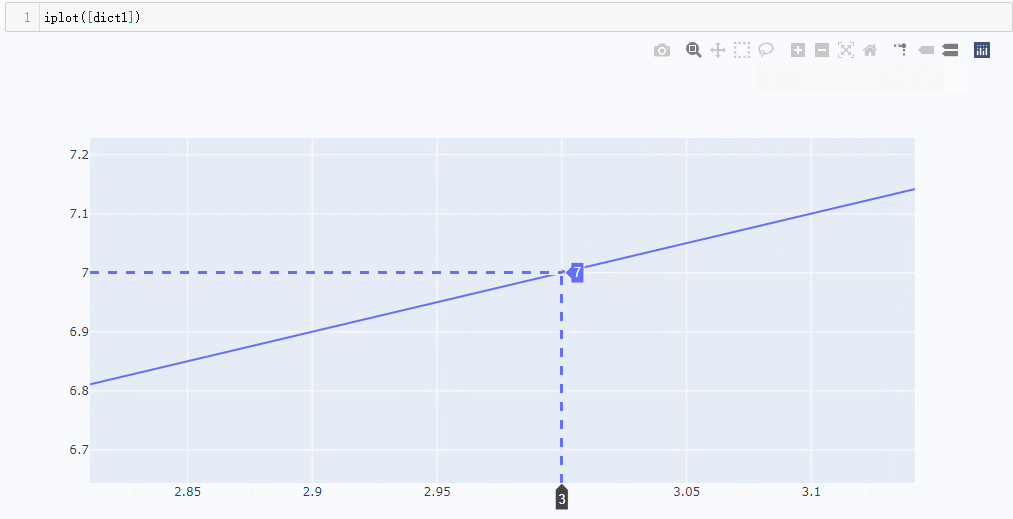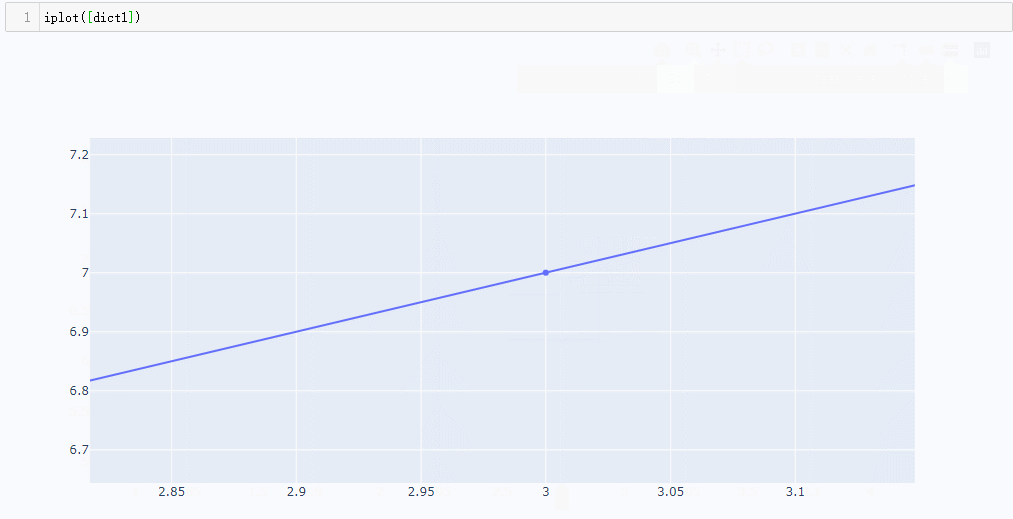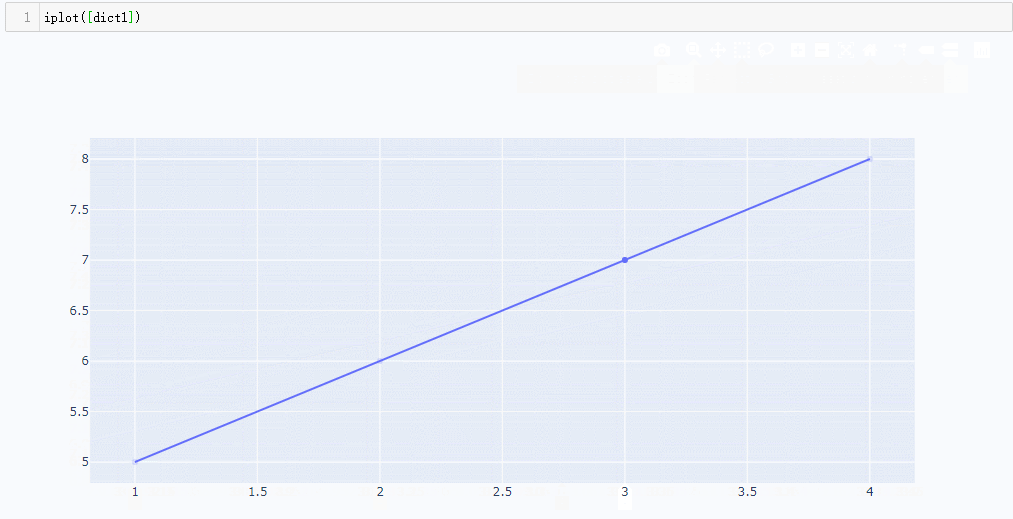
由上图我们可以看到,鼠标放上去可以互动,可以拖拽,可动的。((shfit+鼠标拖动)
#离线版,直接生成网页。
plot([dict1])
不论是iplot还是plot,里面的数据都是列表里面有个字典值。
以上是默认值,适合快速出图,想要修饰则使用go对象,可以放很多组件。且不用自己准备字典了。go 即 module ‘plotly.graph_objs’
import plotly.graph_objs as go
import numpy as np
#随机生成30个数
x = np.random.randint(0,100,size=30)
y = np.random.randint(0,100,size=30)
#go.Scatter(x=x,y=y,mode='markers') 生成iplot所需的字典结构
iplot([go.Scatter(x=x,y=y,mode='markers')])

第二节 使用Plotly绘制散点图和饼图
散点图
一种直角坐标系表示一组数据的两个变量的值的图;如果对点进行了编码(颜色、形状、大小),则可以显示一个多个附件变量。用二维展示高维信息数据。
import plotly
import plotly.graph_objs as go
from plotly.offline import download_plotlyjs , init_notebook_mode ,plot ,iplot
init_notebook_mode(connected=True)
import numpy as np
n = 1000
x= np.random.randn(n)
y= np.random.randn(n) #1.产生数据
#2.把数据放入go对象 3.创建变量存放go对象
trace=go.Scatter(x=x ,y=y,mode='markers',marker=dict(color='red',size=8))
#4.产生一个列表,可以存放超过一个以上的go对象
fig=[trace]
#5.iplot 进行绘制
iplot(fig)
Plotly绘制图形的过程,这里归纳概括为五个步骤:
- 产生数据
- 把数据放入go对象
- 创建一个data变量存放go对象
- 变量产生一个列表,可以存放超过一个以上的go对象
- iplot 进行绘制
饼图
同理,5部曲:
group = ['饮食','账单','娱乐','其他']
amount = [1000,500,1500,300]
colors = ['#d32c58','#f9b1ee','#b7f9b1','#b1f5f9']
trace =go.Pie(labels=group,values= amount)
fig=[trace]
iplot(fig)

如图鼠标放入可以显示内容(3个信息),且右侧的可以关闭选项,单独显示几项。
如果想对上图的样式做改变,可以做如下设置:
hoverinfo: 控制鼠标放上后显示的内容。上图显示了3个内容(lable、数量和占比),此时只显示两个lable和占比
textinfo: 画饼里面显示的内容,上图显示占比,此时显示数量。
==marker:==放一个字典 colors控制颜色,line控制线段为一个字典:颜色、宽度。
trace2 = go.Pie(labels=group,values= amount
,hoverinfo='label+percent',textinfo='value'
,marker=dict(colors=colors
,line=dict(color='#000000' ,width=3)))

第三节 使用自定义的数据进行plotly绘制
插曲~~~~~
#查看是否有缺损值
pubg.isna().sum()
#把所有的数据全部变为数字
df_pubg = pubg.apply(pd.to_numeric,errors='ignore')
一份吃鸡的数据
trace = go.Scatter(x= df_pubg_v2.solo_RoundsPlayed , y= df_pubg_v2.solo_Wins,name = 'Round Won' , mode = 'markers')
data = [trace]
iplot(data)

name参数的说明文档介绍,也就是设置图像的名称之后是作为图例来显示,类似之前Matplotlib绘图的label参数,即便指定了,还是需要执行plt.legend()指令让图例标签显示出来
上图中其他的一些标签等标识都没有,只有go对象其实不太好看,所以引入layout
layout = go.Layout(title ='PUBG win vs round' ,plot_bgcolor='rgb(230,230,230)' , showlegend=True)
fig = go.Figure(data=[trace],layout=layout)
iplot(fig)

有多个数据源怎么画?
trace1 = go.Bar(x = df_pubg_v3.player_name , y= df_pubg_v3.solo_RoundsPlayed,name ='Rounds Played')
trace2 = go.Bar(x = df_pubg_v3.player_name , y= df_pubg_v3.solo_Wins,name ='Rounds Won')
fig = go.Figure(data=[trace1,trace2],layout=layout)
iplot(fig)
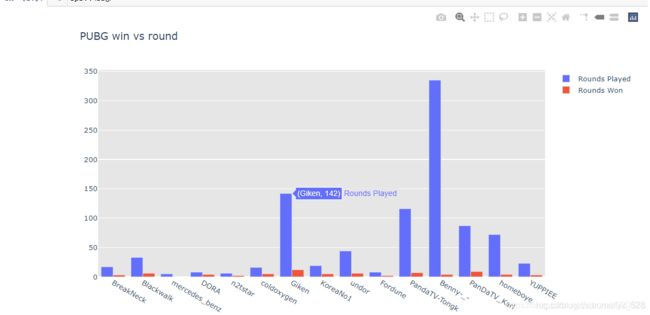
第四节 plotly高级图形的绘制
density密度图
和饼图类似,所有的数据的按照它所在的权重加起来等于100%
#取5000条数据进行测试
df_pubg_v4 = df_pubg.head(5000)
#导入绘图的模块并创建数据
import plotly.figure_factory as ff
x = df_pubg_v4.solo_Wins
y = df_pubg_v4.solo_TimeSurvived
#将x,y数据传入绘图函数中
fig =ff.create_2d_density(x ,y)
#在线显示密度图
iplot(fig)

上和右为密度辅助,密度辅助器告诉了频率,标识每个区间的数量。x,y,z.z表示面积的颜色。
3D 散点图
上节为2D模拟3D,现在直接3D.
x =df_new_pubg.solo_Wins
y = df_new_pubg.solo_TimeSurvived
z = df_new_pubg.solo_RoundsPlayed
trace1 = go.Scatter3d(
x=x,
y=y,
z=z ,
mode='markers',
marker=dict(
size=12,
color = z,
colorscale='Viridis',
opacity=0.8 ,showscale=True #showscale添加图示
)
)
data =[trace1]
plot(data)
#做一个撑足的画面
layout = go.Layout(margin=dict(
l=0,
r=0,
t=0,
b=0
))
fig = go.Figure(data=data , layout=layout)
plot(fig,filename='3d')
可见,fig包含data和layout。
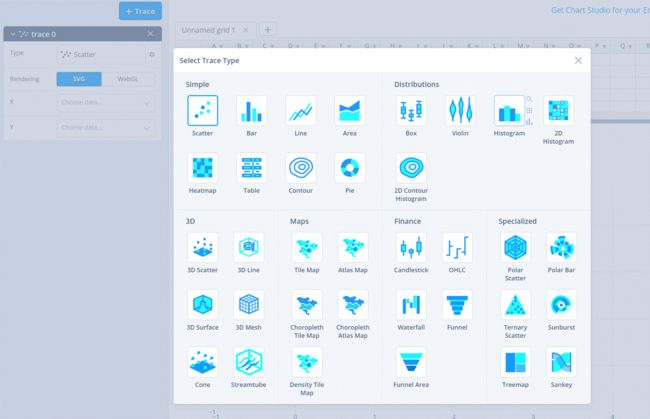
在plotly中一共有多少图呢,实际上想快速预览所有图标,用在线图库。需要安装chart_studio(!pip install chart_studio)
线上环境:chart_studio官网
使用chart_studio
sign up注册 —myfile 进入我的云盘—new chart,如下为可选择的图形
可以import数据画图,也可以notebook中连接chart-studio进行绘制图像
#安装
!pip install chart_studio
import chart_studio
apikey='qq7sRQsOutIOOfbY2uRy'
chart_studio.tools.set_credentials_file(username='mars.wang8022',api_key=apikey)
init_notebook_mode(connected=True)
import chart_studio.plotly as py
fig = go.Figure(data=data , layout=layout)
py.iplot(fig,filename='3dtest')
iplot本来是本机化的,加上py就上存到云端了。并且数据也上传了。
apikey怎么来的。
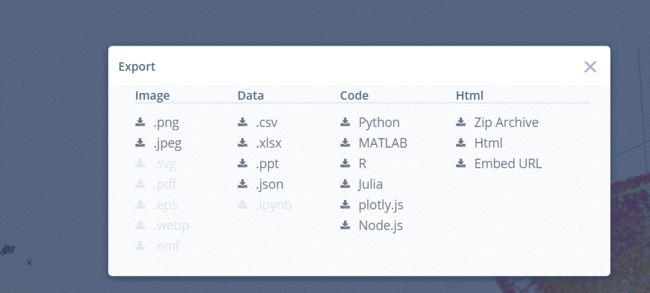
也可以查看别人的图片,并下载各种格式,查看别人写的python代码等。
第五节 Plotly绘制金融数据图
1.简单绘制
金融类数据,关注4点: 开 收 最低价 最高价
import chart_studio.plotly as py
import plotly.graph_objects as go
import pandas as pd
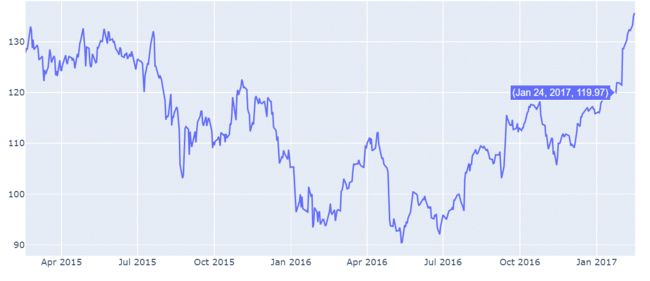
trace01 = go.Scatter(
x=df.Date,
y=df['AAPL.Close'],
)
py.iplot([trace01])
设置样式:
trace_a = go.Scatter(
x = df2.date,
y = df2.high,
name = "Tesla High",
line = dict(color = '#17BECF'),
opacity =0.8
)
py.iplot([trace_a])
go.Scatter绘制散点图,要求使用里面的mode参数,如果不指定就是默认直线连接。
opacity参数就是等同Matplotlib绘图中的alpha参数,都是指定绘制线条的透明度
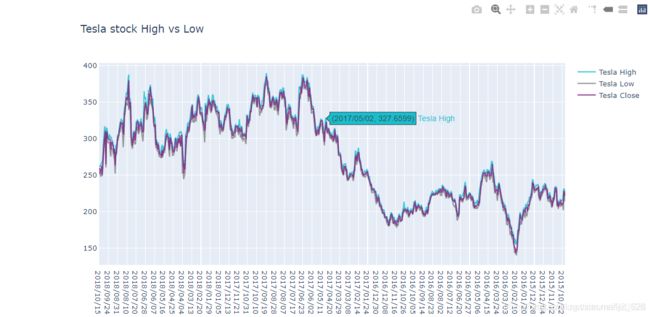
一条变化图线的基础上再添加两条图线分别代表着当日股价的最高点和最低点,同时对绘制的图像进行布局设置
trace_b = go.Scatter(
x = df2.date,
y = df2.low,
name = "Tesla Low",
line = dict(color = '#7f7f7f'),
opacity =0.8
)
trace_c = go.Scatter(
x = df2.date,
y = df2.close,
name = "Tesla Close",
line = dict(color = '#7f1f7f'),
opacity =0.8
)
layout = dict(title = "Tesla stock High vs Low")
data = [ trace_a,trace_b,trace_c]
fig = dict(data=data,layout=layout)
# fig = go.Figure(data=data,layout=layout)
iplot(fig)
**iplot()**括号中除了使用go.Figure()传递的对象,直接也可以传递一个字典。例如:fig = dict(data=data,layout=layout)
2.拖动的时间划轴
在查看时序数据中由于存在变化的范围,经常看见可以拖动的时间滑条,使用plotly也可以进行绘制。rangeslider_visible
import plotly.express as px
fig = px.line(df2 , x='date',y='close')
#fig.update_yaxes() 对y轴进行绘制
fig.update_xaxes(rangeslider_visible=True)
fig.show()
步骤如下:
(1)导入绘制的模块:import plotly.express as px
(2)绘制变化的折线:fig = px.line(df2 , x=‘date’,y=‘close’)
(3)更新x轴信息添加范围变化条:fig.update_xaxes(rangeslider_visible=True)
(4)显示最终图片:fig.show()
上图可见,随着X轴的变化,上方网格也产生了相应的变化。
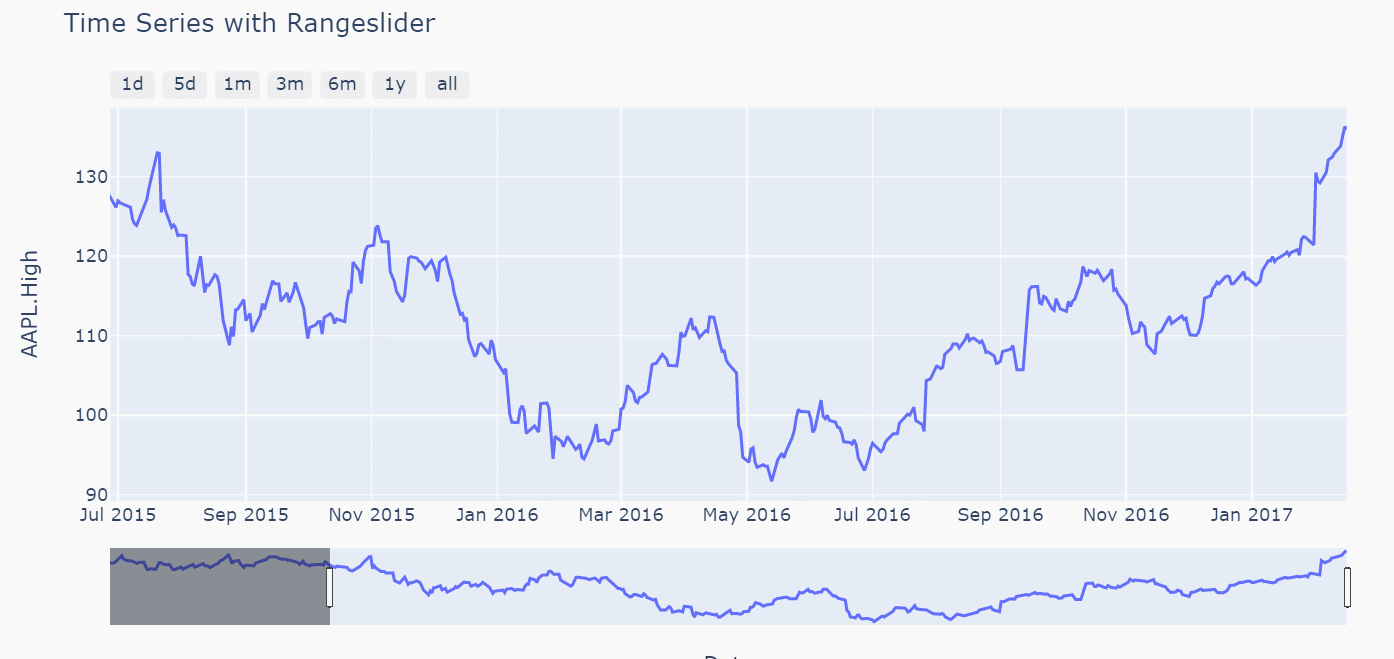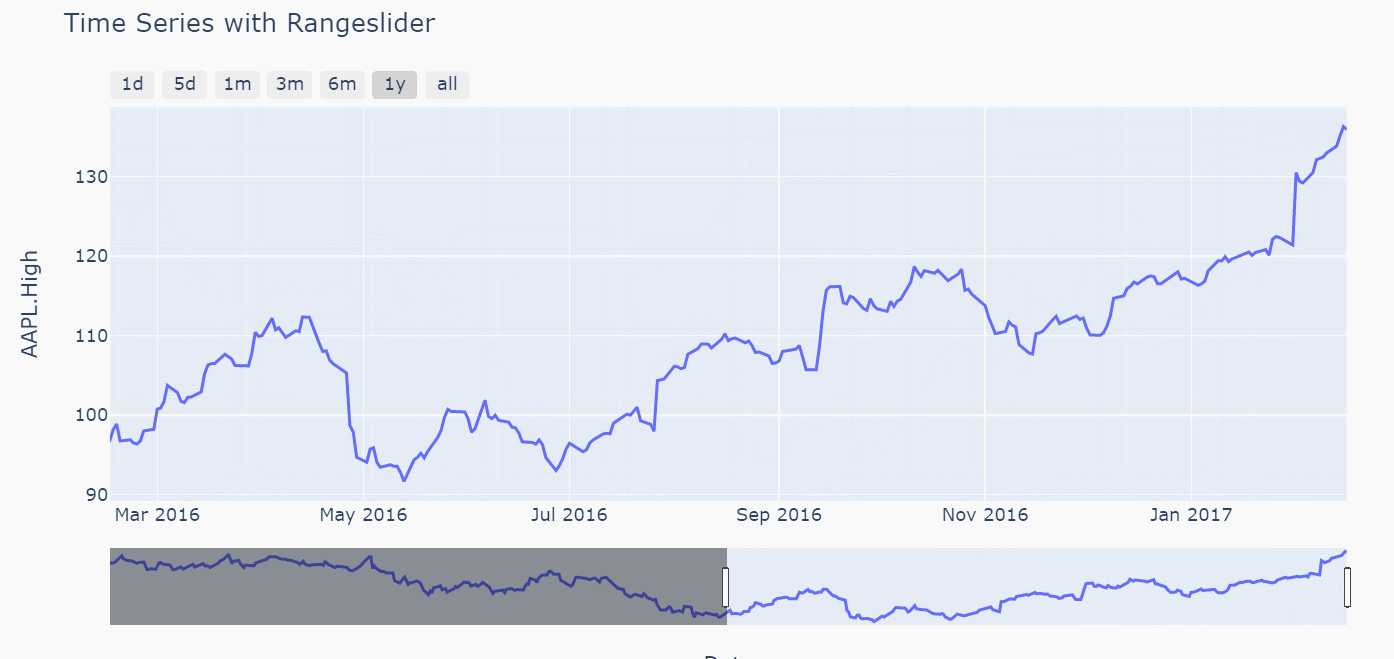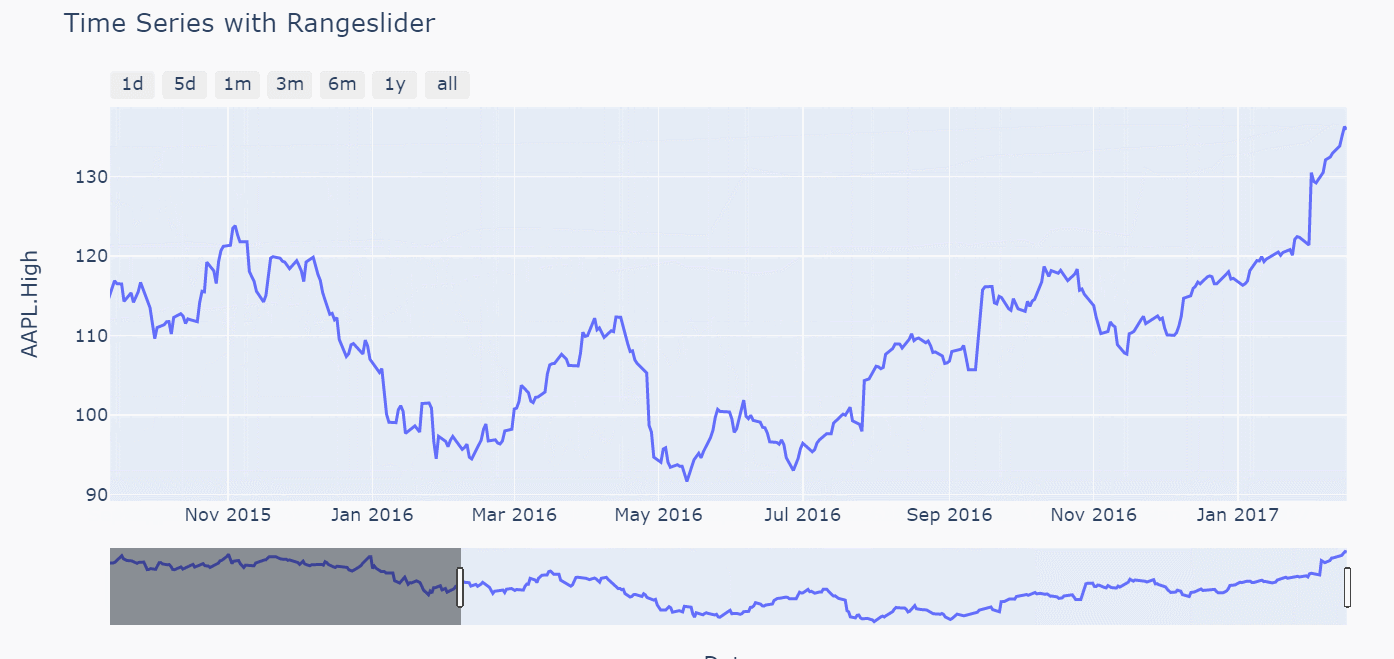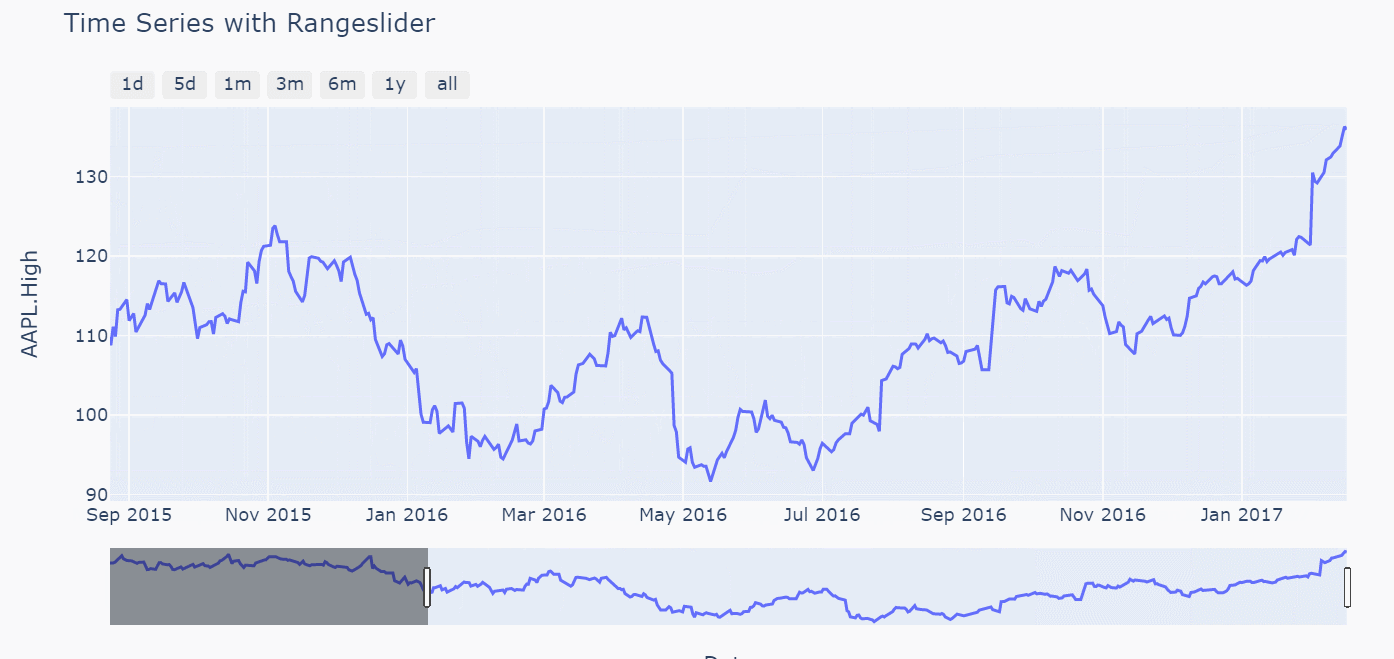
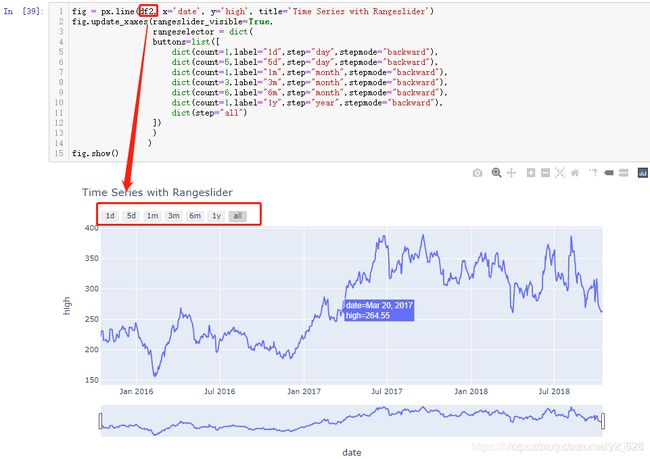
时间快速选择按钮
除了添加手动拖动的时间滑条外,也可以增加固定时间的转换器,这需要update_xaxes使用到 rangeselector参数,具体赋值要求为字典,对应的键就是切换器对应的按钮button,然后值就是要进行切换的时间点。
fig = px.line(df, x='Date', y='AAPL.High', title='Time Series with Rangeslider')
fig.update_xaxes(rangeslider_visible=True,
rangeselector = dict(
buttons=list([
dict(count=1,label="1d",step="day",stepmode="backward"),
dict(count=5,label="5d",step="day",stepmode="backward"),
dict(count=1,label="1m",step="month",stepmode="backward"),
dict(count=3,label="3m",step="month",stepmode="backward"),
dict(count=6,label="6m",step="month",stepmode="backward"),
dict(count=1,label="1y",step="year",stepmode="backward"),
dict(step="all")
])
)
)
fig.show()
以下转自 原文链接:https://blog.csdn.net/lys_828/article/details/119516045
接下来就是一种很重要的知识点,日后经常使用可以提高编程效率,就是试错法。上面代码中还有一个参数没有提及stepmode,参看说明文档如下,其中没有关于这个参数的使用说明,甚至连rangeselector参数的使用说明都没有
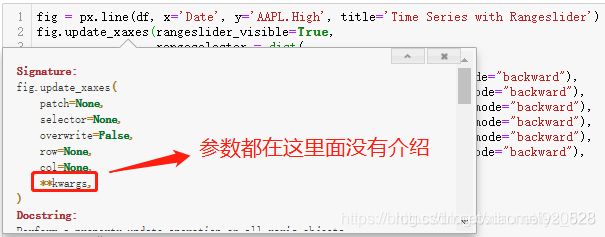
此时最快捷的方式不是去百度翻各种帖子或者是直接找官方更详细的说明文档,这时候应该用一下试错的方式,既然这个参数赋值了backward,那么对应是不是应该有一个选项是forward与之对应?就按照这种猜想进行试错,输出结果如下(输出结果报错,但是报错是有价值的,告诉了我们这个参数具体什么意思以及可以使用的赋值对象)
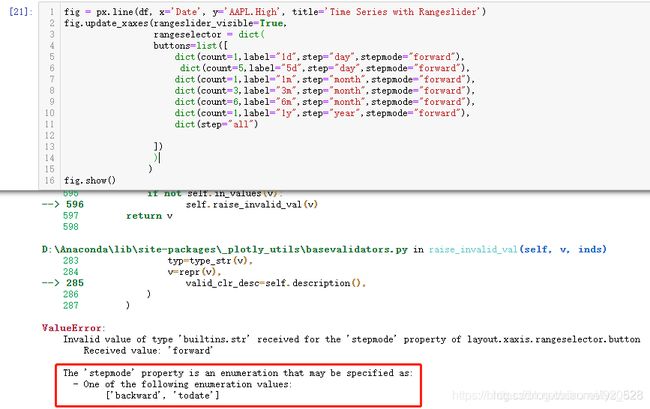
The ‘stepmode’ property is an enumeration直接翻译过来就是一个计数器(枚举器),具体如何枚举的?就有两种方式分别对应backward,todate。两个赋值对象的差别最直观的方式就是进行绘图,看一下出图的不同,然后根据内容显示的不同就知道这个复制对象的具体含义
对于1d和5d两个图形都是保持一致(以5d为例做出对比图)

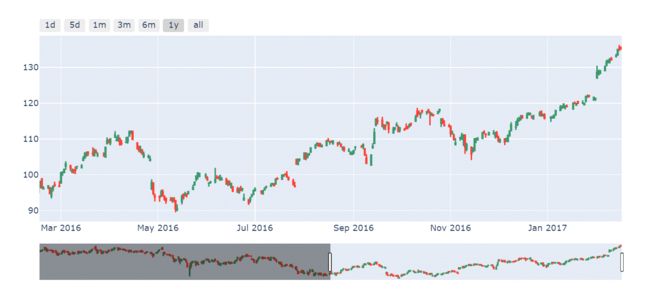
在后面的几个时间转换器中差别就体现出来了(比如以1m和1y为例,3m,6m两个参数的差别也是同理)

注意对比上图关于指定1m的区间两者下方的滑动条范围以及图像左右两侧的时间标记,backward参数绘图中时间跨度是1个月完整的天数,但是todate参数绘图时间跨度只会到指定时间的当前月份的第一天,而不是一个完整的天数,比如这里数据最后一条的时间是2017年2月16,前者1m转换器的区间是[2017-1-16,2017-2-16],后者1m转换器的区间是[2017-2-1,2017-2-16]。由此两个参数对应的枚举方式的差别也就体现出来了,那么在用1y转换器出的图形进行验证,如下(前者输出的时间区间为[2016-2-16,2017-2-16],后者者输出的时间区间为[2017-1-1,2017-2-16],验证无误)

至此关于试错法的运用收获良多,也通过出图对比了两者之间的差别,此外绘制这个图形对应时间数据的格式是有要求的,经过测试发现只有datetime数据类型或者是xxxx-xx-xx字符串数据的时间是可以生成转换器,否则最后达不到效果
比如不使用Apple的股价数据,而是使用特斯拉的股价数据,两者都是有时间字段的数据,前者df的时间字段符合xxxx-xx-xx字符串数据的时间,但是df2中的时间字段不符合
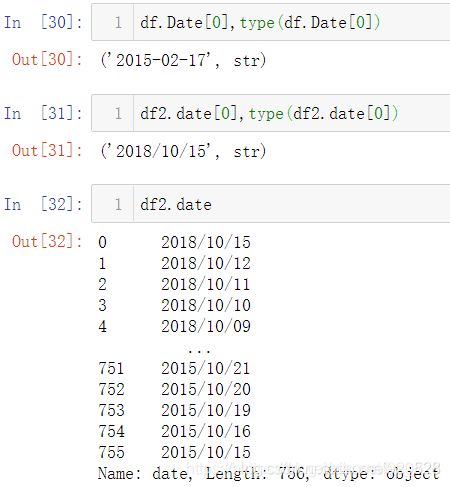
那么直接使用df2的数据进行绘制,看看效果图(最终是没有出现转换器的按钮)

可能细心点的同学注意到了x轴的时间区间范围是反了,会不会是这个原因导致的,可以尝试把df2按照时间字段反序后再进行绘制,真是个好想法,这样严格的对比测试才能真正的找出问题所在
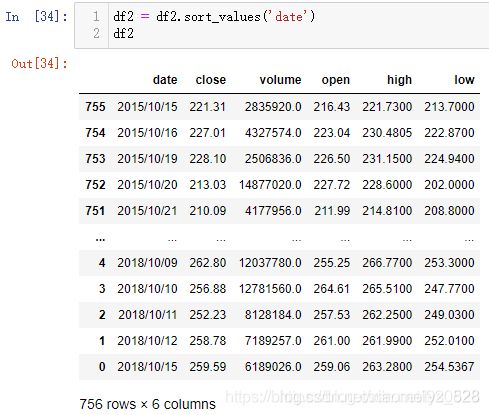
已经将时间顺序进行反序,然后再进行图像的绘制,最后的输出结果中仍然没有转换器的按钮(时间字段的数据类型还是字符串没有进行数据类型的转化)
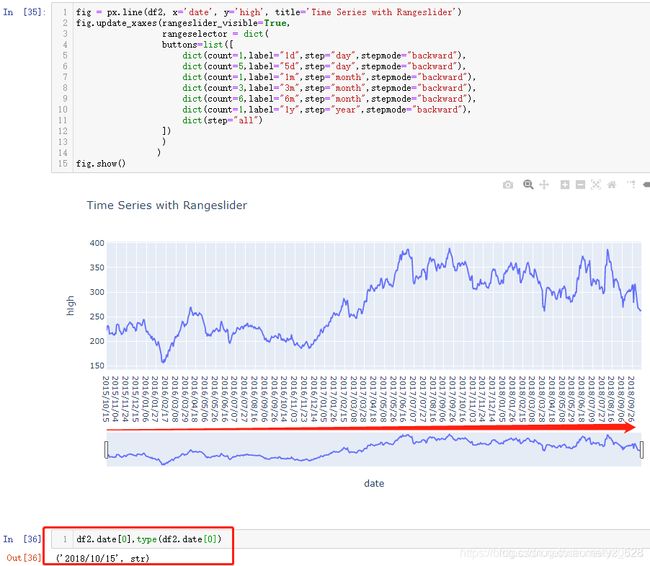
接下来就是见证奇迹的时刻,将df2时间字段的数据类型转化为datetime数据类型
绘制的图像如下:(由此关于添加时间转换器按钮部分全部的坑以及相对应细节全部介绍完毕)
3.绘制蜡烛图
trace03= go.Candlestick(x=df['Date'],
open=df['AAPL.Open'],
high=df['AAPL.High'],
low=df['AAPL.Low'],
close=df['AAPL.Close'])
data =[trace03]
iplot(data)

如果要添加时间转换器按钮,可以将原来的代码直接复制粘贴过来即可,都不用进行修改,运行结果如下
###注意一下写法 很特殊
fig = go.Figure(data=[go.Candlestick(x=df['Date'],
open=df['AAPL.Open'],
high=df['AAPL.High'],
low=df['AAPL.Low'],
close=df['AAPL.Close'])])
fig.update_xaxes(rangeslider_visible=True,
rangeselector = dict(
buttons=list([
dict(count=1,label="1d",step="day",stepmode="backward"),
dict(count=5,label="5d",step="day",stepmode="backward"),
dict(count=1,label="1m",step="month",stepmode="backward"),
dict(count=3,label="3m",step="month",stepmode="backward"),
dict(count=6,label="6m",step="month",stepmode="backward"),
dict(count=1,label="1y",step="year",stepmode="backward"),
dict(step="all")
])
)
)
fig.show()
4.使用cufflinks模块绘制金融指标图
(1)趋势图
需要导入模块和加载数据后构建QuantFig函数对象,其中前两行作为默认代码导入,会自动加载相应的配置文件信息。模块自带的有测试数据,可以直接读取。将df通过QuantFig函数处理后会自动转化为字典数据格式,有些类似前面的go构造器
!pip install cufflinks
import cufflinks as cf
#设置为脱机使用
cf.set_config_file(offline=True,world_readable=True)
df= cf.datagen.ohlc()
qf=cf.QuantFig(df)
qf.iplot()
qf如下:
{
“_d”: {
“close”: “close”,
“high”: “high”,
“low”: “low”,
“open”: “open”
},
“data”: {
“datalegend”: true,
“kind”: “candlestick”,
“name”: “Trace 1”,
“resample”: null,
“slice”: [
null,
null
]
},
“kwargs”: {},
“layout”: {
“annotations”: {
“params”: {},
“values”: []
},
“margin”: {
“b”: 30,
“l”: 30,
“r”: 30,
“t”: 30
},
“rangeselector”: {
“visible”: false
},
“rangeslider”: false,
“shapes”: {},
“showlegend”: true
},
“panels”: {
“bottom_margin”: 0,
“min_panel_size”: 0.15,
“spacing”: 0.08,
“top_margin”: 0.9
},
“studies”: {},
“theme”: {
“down_color”: “grey”,
“theme”: “pearl”,
“up_color”: “#17BECF”
},
“trendlines”: []
}
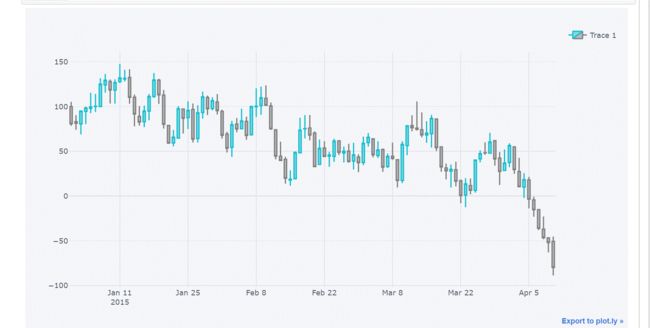
(2)绘制MACD指标图
每一个交点都是交易点
qf.add_macd()
qf.iplot()
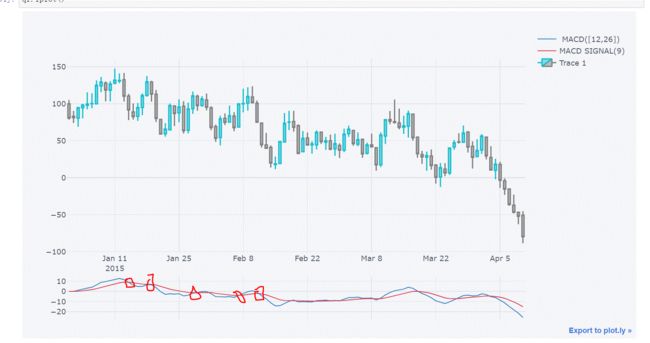
(3)绘制RSI指标图
qf.add_rsi(6,80)
qf.iplot()
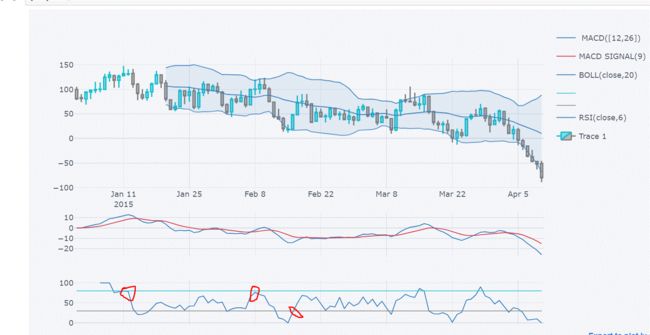
(4)绘制布林带指标图
qf.add_bollinger_bands()
qf.iplot()

第六节 绘制高级散点图和热力图
1.使用heatmap绘制热力图
核心代码:
import plotly.express as px
px.density_heatmap()
导入代码块
import pandas as pd
import numpy as np
import chart_studio.plotly as py
import cufflinks as cf
import seaborn as sns
import plotly.express as px
%matplotlib inline
from plotly.offline import download_plotlyjs, init_notebook_mode, plot, iplot
init_notebook_mode(connected=True)
数据源(年 月 乘机人数)以及绘制
flights = sns.load_dataset('flights')
fig=px.density_heatmap(flights,x='year',y='month',z='passengers')
fig
flights = sns.load_dataset(‘flights’)
如果获取不到数据,就先前往https://github.com/mwaskom/seaborn-data下载所有的数据集合,点击下方图像上的Clone or download就可以下载,下载完后就是压缩包需要解压。然后jupter’中上传flights文件。改为flights = pd.read_csv(‘flights.csv’)

可以看到1958年7 8 月份乘机人数最多,随着年份的增长,乘机人数慢慢增多。
也可以使用marginal_x=‘histogram’,marginal_y='histogram’在两侧放直方图统计图表。
fig=px.density_heatmap(flights,x='year',y='month',z='passengers',marginal_x='histogram' ,marginal_y='histogram')
fig

除了用2D热力图表示三维信息外,也可以直接使用三维折线图进行展示。
fig=px.line_3d(flights,x='year',y='month',z='passengers',color='year')
fig
从3d空间中可以分别看到月份和乘机人数的关系以及年份和乘机人数的关系。
设置样式:边距等等。
fig2=px.line_3d(flights,x='year',y='month',z='passengers',color='year')
fig2.update_layout(
autosize=False,
width=900,
height=500,
margin=dict(
l=0,
r=0,
b=0,
t=0,
pad=0
),
# paper_bgcolor="LightSteelBlue",
)
fig2
2.使用scatter功能绘制散点图
核心代码:px.scatter_3d
fig2=px.scatter_3d(flights,x='year',y='month',z='passengers',color='year')
fig2.update_layout(
autosize=False,
width=900,
height=500,
margin=dict(
l=0,
r=0,
b=0,
t=0,
pad=0
),
# paper_bgcolor="LightSteelBlue",
)
fig2

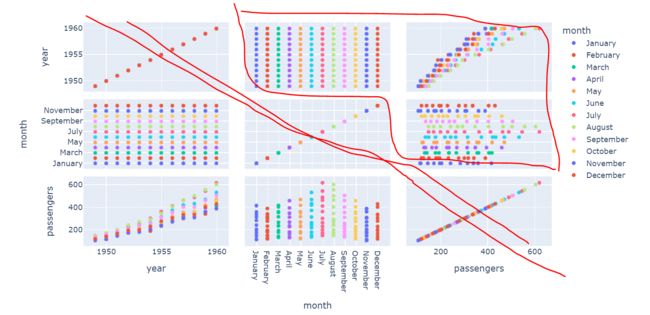
3.使用scatter_matrix功能绘制散点矩阵
**核心代码:**px.scatter_matrix()
3个字段,,3*3共9个图。表示了每个字段间的关系。为了视觉冲击,增加了颜色。对角线是自己与自己比,不用看。上三角与下三角是旋转90度的关系,所以只需要看上三角。
fig = px.scatter_matrix(flights,color="month")
fig
花卉练习
df = px.data.iris()
fig = px.scatter_matrix(df,color="species")
fig
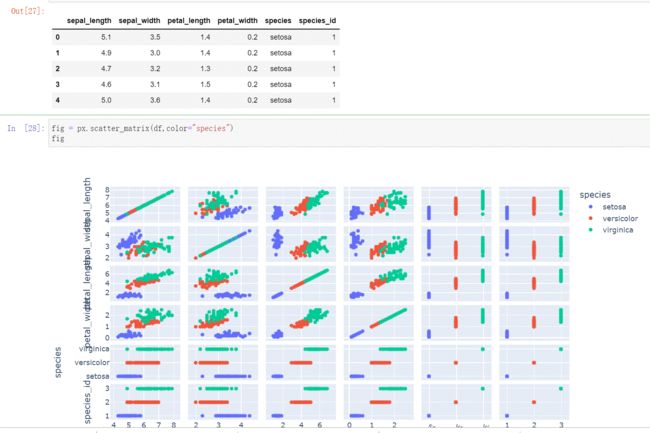
其中,后两列是我们不需要的数据,可以裁剪掉
df2=df.iloc[:,:4]
fig = px.scatter_matrix(df2)
fig
但是这样又没有标签,不能颜色信息,不能做区分。这是可以使用dimensions属性,存放我们需要的列信息。
fig = px.scatter_matrix(df,dimensions=["sepal_width", "sepal_length", "petal_width", "petal_length"],color="species")
fig

从上图可以看出petal_length和sepal_length比较能区分。这是可以是使用scatter查看2d分布或者使用 px.scatter_3d显示3d分布信息。
fig = px.scatter(df , x ='petal_length' , y='sepal_length' , color='species' ,size='petal_length')
fig
fig = px.scatter_3d(df , x ='petal_length' , y='sepal_length', z ='sepal_width' , color='species' ,size='petal_length')
fig
4.使用scatter_geo功能绘制地理分布图
核心代码:px.scatter_geo()
数据集:2007年全球gdp数据。要求给出的数据中必须要有一个公共的字段,且这个字段的地理信息字段iso_alpha,比如国家的简写,中国China对应CHN。
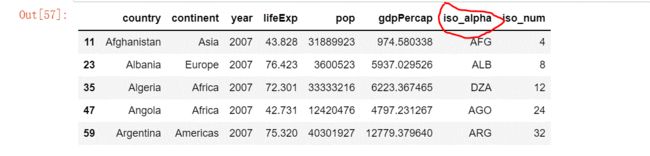
df = px.data.gapminder().query("year == 2007")
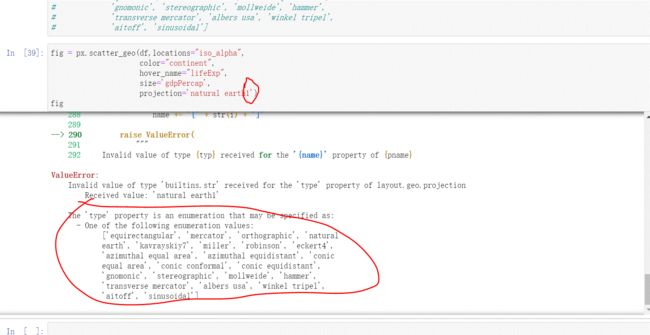
ig = px.scatter_geo(df,locations="iso_alpha",
color="continent",
hover_name="lifeExp",
size='gdpPercap',
projection='natural earth')
fig
 小提示:
小提示:
location参数就是要指定的合并依据的地理信息字段,color和size参数用的多了就习惯了,hover_name就是交互时提示框显示的信息,就差最后一个参数project,这里就可以使用试错法,不知道这个参数到底应该怎么赋值,可以随便写一个或者猜一个单词,报错信息就可以知道应该写些什么值。
完成于七夕情人节,是我们的双节。撒花。下一节:Plotly绘图进阶篇,使用plotly进行地图和动态数据的绘制