基于BERT的情感分类模型建立
随着大数据时代的到来,如何筛选以及获取有效信息成为了一项重要的技能,通过使用爬虫按照一种规则自动从万维网筛选信息已经成为一种重要的能力,本次实验的目的就是通过工程实践加深对理论知识的深入理解和综合应用,进一步提高实践动手能力。
(1)首先对python环境的安装以及商家信息的爬取,所爬取的商家信息为商家的id、商家名、平均得分、地址、平均价格、获得评论总数,得到的结果保存在csv文件之中,然后通过得到的商家的id构造出可以获取用户评论的url,通过访问这个url,获取这个商家的评论以及打分,存入到csv文件之中。
(2)其次对第一个实验爬取到的评论数据按照评分进行评论分类,得分大于30的为好评类,小于30的为差评类,我们在商家上面爬取得到的评论和打分,最高为50分,将所有数据划分为训练集和测试集,使用多种模型来进行一个简单的中文情感分类,最后用测试集来检测我们模型的泛化能力。
(3)最后对每个商家的评论建立词云,将多的词展示出来。
对所需要操作进行分析主要步骤可以分成两个阶段:
- 评论数据的爬取
- 建立模型进行分析
主要实验环境、配置、需要学习到的知识:
(1)python2.7
(2)Bert中文预向量处理支持、Jupyter
(3)php、json相关知识,所运用到的一些包:requests、numpy、re、csv、pandas、keras、json、urllib、os、wordSegment、word_cloud、PIL、matplotlib
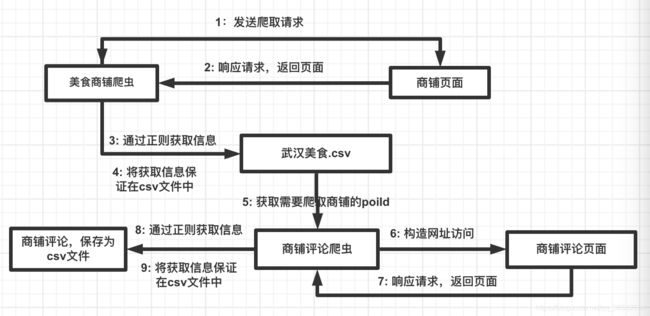
一、爬取商家信息和评论数据
1.具体思路:
首先,确定爬取美食的网站地址;
然后通过json得到请求的页面信息,期间设置headers来进行伪造请求,避免被网站页面拦截验证;
再者,就是通过正则匹配找到要求我们在页面中爬取的内容;
最后,遍历各个页面将需要信息爬取下来输出保存在csv文档之中。
在爬取评论内容,得到每个商家评论和评分所在的json,我们通过正则表达式爬取需要的内容然后存入csv文件中,每个商家的评论和评分存在一个csv文件中,以该商家的poiId作为文件的名字。
上述思路流程图:
2.商铺信息爬取
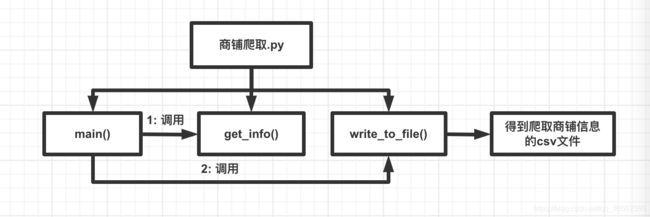
在商铺爬取中,首先构造商铺的网站,通过设置循环访问的页数使用python进行访问:
for i in range(1,8):
url = 'https://wh.网站.com/meishi/pn' + str(i) + '/'
headers = {
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11' }
在上述构造访问网站的url过程中,我们需要设置header才能避免访问失败,通过一个循环来对网站页面进行访问,我们也可以设置多个页数,这里对商铺的设置是爬取8页信息,我当时爬取的时候每页有15家商铺的信息,8*15 = 120 家商铺信息。
当get_info函数得到main函数传给的wurl和headers的信息之后,通过python的requests.get得到url的信息然后存到一个response里面,通过python的正则来获取response.text里面我们需要的关键点。
response = requests.get(url,headers = headers) # 获取信息
poiId = re.findall(r'"poiId":(\d+),',response.text # 商家id
shopname = re.findall(r'"frontImg".*?title":(.*?)',response.text) # 商家名字
avgScore = re.findall(r'"avgScore":(.*?),'response.text) # 平均分
allCommentNum = re.findall(r'"allCommentNum":(\d+)',response.text) # 评论总数
address = re.findall(r'"address":(.*?),'response.text) # 商家地址
avgPrice = re.findall(r'"avgPrice":(\d+),'response.text) # 平均价格
这里第一行代码的目的是通过url、headers对目标构造访问请求,接下来的代码为通过正则表达式—findall对特征的内容进行爬取,从而得到需要的相应信息,存到对应的变量之中,这里的poiId、shopname、avgScore、allCommentNum、address、avgPrice都是list格式,里面有15个数据内容,因为爬取一页商家的页面有15家商家,这在上面已经提及,然后通过append函数添加到一个总的list之中,构成一行数据,然后返回包含15个商家信息数据的list。
最后调用write_to_file函数将商家信息存到csv文件之中,循环进行8次,以此爬取8个美食的商家页面,总共105家商家信息。
3.商铺评论爬取
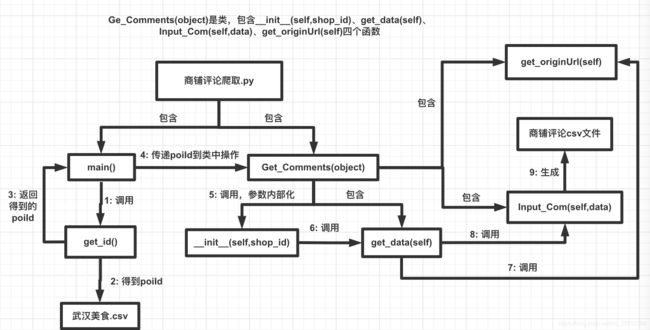
基于我们对商铺的爬取获得的poiId,从第一个得到的csv文件之中获取,这里通过使用python对于csv的操作函数就能够实现,简单的操作直接略过,得到poiId用来构造访问评论信息所在的url。
def get_originUrl(self):
"""
构造访问店铺的url拼接,这里返回的每个特定商家的网页的开头部分,返回到调用该函数的地方,便于得到需要爬取该商家的url
"""
return parse.quote_plus('http://www.网站.com/meishi/' + self.shop_id + '/')
然后通过对以下参数来确定得到评论和评分数据所在的url地方
params = {
'platform': '1',
'partner': '126',
'originUrl': url_code,
'riskLevel': '1',
'optimusCode': '1',
'id': self.shop_id, # 我们设置的内部poiId
'offset': '0',
'pageSize': '200', # 根据捕获异常获得评论数较多的量,评论少就不要了
'sortType': '1',
}
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11' }
response = requests.get(url=url, params=params, headers=headers)
data = response.text
同样是构造一个header,通过requests.get带有特定的参数访问url得到信息存入到data之中,data是一个str类型的数据。
data_dict = json.loads(data)
for item in data_dict.get('data').get('comments'):
with open(r'CommentData/{}.csv'.format(str(self.shop_id)), 'a', encoding='utf-8') as csvfile:
job_list = [item.get('comment'),item.get('star')]
write = csv.writer(csvfile)
write.writerow(job_list)
except TypeError:
pass
上面设置了一个捕获异常的处理,主要是因为在爬取评论的时候,一些评论为空或者其他类型的错误导的出错,这里我们就pass掉,直接进行下一条的爬取。
二、建立模型对评论数据进行分析
一般思路是运用朴素贝叶斯算法进行文本分类,分析实验说明书提供给我网页,成功实现使用朴素贝叶斯算法的文本分类,主要思路为对数据进行处理,然后读取,处理缺失的评论,然后重置索引,对评论的特征进行处理,根据评分进行分类,设置特征标签数组,分别为好的为1,坏的为0,然后引入朴素贝叶斯算法训练,通过jieba分词将评论变为多词组并进行向量化,然后加入一些停用词处理,剔除一些分析之中的干扰词,然后实例化一个模型,通过管道把特征词放进行训练,通过交叉验证以及对测试集进行测试,当然,训练集和测试集都打乱,最后得到精确度为0.84002000000000006,也就是84%左右,我当然不满意这个实验结果。
然后通过查询资料,了解到Bert,决定想用Bert进行实验,查阅到的资料显示Bert来做各种实验都是结果挺高的,于是打算使用bert来进行,下面的思路主要就是面对Bert来写的,因为朴素贝叶斯方法我在上面也进行了大致的描述,也得到了结果。

Bert中文向量分析思路描述:
其实,不管你用什么模型或者方法去进行简单情感分类的训练,他的大致流程其实和我在上面进行的朴素贝叶斯方法差不多,大致内容都是数据预处理、标识组设置—>评论数据打乱—>评论数据向量化—>输入到模型之中—>训练—>验证—>得到结果这一个流程展开的,使用Bert进行分析也是这个流程,只是很多细节不一样罢了。
在这里能够使用Bert主要是感谢腾讯AI实验室所发布的bert-as-service接口,通过这个接口,得到预训练好的bert模型生成的句向量和词向量,不需要引入一些特征词,而是通过评论数据转换得到的句向量经过训练得到两个好、坏模型然后进行验证。但是主要的缺点就是跑得挺慢的,我这里10000多条训练数据和1000多条验证数据在电脑上跑了大概20多分钟,还是功率全开的那种,声音特别响、散热一直在运作,所以基本上我总共跑了2个朴素贝叶斯的模型,还有3个Bert的模型。
主要实现操作:
- 导入数据
- 对评论进行过滤,只保留中文
- 构建评论数据集合——训练数据和测试数据
- 创建评论数据好坏匹配标签组
- 随机打乱评论
- 通过Bert-as-service得到数据中文词向量
- 建立评论情感分析模型
- 开始训练
- 查看训练情况并将其可视化显示
- 测试集进行测试并得到模型验证结果
1.导入数据
good = pd.read_csv('N_good.csv') # 导入不同评论信息
bad = pd.read_csv('N_bad.csv')
comments_10 = good.comment
comments_20 = bad.comment
这里我就不赘述关于使用python对csv文件进行数据处理的过程了,只需要知道使用python将爬取到的商家评论全都整合到一个csv文件之中,根据实验说明书中,将评论评分大于30的视之为好评整合在N_good.csv文件之中,小于30的评论评分整合到N_bad.csv之中,然后通过pandas库导入。
2.对评论进行过滤,只保留中文
for i in range(len(comments_10)): # 对好的评论进行过滤
goodcom = comments_10.iloc[i]
try:
goodcom = re.sub("[^\u4E00-\u9FA5]","",goodcom)
if len(goodcom) > 2 and len(goodcom) < 100:
X_data1.append(goodcom)
except:
pass
for j in range(len(comments_20)): # 对坏的评论进行过滤
badcom = comments_20.iloc[j]
try:
badcom = re.sub("[^\u4E00-\u9FA5]","",badcom)
if len(badcom) > 2 and len(badcom) < 100:
X_data2.append(badcom)
except:
pass
在这个阶段,我们通过for循环,把每一行中的评论导入,使用正则表达式来过滤评论中的非中文字符,s"[^\u4E00-\u9FA5]"这里表示的是匹配中文字符的正则表达式,然后放入到goodcom之中,最后我们筛选出字符长度大于2且小于100的评论加入到好评集合之中,坏评集过程和好评一样。
3.构建评论数据集合——训练数据和测试数据
X_data = X_data1[:7000] + X_data2[:7000]
X_test_data = X_data1[7000:7900] + X_data2[7000:7900]
下面X_data是选出X_data1之后好的评论的前6000条和X_data2之后的坏的评论的7000条来组成训练,X_test_data为测试集,选出X_data1和X_data2之中的各900条。
4.创建评论数据好坏匹配标签组
y_data = [1 for i in range(7000)] + [0 for i in range(7000)]
y_data = np.asarray(y_data, dtype=np.float32)
y_test_data = [1 for i in range(900)] + [0 for i in range(900)]
y_test_data = np.asarray(y_test_data, dtype=np.float32)
这里主要就是在得到训练数据之后,我们手工创建一个labels数组来作为训练标签,前7000个是好的评论我们设置为1,后7000个为坏的评论我们设置为0,测试集同样如此。
5.随机打乱评论
nums = []
nums_ = []
X_train = []
Y_train = []
X_test = []
Y_test = []
nums = np.arange(14000)
np.random.shuffle(nums)
for i in nums:
X_train.append(X_data[i])
Y_train.append(y_data[i])
nums_ = np.arange(1800)
np.random.shuffle(nums_)
for i in nums_:
X_test.append(X_test_data[i])
Y_test.append(y_test_data[i])
借助numpy来对数据进行随机打乱,标签数组同样与训练集、测试集应着,用shuffle来随机打乱训练集和测试集,标签数组对应,然后list转换为numpy数组,后面模型输入的需要是numpy的数据类型。
6.通过Bert-as-service得到数据中文词向量
bc = BertClient(ip = 'localhost')
input_train = bc.encode(X_train)
input_test = bc.encode(X_test)
这里是重点,这行代码将训练集和测试集进行向量化,每一行评论数据转换为1*768维的句向量,通过在终端开启一个端口,并设置相应线程来对输入的评论数据进行向量化转换,具体操作过程如下所示:
这里通过导入bert的中文预向量转换模型的地址,然后设置工作的可以说是线程数,我这里设置的是4个线程。
中文预向量转换模型在这里下载。
具体说明如下所示:

这里,箭头指的是下载的中文的Bert训练文件的位置、进行评论转换的工作的线程数量,开放的转换的本地端口号。下面为进行训练的过程:
7.建立评论情感分析模型
model = Sequential()
model.add(Dense(32, activation = 'relu', input_shape=(768,)))
model.add(Dropout(0.5))
model.add(Dense(32, activation = 'relu'))
model.add(Dense(1, activation = 'sigmoid'))
model.compile(
loss = 'binary_crossentropy',
optimizer = tf.train.AdamOptimizer(),
metrics = ['accuracy']
)
这里运用了Keras来进行建模,用的是Sequential类来定义这个模型,然后模型使用Dense来进行全连接层拼接,引入Dropout层来进行部分数据丢弃防止过拟合,然后指定这个模型的优化器和损失函数,以及监控的数据。
8.开始训练
start = model.fit(
input_train, Y_train,
epochs = 30,
batch_size = 256,
validation_split = 0.2,
verbose = 1
)
这里迭代训练30个,使用训练集的20%来作为验证集,通过fit的方式将这些numpy形式的数组传入到模型之中,开始训练:

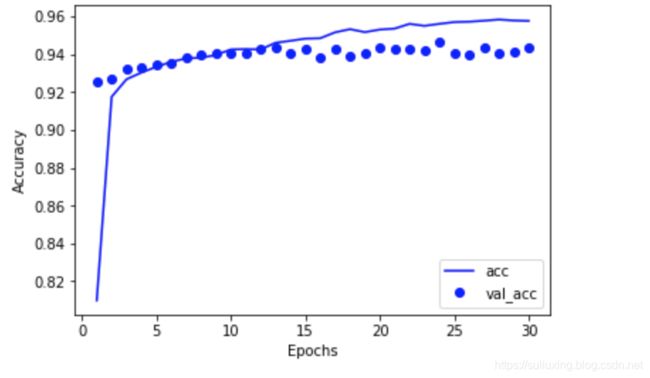
9.查看训练情况并将其可视化显示
# 将数据拟合和准确率打印出来
import matplotlib.pyplot as plt
history_dict = history.history
epochs = range(1, len(history_dict['acc']) + 1)
plt.figure()
plt.plot(epochs, history_dict['acc'], 'b',label='acc')
plt.plot(epochs, history_dict['val_acc'], 'bo',label='val_acc')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
plt.clf()
plt.figure()
plt.plot(epochs, history_dict['loss'], 'b', label='acc')
plt.plot(epochs, history_dict['val_loss'],'bo',label='val_acc')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
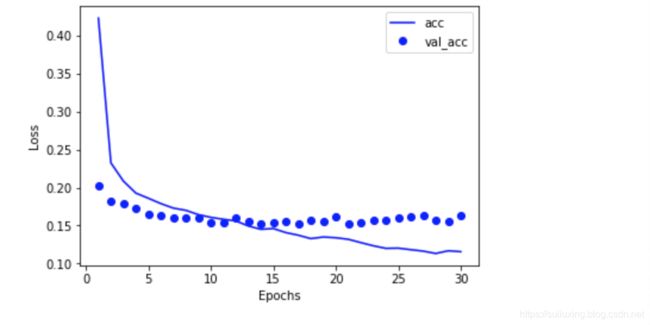
上面两个图都在一定程度上显示了我的训练数据与测试数据拟合度是很高的,训练集是有效的。
回忆了一下,我这里在jupyter能够顺利运行,在vscode搭建的操作平台下却是显示失败的,主要是python里面的绘图函数库有问题,我的解决方案是去使用Qt来进行绘制,mac下对于python绘图主要为tk。
10.测试集进行测试并得到模型验证结果
test_loss = model.evaluate(
input_test,Y_test,
batch_size = 64,
verbose = 1
)
print(test_loss) # 输出测试信息
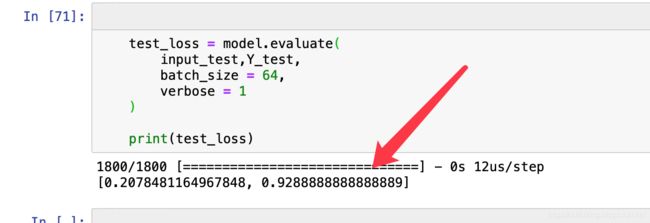
使用Bert进行情感分类,经过模型训练之后,使用测试集进行测试,可以得到该精度达到了92.8%,训练损失为0.20。
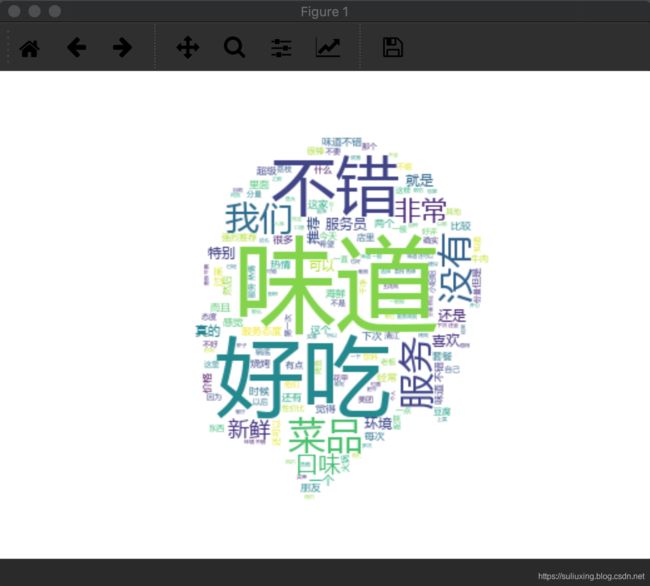
三、绘制词云
具体思路:
用jieba进行分词,还有python提供的wordcloud库。首先导入需要进行分词的文本,然后用jieba将文本进行分词,返回分词之后的结果,中文文本需要进行分词操作。然后就是设置显示方式、生成词云、将生成的词云保存到本地,然后显示出来。
d = path.dirname(__file__)
tag = np.array(Image.open(path.join(d, "Images//head.jpg")))
font_path = path.join(d,"font//msyh.ttf")
stopwords = set(STOPWORDS)
wc = WordCloud(background_color="white", # 设置背景颜色
max_words = 2000, # 词云显示的最大词数
mask = tag, # 设置背景图片
stopwords = stopwords, # 设置停用词
font_path=font_path, # 兼容中文字体,不然中文会显示乱码
)
# 生成词云
wc.generate(text)
这里不想介绍了,突然发现写得挺多的,上面就是词云构建的关键代码,通过设置各类参数然后得到词云,还可以引入不同的商家的信息进行词云建立。