Linux kprobe原理
文章目录
- 前言
- 一、Kprobes and Return Probes
- 二、How Does a Kprobe Work
- 三、do_int3/bug函数
-
- 3.1 init_kprobes
- 3.2 do_int3
- 3.3 do_bug
- 四、Changing Execution Path
- 五、Return Probes
-
- 5.1 How Does a Return Probe Work
- 5.2 Kretprobe entry-handler
- 六、How Does Jump Optimization Work
-
- 6.1 Init a Kprobe
- 6.2 Safety Check
- 6.3 Preparing Detour Buffer
- 6.4 Pre-optimization
- 6.5 Optimization
- 6.6 Unoptimization
- 6.7 Blacklist
- 6.8 try_to_optimize_kprobe
- 参考资料
前言
关于kprobe和kretprobe的使用请参考:
Linux kprobe的使用
Linux kretprobe使用和原理
一、Kprobes and Return Probes
Kprobes 使您能够动态地中断任何内核例程并无中断地收集调试和性能信息,可以在内核的绝大多数指定函数中动态插入探测点来收集所需的调试状态信息而基本不影响内核原有的执行流程,Kprobes不用修改内核源码,是指令集的探测技术。
kprobe 是一种动态调试机制,用于debugging,动态跟踪,性能分析,动态修改内核行为等
内核代码的某些部分不能被捕获,既不能被探测,不能探测的点位于 blacklist 中 :
内核用双向链表组织各个不能探测点:
/* Blacklist -- list of struct kprobe_blacklist_entry */
static LIST_HEAD(kprobe_blacklist);
struct kprobe_blacklist_entry {
struct list_head list;
unsigned long start_addr;
unsigned long end_addr;
};
// include/asm-generic/vmlinux.lds.h
#ifdef CONFIG_KPROBES
#define KPROBE_BLACKLIST() . = ALIGN(8); \
VMLINUX_SYMBOL(__start_kprobe_blacklist) = .; \
KEEP(*(_kprobe_blacklist)) \
VMLINUX_SYMBOL(__stop_kprobe_blacklist) = .;
/* init and exit section handling */
#define INIT_DATA \
...... \
*(.init.rodata) \
FTRACE_EVENTS() \
TRACE_SYSCALLS() \
KPROBE_BLACKLIST()
目前有两种类型的探测:kprobes和kretprobes(也称为返回探测)。实际上,kprobe可以插入到内核中的任何指令上。当指定的函数返回时,将触发一个返回探测。
在通常情况下,基于 Kprobes 的检测被打包为内核模块。 模块的 init 函数安装(“注册”)一个或多个探测器,而 exit 函数取消注册它们。 诸如 register_kprobe() 之类的注册函数指定要插入探针的位置以及命中探针时要调用的处理程序。
register_/unregister_*probes() 函数用于批量注册/注销一组 *probes:
int register_kprobes(struct kprobe **kps, int num)
{
int i, ret = 0;
if (num <= 0)
return -EINVAL;
for (i = 0; i < num; i++) {
ret = register_kprobe(kps[i]);
if (ret < 0) {
if (i > 0)
unregister_kprobes(kps, i);
break;
}
}
return ret;
}
EXPORT_SYMBOL_GPL(register_kprobes);
void unregister_kprobes(struct kprobe **kps, int num)
{
int i;
if (num <= 0)
return;
mutex_lock(&kprobe_mutex);
for (i = 0; i < num; i++)
if (__unregister_kprobe_top(kps[i]) < 0)
kps[i]->addr = NULL;
mutex_unlock(&kprobe_mutex);
synchronize_sched();
for (i = 0; i < num; i++)
if (kps[i]->addr)
__unregister_kprobe_bottom(kps[i]);
}
EXPORT_SYMBOL_GPL(unregister_kprobes);
接下来的描述不同类型的探针如何工作以及跳转优化如何工作,解释了为了充分利用 Kprobes 需要了解的某些事情——例如,pre_handler 和 post_handler 之间的区别,以及如何使用 kretprobe 的 maxactive 和 nmissed 字段。
二、How Does a Kprobe Work
注册 kprobe 后,Kprobes 会复制被探测的指令,并用断点指令(例如 i386 和 x86_64 上的 int3)替换被探测指令的第一个字节。
当 CPU 遇到断点指令时,会发生陷阱,保存 CPU 的寄存器,并通过 notifier_call_chain 机制将控制权传递给 Kprobes。 Kprobes 在函数 kprobe_handler中 执行与 kprobe 相关的“pre_handler”,将 kprobe 结构的地址和保存的寄存器传递给处理程序。
接下来,Kprobes 单步执行其探测指令的副本。 (单步执行实际指令会更简单,但 Kprobes 将不得不暂时删除断点指令,这将打开一个小的时间窗口,此时另一个 CPU 可以直接越过探测点。)
在指令单步执行后,会产生debug异常,Kprobes 执行与 kprobe 关联的“post_handler”(如果有), 然后继续执行探测点之后的指令。
通知链机制:
大多数内核子系统都是相互独立的,因此某个子系统可能对其它子系统产生的事件感兴趣。为了满足这个需求,也即是让某个子系统在发生某个事件时通知其它的子系统,Linux内核提供了通知链的机制。通知链表只能够在内核的子系统之间使用,而不能够在内核与用户空间之间进行事件的通知。
系统遇到int3断点时,执行do_int3函数,然后执行通知链上的回调函数kprobe_exceptions_notify,对于int 3 指令就是kprobe_handler函数,然后执行用户态的回调函数pre_handler。
系统遇到debug异常时,执行do_debug函数,然后执行通知链上的回调函数kprobe_exceptions_notify,对于debug 指令就是post_kprobe_handler函数,然后执行用户态的回调函数post_handler 。
小结:
kprobe原理类似与GDB中断点调试和单步调试:
对于x86平台涉及到cpu的两个异常机制指令就是:断点异常 int3 指令,debug 中的单步异常 int1 指令。
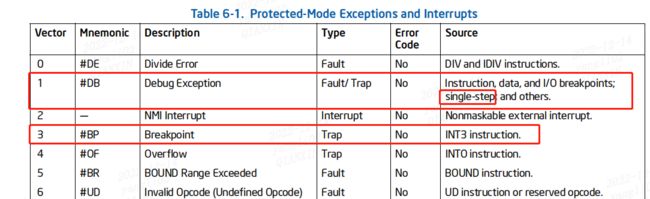
由英特尔手册可以看到debug异常(单步异常是debug异常中的一种)是中断向量表的vector1,断点异常是中断向量表中的vector3。
(1)Kprobe把探测点的指令替换成断点指令BREAKPOINT,执行到探测点以后,系统会陷入断点异常int3,触发了一个trap,执行kprobe_handler函数,在kprobe_handler中执行pre_handler函数,trap处理流程中会保存当前CPU的寄存器信息并调用对应的trap处理函数,该处理函数会设置kprobe的调用状态并调用用户注册的pre_handler回调函数,kprobe会向该函数传递注册的struct kprobe结构地址以及保存的CPU寄存器信息。
(2)然后把cpu设置为单步模式继续执行探测点原有的指令,原有指令执行完成以后又会陷入单步异常int1(EFLAGS 寄存器TF位被设置后,每执行一条指令就会触发debug异常)。
(3)在int1的函数do_debug中继续调用post_handler,并恢复单步模式到正常模式,然后返回继续执行探测点后续的指令。
kprobe pre_handler:在执行 the probed instruction 之前调用,在 do_int3 中执行。
kprobe post_handler:在执行 the probed instruction 后调用,在 do_debug 中执行。
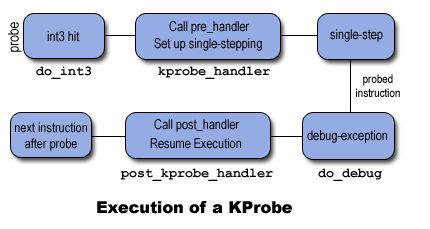
三、do_int3/bug函数
3.1 init_kprobes
kprobes作为一个内核中的一个模块,init_kprobes函数用来初始化kprobes模块:
// linux-3.10/kernel/kprobes.c
#define KPROBE_HASH_BITS 6
#define KPROBE_TABLE_SIZE (1 << KPROBE_HASH_BITS)
static struct hlist_head kprobe_table[KPROBE_TABLE_SIZE];
static struct hlist_head kretprobe_inst_table[KPROBE_TABLE_SIZE];
static struct {
raw_spinlock_t lock ____cacheline_aligned_in_smp;
} kretprobe_table_locks[KPROBE_TABLE_SIZE];
static int __init init_kprobes(void)
{
int i, err = 0;
unsigned long offset = 0, size = 0;
char *modname, namebuf[128];
const char *symbol_name;
void *addr;
struct kprobe_blackpoint *kb;
/* FIXME allocate the probe table, currently defined statically */
/* initialize all list heads */
for (i = 0; i < KPROBE_TABLE_SIZE; i++) {
INIT_HLIST_HEAD(&kprobe_table[i]);
INIT_HLIST_HEAD(&kretprobe_inst_table[i]);
raw_spin_lock_init(&(kretprobe_table_locks[i].lock));
}
/*
* Lookup and populate the kprobe_blacklist.
*
* Unlike the kretprobe blacklist, we'll need to determine
* the range of addresses that belong to the said functions,
* since a kprobe need not necessarily be at the beginning
* of a function.
*/
for (kb = kprobe_blacklist; kb->name != NULL; kb++) {
kprobe_lookup_name(kb->name, addr);
if (!addr)
continue;
kb->start_addr = (unsigned long)addr;
symbol_name = kallsyms_lookup(kb->start_addr,
&size, &offset, &modname, namebuf);
if (!symbol_name)
kb->range = 0;
else
kb->range = size;
}
if (kretprobe_blacklist_size) {
/* lookup the function address from its name */
for (i = 0; kretprobe_blacklist[i].name != NULL; i++) {
kprobe_lookup_name(kretprobe_blacklist[i].name,
kretprobe_blacklist[i].addr);
if (!kretprobe_blacklist[i].addr)
printk("kretprobe: lookup failed: %s\n",
kretprobe_blacklist[i].name);
}
}
#if defined(CONFIG_OPTPROBES)
#if defined(__ARCH_WANT_KPROBES_INSN_SLOT)
/* Init kprobe_optinsn_slots */
kprobe_optinsn_slots.insn_size = MAX_OPTINSN_SIZE;
#endif
/* By default, kprobes can be optimized */
kprobes_allow_optimization = true;
#endif
/* By default, kprobes are armed */
kprobes_all_disarmed = false;
err = arch_init_kprobes();
if (!err)
err = register_die_notifier(&kprobe_exceptions_nb);
if (!err)
err = register_module_notifier(&kprobe_module_nb);
kprobes_initialized = (err == 0);
if (!err)
init_test_probes();
return err;
}
module_init(init_kprobes);
(1)分配当前静态定义的探测表,初始化所有的哈希链表头。并初始化kretprobe用到的自旋锁。
(2)查找并填充kprobe_blacklist,与kretprobe blacklist不同的是,我们需要确定属于所述函数的地址范围,因为kprobe不一定位于函数的开头(kprobe可以插入到内核中的任何指令上,不一定是函数开头)。
函数前面加__kprobes修饰的不能被探测,比如:
/*
* This routine is called either:
* - under the kprobe_mutex - during kprobe_[un]register()
* OR
* - with preemption disabled - from arch/xxx/kernel/kprobes.c
*/
struct kprobe __kprobes *get_kprobe(void *addr)
{
struct hlist_head *head;
struct kprobe *p;
head = &kprobe_table[hash_ptr(addr, KPROBE_HASH_BITS)];
hlist_for_each_entry_rcu(p, head, hlist) {
if (p->addr == addr)
return p;
}
return NULL;
}
下面这一些函数也不能被探测:
/*
* Normally, functions that we'd want to prohibit kprobes in, are marked
* __kprobes. But, there are cases where such functions already belong to
* a different section (__sched for preempt_schedule)
*
* For such cases, we now have a blacklist
*/
static struct kprobe_blackpoint kprobe_blacklist[] = {
{"preempt_schedule",},
{"native_get_debugreg",},
{"irq_entries_start",},
{"common_interrupt",},
{"mcount",}, /* mcount can be called from everywhere */
{NULL} /* Terminator */
};
(3)查找并填充retkprobe_blacklist。
struct kretprobe_blackpoint kretprobe_blacklist[] = {
{"__switch_to", }, /* This function switches only current task, but
doesn't switch kernel stack.*/
{NULL, NULL} /* Terminator */
};
const int kretprobe_blacklist_size = ARRAY_SIZE(kretprobe_blacklist);
(4)注册 die 通知链
注册内核通知链:kprobe_exceptions_nb,注释标明了该通知链最高,最先被调用,执行被探测指令期间若发生了内存异常,比如执行了int3指令, 将最优先调用kprobe_exceptions_notify函数。
static struct notifier_block kprobe_exceptions_nb = {
.notifier_call = kprobe_exceptions_notify,
.priority = 0x7fffffff /* we need to be notified first */
};
register_die_notifier(&kprobe_exceptions_nb);
/*
* Wrapper routine for handling exceptions.
*/
int __kprobes
kprobe_exceptions_notify(struct notifier_block *self, unsigned long val, void *data)
{
struct die_args *args = data;
int ret = NOTIFY_DONE;
if (args->regs && user_mode_vm(args->regs))
return ret;
switch (val) {
case DIE_INT3:
if (kprobe_handler(args->regs))
ret = NOTIFY_STOP;
break;
case DIE_DEBUG:
if (post_kprobe_handler(args->regs)) {
/*
* Reset the BS bit in dr6 (pointed by args->err) to
* denote completion of processing
*/
(*(unsigned long *)ERR_PTR(args->err)) &= ~DR_STEP;
ret = NOTIFY_STOP;
}
break;
case DIE_GPF:
/*
* To be potentially processing a kprobe fault and to
* trust the result from kprobe_running(), we have
* be non-preemptible.
*/
if (!preemptible() && kprobe_running() &&
kprobe_fault_handler(args->regs, args->trapnr))
ret = NOTIFY_STOP;
break;
default:
break;
}
return ret;
}
(5)注册模块通知链
除了内核中的代码段函数外,还有模块中的代码段,我们可以给模块中的函数添加 kprobe点,当模块被卸载时,模块的.text 和.init.text sections都被释放,移除模块中的 kprobe点,当模块加载时,可以给模块的.text添加kprobe点,但是模块的.init.text sections再加载后就被释放,因此要禁止.init.text sections的kprobe点。
模块正常运行(已经完成了模块的初始化)的状态是MODULE_STATE_LIVE。
模块卸载是状态是MODULE_STATE_GOING。
/* Module notifier call back, checking kprobes on the module */
static int __kprobes kprobes_module_callback(struct notifier_block *nb,
unsigned long val, void *data)
{
struct module *mod = data;
struct hlist_head *head;
struct kprobe *p;
unsigned int i;
int checkcore = (val == MODULE_STATE_GOING);
if (val != MODULE_STATE_GOING && val != MODULE_STATE_LIVE)
return NOTIFY_DONE;
/*
* When MODULE_STATE_GOING was notified, both of module .text and
* .init.text sections would be freed. When MODULE_STATE_LIVE was
* notified, only .init.text section would be freed. We need to
* disable kprobes which have been inserted in the sections.
*/
mutex_lock(&kprobe_mutex);
for (i = 0; i < KPROBE_TABLE_SIZE; i++) {
head = &kprobe_table[i];
hlist_for_each_entry_rcu(p, head, hlist)
if (within_module_init((unsigned long)p->addr, mod) ||
(checkcore &&
within_module_core((unsigned long)p->addr, mod))) {
/*
* The vaddr this probe is installed will soon
* be vfreed buy not synced to disk. Hence,
* disarming the breakpoint isn't needed.
*/
kill_kprobe(p);
}
}
mutex_unlock(&kprobe_mutex);
return NOTIFY_DONE;
}
static struct notifier_block kprobe_module_nb = {
.notifier_call = kprobes_module_callback,
.priority = 0
};
register_module_notifier(&kprobe_module_nb)
注册module notify回调kprobes_module_callback函数的作用是若当某个内核模块发生卸载操作时有必要检测并移除注册到该模块函数的探测点。
当模块处于加载状态时,由于模块的.init.text节在加载后就被释放,不会存留在内存中,因此不能再.init.text节添加 kprobe点。
当模块的状态等于MODULE_STATE_GOING时,模块的.text 和.init.text sections都要禁用kprobe点。
val = MODULE_STATE_GOING
if (within_module_init((unsigned long)p->addr, mod) ||
within_module_core((unsigned long)p->addr, mod)) {
/*
* The vaddr this probe is installed will soon
* be vfreed buy not synced to disk. Hence,
* disarming the breakpoint isn't needed.
*/
kill_kprobe(p);
}
当模块的状态等于MODULE_STATE_LIVE时,模块的.init.text sections要禁用kprobe点。
val = MODULE_STATE_LIVE
if (within_module_init((unsigned long)p->addr, mod)) {
/*
* The vaddr this probe is installed will soon
* be vfreed buy not synced to disk. Hence,
* disarming the breakpoint isn't needed.
*/
kill_kprobe(p);
}
3.2 do_int3
前面说到系统执行到探测点以后,系统会陷入断点异常int3,触发了一个trap,也就是执行 do_int3 函数:
// linux-3.10/arch/x86/include/asm/kdebug.h
/* Grossly misnamed. */
enum die_val {
DIE_OOPS = 1,
DIE_INT3,
DIE_DEBUG,
DIE_PANIC,
DIE_NMI,
DIE_DIE,
DIE_KERNELDEBUG,
DIE_TRAP,
DIE_GPF,
DIE_CALL,
DIE_PAGE_FAULT,
DIE_NMIUNKNOWN,
};
// linux-3.10/arch/x86/include/asm/traps.h
/* Interrupts/Exceptions */
enum {
X86_TRAP_DE = 0, /* 0, Divide-by-zero */
X86_TRAP_DB, /* 1, Debug */
X86_TRAP_NMI, /* 2, Non-maskable Interrupt */
X86_TRAP_BP, /* 3, Breakpoint */
X86_TRAP_OF, /* 4, Overflow */
X86_TRAP_BR, /* 5, Bound Range Exceeded */
X86_TRAP_UD, /* 6, Invalid Opcode */
X86_TRAP_NM, /* 7, Device Not Available */
X86_TRAP_DF, /* 8, Double Fault */
X86_TRAP_OLD_MF, /* 9, Coprocessor Segment Overrun */
X86_TRAP_TS, /* 10, Invalid TSS */
X86_TRAP_NP, /* 11, Segment Not Present */
X86_TRAP_SS, /* 12, Stack Segment Fault */
X86_TRAP_GP, /* 13, General Protection Fault */
X86_TRAP_PF, /* 14, Page Fault */
X86_TRAP_SPURIOUS, /* 15, Spurious Interrupt */
X86_TRAP_MF, /* 16, x87 Floating-Point Exception */
X86_TRAP_AC, /* 17, Alignment Check */
X86_TRAP_MC, /* 18, Machine Check */
X86_TRAP_XF, /* 19, SIMD Floating-Point Exception */
X86_TRAP_IRET = 32, /* 32, IRET Exception */
};
// linux-3.10/arch/x86/kernel/traps.c
/* May run on IST stack. */
dotraplinkage void __kprobes notrace do_int3(struct pt_regs *regs, long error_code)
{
......
//当 CPU 遇到断点指令时,会发生陷阱,保存 CPU 的寄存器,并通过 notifier_call_chain 机制将控制权传递给 Kprobes。
if (notify_die(DIE_INT3, "int3", regs, error_code, X86_TRAP_BP,
SIGTRAP) == NOTIFY_STOP)
goto exit;
......
}
之后会执行通知链机制上注册的回调函数:kprobe_exceptions_notify,对于int 3 指令就是kprobe_handler函数:
int3
-->do_int3
-->notify_die(DIE_INT3, "int3", regs, error_code, X86_TRAP_BP,
SIGTRAP) == NOTIFY_STOP)
-->kprobe_exceptions_notify(){
case DIE_INT3:
if (kprobe_handler(args->regs))
ret = NOTIFY_STOP;
break;
}
/*
* Interrupts are disabled on entry as trap3 is an interrupt gate and they
* remain disabled throughout this function.
*/
static int __kprobes kprobe_handler(struct pt_regs *regs)
{
kprobe_opcode_t *addr;
struct kprobe *p;
struct kprobe_ctlblk *kcb;
addr = (kprobe_opcode_t *)(regs->ip - sizeof(kprobe_opcode_t));
/*
* We don't want to be preempted for the entire
* duration of kprobe processing. We conditionally
* re-enable preemption at the end of this function,
* and also in reenter_kprobe() and setup_singlestep().
*/
preempt_disable();
kcb = get_kprobe_ctlblk();
p = get_kprobe(addr);
if (p) {
if (kprobe_running()) {
if (reenter_kprobe(p, regs, kcb))
return 1;
} else {
set_current_kprobe(p, regs, kcb);
kcb->kprobe_status = KPROBE_HIT_ACTIVE;
/*
* If we have no pre-handler or it returned 0, we
* continue with normal processing. If we have a
* pre-handler and it returned non-zero, it prepped
* for calling the break_handler below on re-entry
* for jprobe processing, so get out doing nothing
* more here.
*/
if (!p->pre_handler || !p->pre_handler(p, regs))
setup_singlestep(p, regs, kcb, 0);
return 1;
}
} else if (*addr != BREAKPOINT_INSTRUCTION) {
/*
* The breakpoint instruction was removed right
* after we hit it. Another cpu has removed
* either a probepoint or a debugger breakpoint
* at this address. In either case, no further
* handling of this interrupt is appropriate.
* Back up over the (now missing) int3 and run
* the original instruction.
*/
regs->ip = (unsigned long)addr;
preempt_enable_no_resched();
return 1;
} else if (kprobe_running()) {
p = __this_cpu_read(current_kprobe);
if (p->break_handler && p->break_handler(p, regs)) {
if (!skip_singlestep(p, regs, kcb))
setup_singlestep(p, regs, kcb, 0);
return 1;
}
} /* else: not a kprobe fault; let the kernel handle it */
preempt_enable_no_resched();
return 0;
}
对于kprobe我们主要分析这一部分:
与x86_64有关的EFLAGS 寄存器的flag位:
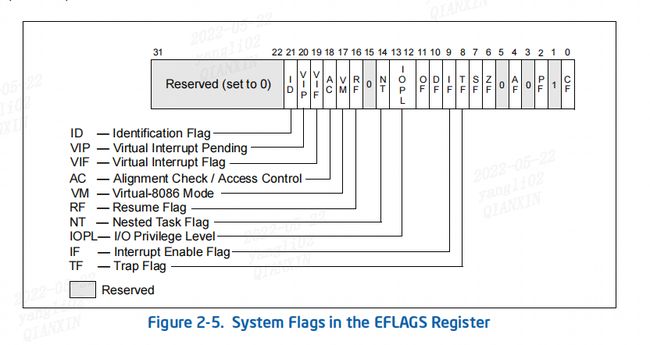
(1)TF Trap (bit 8):设置启用单步模式进行调试; 清除以禁用单步模式。 在单步模式下,处理器在每条指令后生成一个调试异常。 这允许在每条指令之后检查程序的执行状态。如果应用程序使用 POPF、POPFD 或 IRET 指令设置 TF 标志,则会在 POPF、POPFD 或 IRET 之后的指令之后生成调试异常。
(2)IF Interrupt enable (bit 9):控制处理器对可屏蔽硬件中断请求的响应,该标志设置为响应可屏蔽的硬件中断; 清除以禁止可屏蔽的硬件中断。 IF 标志不影响异常或不可屏蔽中断(NMI 中断)的生成。控制寄存器 CR4 中的 CPL、IOPL 和 VME 标志的状态决定了 IF 标志是否可以被 CLI、STI、POPF、POPFD 和 IRET 修改
set_current_kprobe设置struct kprobe *p为当前正在处理的 probe点。
// linux-3.10/arch/x86/kernel/kprobes/core.c
static void __kprobes set_current_kprobe(struct kprobe *p, struct pt_regs *regs,
struct kprobe_ctlblk *kcb)
{
__this_cpu_write(current_kprobe, p);
kcb->kprobe_saved_flags = kcb->kprobe_old_flags
= (regs->flags & (X86_EFLAGS_TF | X86_EFLAGS_IF));
if (p->ainsn.if_modifier)
kcb->kprobe_saved_flags &= ~X86_EFLAGS_IF;
}
set_current_kprobe(p, regs, kcb);
kcb->kprobe_status = KPROBE_HIT_ACTIVE;
/*
* If we have no pre-handler or it returned 0, we
* continue with normal processing. If we have a
* pre-handler and it returned non-zero, it prepped
* for calling the break_handler below on re-entry
* for jprobe processing, so get out doing nothing
* more here.
*/
if (!p->pre_handler || !p->pre_handler(p, regs))
setup_singlestep(p, regs, kcb, 0);
return 1;
这里在设置current_kprobe全局变量的同时,还会同时设置kprobe_saved_flags和kprobe_old_flags的flag值,它们用于具体的架构指令相关处理。接下来处理pre_handler回调函数,有注册的话就调用执行,然后调用setup_singlestep启动单步执行。在调试完成后直接返回1。
static void __kprobes
setup_singlestep(struct kprobe *p, struct pt_regs *regs, struct kprobe_ctlblk *kcb, int reenter)
{
if (setup_detour_execution(p, regs, reenter))
return;
#if !defined(CONFIG_PREEMPT)
if (p->ainsn.boostable == 1 && !p->post_handler) {
/* Boost up -- we can execute copied instructions directly */
if (!reenter)
reset_current_kprobe();
/*
* Reentering boosted probe doesn't reset current_kprobe,
* nor set current_kprobe, because it doesn't use single
* stepping.
*/
regs->ip = (unsigned long)p->ainsn.insn;
preempt_enable_no_resched();
return;
}
#endif
if (reenter) {
save_previous_kprobe(kcb);
set_current_kprobe(p, regs, kcb);
kcb->kprobe_status = KPROBE_REENTER;
} else
kcb->kprobe_status = KPROBE_HIT_SS;
/* Prepare real single stepping */
clear_btf();
//设置regs->flags中的TF位,开启单步调试
regs->flags |= X86_EFLAGS_TF;
//屏蔽regs->flags中的IF位,屏蔽中断
regs->flags &= ~X86_EFLAGS_IF;
/* single step inline if the instruction is an int3 */
//指令寄存器地址改为前面保存的被探测指令(备份的原始指令)
if (p->opcode == BREAKPOINT_INSTRUCTION)
regs->ip = (unsigned long)p->addr;
else
regs->ip = (unsigned long)p->ainsn.insn;
}
单步执行,首先设置EFLAGS 寄存器flags中的TF位,并屏蔽IF位,同时把int3异常返回的指令寄存器地址改为前面保存的被探测指令,当int3异常返回时这些设置就会生效,即立即执行保存的原始指令(注意这里是在触发int3之前原来的上下文中执行,因此直接执行原始指令即可,无需特别的模拟操作)。该函数返回后do_int3函数立即返回,由于EFLAGS 寄存器TF位被设置,在单步执行完被探测指令后立即触发debug异常,进入debug异常处理函数do_debug,执行post_kprobe_handler函数,即post_handler()。
3.3 do_bug
dotraplinkage void __kprobes do_debug(struct pt_regs *regs, long error_code)
{
......
if (notify_die(DIE_DEBUG, "debug", regs, PTR_ERR(&dr6), error_code,
SIGTRAP) == NOTIFY_STOP)
......
}
由于初始化时注册了内核通知链:kprobe_exceptions_nb,执行被探测指令期间若发生了内存异常,比如执行了debug指令, 将最优先调用kprobe_exceptions_notify函数。
/*
* Wrapper routine for handling exceptions.
*/
int __kprobes
kprobe_exceptions_notify(struct notifier_block *self, unsigned long val, void *data)
{
......
case DIE_DEBUG:
if (post_kprobe_handler(args->regs)) {
/*
* Reset the BS bit in dr6 (pointed by args->err) to
* denote completion of processing
*/
(*(unsigned long *)ERR_PTR(args->err)) &= ~DR_STEP;
ret = NOTIFY_STOP;
}
break;
......
}
/*
* Interrupts are disabled on entry as trap1 is an interrupt gate and they
* remain disabled throughout this function.
*/
static int __kprobes post_kprobe_handler(struct pt_regs *regs)
{
struct kprobe *cur = kprobe_running();
struct kprobe_ctlblk *kcb = get_kprobe_ctlblk();
if (!cur)
return 0;
resume_execution(cur, regs, kcb);
regs->flags |= kcb->kprobe_saved_flags;
if ((kcb->kprobe_status != KPROBE_REENTER) && cur->post_handler) {
kcb->kprobe_status = KPROBE_HIT_SSDONE;
cur->post_handler(cur, regs, 0);
}
/* Restore back the original saved kprobes variables and continue. */
if (kcb->kprobe_status == KPROBE_REENTER) {
restore_previous_kprobe(kcb);
goto out;
}
reset_current_kprobe();
out:
preempt_enable_no_resched();
/*
* if somebody else is singlestepping across a probe point, flags
* will have TF set, in which case, continue the remaining processing
* of do_debug, as if this is not a probe hit.
*/
if (regs->flags & X86_EFLAGS_TF)
return 0;
return 1;
}
首先调用resume_execution函数将debug异常返回的下一条指令设置为被探测之后的指令,这样异常返回后程序的流程就会按正常的流程继续执行;然后恢复kprobe执行前保存的flags标识;接下来如果kprobe不是重入的并且设置了post_handler回调函数,就设置kprobe_status状态为KPROBE_HIT_SSDONE并调用post_handler函数,即调用用户态设置的post_handler回调函数。
四、Changing Execution Path
由于 kprobes 可以探测正在运行的内核代码,它可以更改寄存器集,包括指令指针。 此操作需要非常小心,例如保留堆栈帧,恢复执行路径等。因为它在运行的内核上运行并且需要深入了解计算机体系结构。
如果您更改 pre_handler 中的指令指针(并设置其他相关寄存器),则必须返回 !0 以便 kprobes 停止单步执行并返回到给定地址。 这也意味着不应再调用 post_handler。
请注意,在某些使用 TOC(Table of Contents)进行函数调用的架构上,此操作可能会更难,因为您必须在模块中为您的函数设置一个新的 TOC,并在从它返回后恢复旧的 TOC。
五、Return Probes
5.1 How Does a Return Probe Work
当您调用 register_kretprobe() 时,Kprobes 在函数的入口处建立一个 kprobe。 当被探测的函数被调用并且这个探测被命中时,Kprobes 会保存一份返回地址的副本,并将返回地址替换为“trampoline”的地址。trampoline是一段任意代码——通常只是一条 nop 指令。 在启动时,Kprobes 在 trampoline 上注册一个 kprobe。
当被探测的函数执行它的 return instruction时,控制权传递给trampoline并且该探测被命中。 Kprobes 的 trampoline 处理程序调用与 kretprobe 关联的用户指定的返回处理程序,然后将保存的指令指针设置为保存的返回地址,这就是从陷阱返回后恢复执行的地方。
当被探测函数正在执行时,它的返回地址存储在一个 kretprobe_instance 类型的对象中。 在调用 register_kretprobe() 之前,用户设置 kretprobe 结构的 maxactive 字段来指定可以同时探测多少个指定函数的实例。 register_kretprobe() 预分配指定数量的 kretprobe_instance 对象。
例如,如果函数是非递归的并且在调用时持有自旋锁,那么 maxactive = 1 就足够了。 如果函数是非递归的并且永远不会放弃 CPU(例如,通过信号量或抢占),则 NR_CPUS 应该足够了。 如果 maxactive <= 0,则设置为默认值。 如果启用了 CONFIG_PREEMPT,则默认值为 max(10, 2*NR_CPUS)。 否则,默认值为 NR_CPUS。
如果你将 maxactive 设置得太低,这不是一场灾难; 你只会错过一些探测。 在 kretprobe 结构中,nmissed 字段在注册返回探针时设置为零,并且每次进入被探测函数但没有可用于建立返回探针的 kretprobe_instance 对象时递增。
5.2 Kretprobe entry-handler
Kretprobes 还提供了一个可选的用户指定的处理程序,它在函数入口上运行。 该处理程序是通过设置 kretprobe 结构的 entry_handler 字段来指定的。 每当 kretprobe 放置在函数入口处的 kprobe 被命中时,都会调用用户定义的 entry_handler,如果有的话。 如果 entry_handler 返回 0(成功),则保证在函数返回时调用相应的返回处理程序。 如果 entry_handler 返回非零错误,则 Kprobes 将返回地址保持原样,并且 kretprobe 对该特定函数实例没有进一步的影响。
使用与它们关联的唯一 kretprobe_instance 对象来匹配多个入口和返回处理程序调用。 此外,用户还可以将每个返回实例的私有数据指定为每个 kretprobe_instance 对象的一部分。 这在相应的用户条目和返回处理程序之间共享私有数据时特别有用。 每个私有数据对象的大小可以在 kretprobe 注册时通过设置 kretprobe 结构的 data_size 字段来指定。 可以通过每个 kretprobe_instance 对象的数据字段访问此数据。
如果输入了探测函数但没有可用的 kretprobe_instance 对象,则除了增加 nmissed 计数外,还会跳过用户 entry_handler 调用。
六、How Does Jump Optimization Work
关于kprobe的优化可以参考这篇文章:linux kprobe实现原理
如果Linux 内核是使用 CONFIG_OPTPROBES=y 构建的(目前此标志在 x86/x86-64 非抢占式内核上自动设置为 ‘y’)并且“debug.kprobes_optimization”内核参数设置为 1 ,Kprobes 会尝试减少探测 - 通过在每个探测点使用跳转指令而不是断点指令来降低开销。
int 3 指令会产生一个 a trap ,比较耗时,可以用跳转指令替换断点指令,优化成jmp指令跳转到kprobe探测点。
当前的机器默认配置了 CONFIG_OPTPROBES 选项:
[root@localhost ~]# cat /etc/centos-release
CentOS Linux release 7.6.1810 (Core)
[root@localhost ~]# uname -r
3.10.0-957.el7.x86_64
# Kernel Performance Events And Counters
#
CONFIG_SLUB=y
CONFIG_PROFILING=y
CONFIG_TRACEPOINTS=y
CONFIG_CRASH_CORE=y
CONFIG_KEXEC_CORE=y
CONFIG_HOTPLUG_SMT=y
CONFIG_OPROFILE=m
CONFIG_OPROFILE_EVENT_MULTIPLEX=y
CONFIG_HAVE_OPROFILE=y
CONFIG_OPROFILE_NMI_TIMER=y
CONFIG_KPROBES=y
CONFIG_JUMP_LABEL=y
CONFIG_OPTPROBES=y //当前的机器配置了 CONFIG_OPTPROBES 选项
debug.kprobes_optimization内核参数同样也设置为 1:
[root@localhost ~]# cat /proc/sys/debug/kprobes-optimization
1
[root@localhost ~]#
6.1 Init a Kprobe
注册一个 probe 后,在尝试此优化之前,Kprobes会在指定地址插入一个基于断点的普通kprobe。因此,即使无法优化这个特定的probepoint,也会有一个探针。
6.2 Safety Check
在优化探针之前,Kprobes会执行以下安全检查,不符合条件不可以进行优化:
(1)Kprobes 验证将被跳转指令替换的区域(“优化区域”)是否完全位于一个函数中。 (跳转指令是5个字节:near relative jump,因此可能会覆盖多个指令。)
(2)Kprobes 分析整个函数并验证没有跳转到优化区域,不能有跳转到这块要被优化区域的指令,这块区域将会被jmp覆盖,具体如下:
a:函数中不包含间接跳转(indirect jump);
b:该函数不包含导致异常的指令(因为由异常触发的修复代码可以跳回优化区域 - Kprobes 检查异常表以验证这一点);
c:没有到优化区域的近跳转(near jump)(除了第一个字节)。
(3)对于优化区域中的每条指令,Kprobes将验证该指令是否可以单独执行。
使用如下跳转指令(near jump)形式:
JMP 跳转指令:
0xE9(E9 cd) :Jump near 后面的4个字节是偏移:一个保存jmp本身的机器码,另4个保存偏移 -->总共5个字节
6.3 Preparing Detour Buffer
接下来,Kprobes准备了一个 Detour 缓冲区,其中包含以下指令序列:
(1)能够将cpu寄存器压栈(模拟int3的trap过程)。
(2)调用用户的探测处理程序的蹦床代码(trampoline code)。
(3)恢复寄存器的代码。
(4)来自优化区域的指令。
(5)跳转回原来的执行路径。
6.4 Pre-optimization
准备 Detour 缓冲区后,Kprobes验证以下情况是否存在:
(1)探针有一个 post_handler。
(2)探测优化区域中的其他指令。
(3)探针被禁用。
在上述任何一种情况下,Kprobes 都不会开始优化探针。 由于这些是临时情况,如果情况发生变化,Kprobes 会尝试再次开始优化。
如果可以优化 kprobe,则 Kprobes 将 kprobe 排入优化列表,并启动 kprobe-optimizer 工作队列以对其进行优化。如果要优化的probepoint在优化之前被命中,则Kprobes通过将CPU的指令指针设置为 the detour buffer 中复制的代码,将控制权返回到原始指令路径,从而至少避免了单步执行。
6.5 Optimization
Kprobe-optimizer 不会立即插入跳转指令; 相反,它首先出于安全考虑调用 synchronize_rcu(),因为 CPU 在执行优化区域的过程中可能会被中断。 synchronize_rcu() 可以确保在调用 synchronize_rcu() 时处于活动状态的所有中断都已完成,但前提是 CONFIG_PREEMPT=n。 因此,此版本的 kprobe 优化仅支持具有 CONFIG_PREEMPT=n 的内核。
centos 7.6 :3.10.0默认没有开启 CONFIG_PREEMPT选项:
# CONFIG_PREEMPT is not set
之后,Kprobe优化器调用stop_machine(),使用text_poke_smp()将优化区域替换为 Detour 缓冲区的跳转指令。
6.6 Unoptimization
当一个优化了的kprobe未注册、禁用或被另一个kprobe阻止时,它将被取消优化。如果在优化完成之前发生这种情况,则kprobe将从优化列表中退出队列。如果优化已经完成,则使用text_poke_smp()将跳转替换为原始代码(第一个字节如果是int3断点除外)。假设第二条指令被中断,然后优化器在中断处理程序运行时用跳转地址替换第二条命令。当中断返回到原始地址时,如果没有有效的指令,这将会导致意外的结果。
注意:跳转优化会更改kprobe的pre_handler行为。如果不进行优化,pre_handler可以通过更改regs->ip并返回1来更改内核的执行路径,完成内核函数的hook。但是,当优化探针时,该更改将会被忽略,不能内核函数的hook了。
因此,如果要调整内核的执行路径,即hook,需要使用以下技术之一禁止优化:
(1)为kprobe的post_handler指定一个空函数。
(2)执行“sysctl-w debug.krobes_optimization=n”
6.7 Blacklist
Kprobes可以探测除Kprobes本身之外的大部分内核函数。这意味着有些函数kprobes无法探测。探测(捕获)此类函数可能会导致递归陷阱(例如 double fault),或者嵌套的探测处理程序可能永远不会被调用。Kprobes使用 a blacklist 来管理该功能,如果要将函数添加到 blacklist中,只需包含linux/kprobes.h并使用NOKPROBE_SYMBOL()宏指定一个 blacklisted 函数即可。Kprobes根据 blacklist 检查给定的探测地址,如果给定地址在 blacklist 中,则拒绝注册。
// linux-4.10.1/include/linux/kprobes.h
#ifdef CONFIG_KPROBES
/*
* Blacklist ganerating macro. Specify functions which is not probed
* by using this macro.
*/
#define __NOKPROBE_SYMBOL(fname) \
static unsigned long __used \
__attribute__((section("_kprobe_blacklist"))) \
_kbl_addr_##fname = (unsigned long)fname;
#define NOKPROBE_SYMBOL(fname) __NOKPROBE_SYMBOL(fname)
可以通过 NOKPROBE_SYMBOL 宏在内核源码中查询内核哪些函数不能被探测:
......
NOKPROBE_SYMBOL(__context_tracking_enter);
NOKPROBE_SYMBOL(get_kprobe);
NOKPROBE_SYMBOL(notifier_call_chain);
NOKPROBE_SYMBOL(preempt_count_add);
NOKPROBE_SYMBOL(perf_trace_buf_alloc);
NOKPROBE_SYMBOL(FETCH_FUNC_NAME(stack, type));
NOKPROBE_SYMBOL(PRINT_TYPE_FUNC_NAME(tname));
......
6.8 try_to_optimize_kprobe
int register_kprobe(struct kprobe *p)
{
......
/* Try to optimize kprobe */
try_to_optimize_kprobe(p);
......
}
EXPORT_SYMBOL_GPL(register_kprobe);
/*
* Prepare an optimized_kprobe and optimize it
* NOTE: p must be a normal registered kprobe
*/
static void try_to_optimize_kprobe(struct kprobe *p)
{
struct kprobe *ap;
struct optimized_kprobe *op;
/* Impossible to optimize ftrace-based kprobe */
if (kprobe_ftrace(p))
return;
/* For preparing optimization, jump_label_text_reserved() is called */
jump_label_lock();
mutex_lock(&text_mutex);
(1)分配新的 optimized_kprobe 并尝试准备优化的指令
ap = alloc_aggr_kprobe(p);
if (!ap)
goto out;
op = container_of(ap, struct optimized_kprobe, kp);
if (!arch_prepared_optinsn(&op->optinsn)) {
/* If failed to setup optimizing, fallback to kprobe */
arch_remove_optimized_kprobe(op);
kfree(op);
goto out;
}
(2)将hlist中较早的kprobe替换为manager kprobe
init_aggr_kprobe(ap, p);
(3)开始优化 kprobe 点
optimize_kprobe(ap); /* This just kicks optimizer thread */
out:
mutex_unlock(&text_mutex);
jump_label_unlock();
}
CONFIG_OPTPROBES=y
// linux-4.10.1/arch/x86/include/asm/kprobes.h
struct arch_optimized_insn {
/* copy of the original instructions */
kprobe_opcode_t copied_insn[RELATIVE_ADDR_SIZE];
/* detour code buffer */
kprobe_opcode_t *insn;
/* the size of instructions copied to detour code buffer */
size_t size;
};
为kprobe关联一个optimized_kprobe对象,它有一个detour buffer,保存有一段指令,之后是通过jmp跳转回原始函数。
#ifdef CONFIG_OPTPROBES
/*
* Internal structure for direct jump optimized probe
*/
struct optimized_kprobe {
struct kprobe kp;
struct list_head list; /* list for optimizing queue */
struct arch_optimized_insn optinsn;
};
(1) alloc_aggr_kprobe:分配新的 optimized_kprobe 并尝试准备优化的指令
/* Allocate new optimized_kprobe and try to prepare optimized instructions */
static struct kprobe *alloc_aggr_kprobe(struct kprobe *p)
{
struct optimized_kprobe *op;
op = kzalloc(sizeof(struct optimized_kprobe), GFP_KERNEL);
if (!op)
return NULL;
INIT_LIST_HEAD(&op->list);
op->kp.addr = p->addr;
arch_prepare_optimized_kprobe(op, p);
return &op->kp;
}
x86_64 相关优化kprobe的函数都在 /arch/x86/kernel/kprobes/opt.c 文件中
// linux-4.10.1/arch/x86/kernel/kprobes/opt.c
/*
* Copy replacing target instructions
* Target instructions MUST be relocatable (checked inside)
* This is called when new aggr(opt)probe is allocated or reused.
*/
int arch_prepare_optimized_kprobe(struct optimized_kprobe *op,
struct kprobe *__unused)
{
u8 *buf;
int ret;
long rel;
if (!can_optimize((unsigned long)op->kp.addr))
return -EILSEQ;
op->optinsn.insn = get_optinsn_slot();
if (!op->optinsn.insn)
return -ENOMEM;
/*
* Verify if the address gap is in 2GB range, because this uses
* a relative jump.
*/
rel = (long)op->optinsn.insn - (long)op->kp.addr + RELATIVEJUMP_SIZE;
if (abs(rel) > 0x7fffffff) {
__arch_remove_optimized_kprobe(op, 0);
return -ERANGE;
}
buf = (u8 *)op->optinsn.insn;
/* Copy instructions into the out-of-line buffer */
ret = copy_optimized_instructions(buf + TMPL_END_IDX, op->kp.addr);
if (ret < 0) {
__arch_remove_optimized_kprobe(op, 0);
return ret;
}
op->optinsn.size = ret;
/* Copy arch-dep-instance from template */
memcpy(buf, &optprobe_template_entry, TMPL_END_IDX);
/* Set probe information */
synthesize_set_arg1(buf + TMPL_MOVE_IDX, (unsigned long)op);
/* Set probe function call */
synthesize_relcall(buf + TMPL_CALL_IDX, optimized_callback);
/* Set returning jmp instruction at the tail of out-of-line buffer */
synthesize_reljump(buf + TMPL_END_IDX + op->optinsn.size,
(u8 *)op->kp.addr + op->optinsn.size);
flush_icache_range((unsigned long) buf,
(unsigned long) buf + TMPL_END_IDX +
op->optinsn.size + RELATIVEJUMP_SIZE);
return 0;
}
arch_optimize_kprobes :用 relative jumps 替换 breakpoints (int3)。
jmp + 偏移的方式,偏移为32bit,所以共占据5个字节:
```c
JMP 跳转指令:
0xE9(E9 cd) :Jump near 后面的4个字节是偏移:一个保存jmp本身的机器码,另4个保存偏移 -->总共5个字节
// linux-4.10.1/arch/x86/include/asm/kprobes.h
#define BREAKPOINT_INSTRUCTION 0xcc
#define RELATIVEJUMP_OPCODE 0xe9
#define RELATIVEJUMP_SIZE 5
// linux-4.10.1/arch/x86/kernel/kprobes/opt.c
/*
* Replace breakpoints (int3) with relative jumps.
* Caller must call with locking kprobe_mutex and text_mutex.
*/
void arch_optimize_kprobes(struct list_head *oplist)
{
struct optimized_kprobe *op, *tmp;
u8 insn_buf[RELATIVEJUMP_SIZE];
list_for_each_entry_safe(op, tmp, oplist, list) {
s32 rel = (s32)((long)op->optinsn.insn -
((long)op->kp.addr + RELATIVEJUMP_SIZE));
WARN_ON(kprobe_disabled(&op->kp));
/* Backup instructions which will be replaced by jump address */
memcpy(op->optinsn.copied_insn, op->kp.addr + INT3_SIZE,
RELATIVE_ADDR_SIZE);
insn_buf[0] = RELATIVEJUMP_OPCODE;
*(s32 *)(&insn_buf[1]) = rel;
text_poke_bp(op->kp.addr, insn_buf, RELATIVEJUMP_SIZE,
op->optinsn.insn);
list_del_init(&op->list);
}
}
/* Replace a relative jump with a breakpoint (int3). */
void arch_unoptimize_kprobe(struct optimized_kprobe *op)
{
u8 insn_buf[RELATIVEJUMP_SIZE];
/* Set int3 to first byte for kprobes */
insn_buf[0] = BREAKPOINT_INSTRUCTION;
memcpy(insn_buf + 1, op->optinsn.copied_insn, RELATIVE_ADDR_SIZE);
text_poke_bp(op->kp.addr, insn_buf, RELATIVEJUMP_SIZE,
op->optinsn.insn);
}
(2) init_aggr_kprobe:“manager kprobe”是必填字段,将hlist中较早的kprobe替换为manager kprobe。
/*
* Fill in the required fields of the "manager kprobe". Replace the
* earlier kprobe in the hlist with the manager kprobe
*/
static void init_aggr_kprobe(struct kprobe *ap, struct kprobe *p)
{
/* Copy p's insn slot to ap */
copy_kprobe(p, ap);
flush_insn_slot(ap);
ap->addr = p->addr;
ap->flags = p->flags & ~KPROBE_FLAG_OPTIMIZED;
ap->pre_handler = aggr_pre_handler;
ap->fault_handler = aggr_fault_handler;
/* We don't care the kprobe which has gone. */
if (p->post_handler && !kprobe_gone(p))
ap->post_handler = aggr_post_handler;
if (p->break_handler && !kprobe_gone(p))
ap->break_handler = aggr_break_handler;
INIT_LIST_HEAD(&ap->list);
INIT_HLIST_NODE(&ap->hlist);
list_add_rcu(&p->list, &ap->list);
hlist_replace_rcu(&p->hlist, &ap->hlist);
}
(3) optimize_kprobe:开始优化 kprobe 点。
/* Optimize kprobe if p is ready to be optimized */
static void optimize_kprobe(struct kprobe *p)
{
struct optimized_kprobe *op;
/* Check if the kprobe is disabled or not ready for optimization. */
if (!kprobe_optready(p) || !kprobes_allow_optimization ||
(kprobe_disabled(p) || kprobes_all_disarmed))
return;
/* Both of break_handler and post_handler are not supported. */
if (p->break_handler || p->post_handler)
return;
op = container_of(p, struct optimized_kprobe, kp);
/* Check there is no other kprobes at the optimized instructions */
if (arch_check_optimized_kprobe(op) < 0)
return;
/* Check if it is already optimized. */
if (op->kp.flags & KPROBE_FLAG_OPTIMIZED)
return;
op->kp.flags |= KPROBE_FLAG_OPTIMIZED;
if (!list_empty(&op->list))
/* This is under unoptimizing. Just dequeue the probe */
list_del_init(&op->list);
else {
list_add(&op->list, &optimizing_list);
kick_kprobe_optimizer();
}
}
参考资料
https://static.lwn.net/kerneldoc/trace/kprobes.html
https://blog.csdn.net/luckyapple1028/article/details/52972315
https://blog.csdn.net/pwl999/article/details/78225858
https://blog.csdn.net/u012489236/article/details/127942216
https://blog.csdn.net/melody157398/article/details/113903828
https://mp.weixin.qq.com/s/X1v1W9azyTTof0myBKFdqw