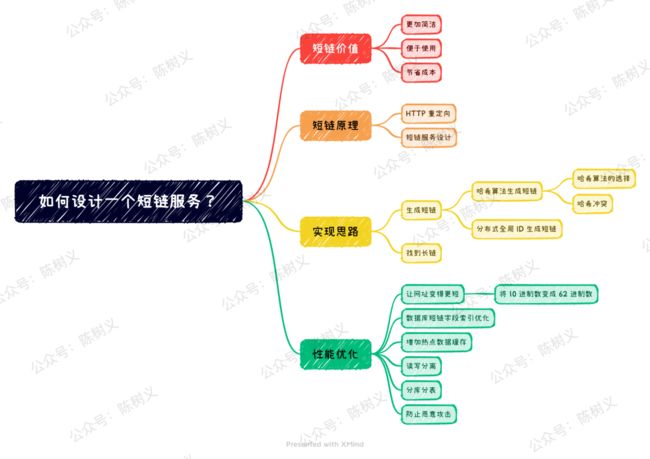
如何设计一个短链服务?
相信很多小伙伴都使用过短链服务,但如果让你实现一个短链服务,你知道怎么实现吗?其实实现短链服务并不是很难,最主要还是需要知道一些设计思路,还需要有一些基础技术知识,例如:哈希算法、全局发号器等。
短链服务的设计场景题,也是国内很多公司的面试题,很多朋友面试的时候都被问到了。今天一起来学习下如何设计一个短链服务吧!
短链的价值
网址大家都知道,很长的一串字符串,很多时候我们还会在后面添加非常多的参数,用来便于做数据统计。下面就是微信公众号一篇文章的地址,可以看到其特别长,估计将近有几百个字符。
https://mp.weixin.qq.com/s?__biz=MzA4MjIyNTY0MQ==&mid=2647743787&idx=1&sn=1caec8eb1b81d6ee5dd7ba7fa05ac0f1&chksm=87ad0dadb0da84bb7beb5e4373a14e89fba1130c1bd2a51f4baa8021ec0abe496ce94603b6b4&token=894028224&lang=zh_CN#rd
我们可以用百度的短网址功能,把上面的网址缩短成只有差不多 10 个字符串的长度,如下所示。
http://dwz.cn/iijg
用短链代替长链,有下面几个常见的好处:
-
更加简洁。 比起一长串无意义的问题,只有差不多 10 个字符的字符串显然更加简洁。
-
便于使用。 第一,有些平台对内容长度有限制(微博只能发 140 个字),此时短网址就可以输入更多内容。第二,我们将链接转为二维码时,短链接生成的二维码更容易识别。第三,有些平台无法识别特殊的长链参数,转为短链就没这个问题。
-
节省成本。 当我们需要发短信的时候,短信是按照长度计费的,短网址可以节省成本。
短链的原理
短链能够给我们带来这么多好处,但它是怎么工作的呢?
当我们输入短链时,其实访问的是短链服务器的地址。短链服务器获取到对应的长链地址之后,返回一个 302 的 HTTP 响应,在响应中包含了长链接地址。浏览器收到响应后,转而去请求长链接地址。 访问短链的整个流程如下图所示:
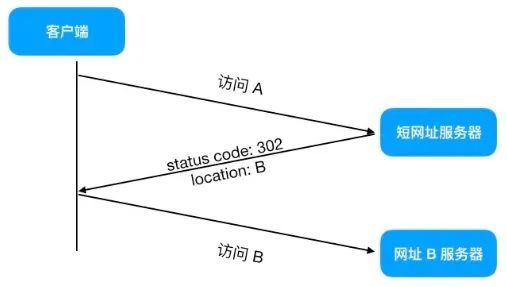
短链访问原理 - 来自网络
从上面的流程中可以知道,短链涉及到的技术原理主要有两点,分别是:HTTP 重定向和短链服务的设计。
对于 HTTP 重定向来说,301 和 302 都是重定向,那么到底应该用哪个呢?
-
301 代表永久重定向。它表示第一次拿到长链接之后,下次浏览器如果再去请求短链的话,不会再向短链服务器请求了,而是直接从浏览器的缓存中获取。
-
302 代表临时重定向。它表示每次请求短链都会去请求短链服务器,不会从浏览器缓存中获取。
如果我们希望统计短链接的点击次数信息,从而来分析活动的效果的话。那么我们就需要使用 302 重定向码,这样才能获取到每次的请求数据。 一般情况下,我们都是需要获取到请求的数据的,因此对于短链服务都是用 302 临时重定向。
实现思路
让大家设计这样一个系统,大家会有啥思路呢?
我们可以先分析一下整个系统的处理流程:
-
用户访问短链生成页面,输入长链字符串,短链服务返回生成的短链。
-
用户访问短链,短链服务返回 302 响应,用户浏览器跳转到长链地址。
如果我们要实现上面的系统流程,我们大致的处理思路是:
-
生成短链。 生成短链时,短链服务获取到长链,随后生成一个短链,并把短链与长链的映射关系保存下来,最后将短链返回给用户。
-
找到长链。 访问短链时,短链服务获取到短链,根据短链去获取到长链,返回返回 302 响应。
根据上面的分析,我们可以知道短链系统设计主要得解决如下两个问题:
-
如何根据长链生成唯一短链?
-
如何保存短链与长链的映射关系?
对于第 2 点,保存短链与长链的映射关系,考虑到持久性的问题,我们肯定需要落库,所以使用 MySQL 表保存即可。如果有需要的话,可以在 MySQL 前做一层缓存。因此第 2 点相对来说比较简单。
对于第 1 点,我们有 2 个思路生成一个唯一短链,分别是:
-
使用哈希算法生成唯一值
-
使用分布式唯一 ID 生成作为锻炼 ID
下面我们针对这两个方案进行详细的分析。
哈希算法生成短链
要生成一个短链,我们可以将原有的长链做一次哈希,然后就可以得到一个哈希值,如下面所示。
https://mp.weixin.qq.com/s?__biz=MzA4MjIyNTY0MQ==&mid=2647743787&idx=1&sn=1caec8eb1b81d6ee5dd7ba7fa05ac0f1&chksm=87ad0dadb0da84bb7beb5e4373a14e89fba1130c1bd2a51f4baa8021ec0abe496ce94603b6b4&token=894028224&lang=zh_CN#rd
↓
29541341303115543223957290326355
那么我们遇到的第一个问题:使用什么哈希算法?
我们都知道哈希算法是一种摘要算法,它的作用是:对任意一组输入数据进行计算,得到一个固定长度的输出摘要。我们常见的哈希算法有:MD5、SHA-1、SHA-256、SHA-512 算法等。但我们最好还是使用另一种叫做 MurmurHash 的哈希算法。为什么呢?
因为 MD5 和 SHA 哈希算法,它们都是加密的哈希算法,也就是说我们无法从哈希值反向推导出原文,从而保证了原文的保密性。
但对于我们这个场景而言,我们并不关心安全性,我们关注的是运算速度以及哈希冲突。而 MurmurHash 算法是一个非加密哈希算法,所以它的速度回更快。
这时候我们会遇到第二个问题:哈希冲突
学过 HashMap 的同学都知道,哈希冲突是哈希算法不可避免的问题。而解决哈希冲突的方式有两种,分别是:链表法和重哈希法。HashMap 使用了链表法,但我们这里使用的是重哈希法。
所谓的重哈希法,指的是当发生哈希冲突的时候,我们在原有长链后面加上固定的特殊字符,后续拿出长链时再将其去掉,如下所示。
原有长链:https://mp.weixin.qq.com/s1caec8eb1b81d6ee5dd7b
↓↓
发生哈希冲突
↓↓
补上特殊字符:https://mp.weixin.qq.com/s1caec8eb1b81d6ee5dd7b[SPECIAL-CHARACTER]
↓↓
再次进行哈希
通过这种办法,我们就可以解决哈希冲突的问题了。如果再次发生,那么就再进行哈希,一直到不冲突位置。一般来说,哈希冲突的可能性微乎其微。
好了,现在我们通过哈希算法得到了一个哈希值:29541341303115543223957290326355,变成了这样:http://dwz.com/29541341303115543223957290326355。
原本很长的网址变得比较短了,但整体看起来还是有点长。
有没有办法让网址变得再短一点呢?
我们知道在网址 URL 中,常用的合法字符有 0~9、a~z、A~Z 这样 62 个字符。如果我们用哈希值与 62 取余,那么余数肯定是在 0-61 之间。
这 62 个数字刚好与 62 个合法网址字符一一对应。接着,我们再用除 62 得到的值,再次与 62 取余,一直到位 0 为止。通过这样的处理,我们就可以得到一个字符为 62 个字符、长度很短的字符串了。
上面讲有点晦涩难懂,我们来举个例子。假设我们得到的哈希值为 181338494,那么上面的处理流程为:
-
将 181338494 除以 62,得到结果为 2924814,余数为 26,此时余数 26 对应字符为 q。
-
将 2924814 除以 62,得到结果为 47174,余数为 26,此时余数 26 对应字符为 q。
-
将 47174 除以 62,得到结果为 760,余数为 54,此时余数 54 对应字符为 S。
-
省略剩余步骤
整个处理流程如下图所示:

转为 16 进制数示意图 - 来自极客时间
可以看到,我们把 181338494 这个十进制数,转成了由合法网址字符组成的「62 进制数」—— cgSqq。
到这里,我们不仅生成了短链,还将短链的长度极大地缩短了。
这就是使用哈希算法生成唯一锻炼的全部内容了,我们总结一下:首先,使用 MurmurHash 生成哈希值,并且用重哈希法解决哈希冲突的问题。接着,将 10 进制的哈希值转成 62 进制的合法网址字符,从而缩短网址长度。
分布式 ID 生成短链
上面使用哈希算法生成唯一短链的方式,相对来说是比较形象的。但其实我们也可以用分布式 ID 的方式,来完成唯一短链的生成。
例如第一次请求的长链,我们为其生成一个唯一 ID,将其长链与唯一 ID 对应起来。第二次请求,我们再为其生成一个唯一 ID,再次将长链与唯一 ID 对应起来,如下所示。
第一次请求:https://mp.weixin.qq.com/s1caec8eb1b81d6ee5dd7b
↓↓
生成短链:https://dwz.com/1021000001
第一次请求:https://mp.weixin.qq.com/s1caec8eb1b81d6ee5ff7b
↓↓
生成短链:https://dwz.com/1021000002
因为生成的唯一 ID 也可能非常长,因此我们可以采用上面同样的方式,将 10 进制的唯一 ID 转成 62 进制的合法网址字符,从而缩短字符长度。
那么接下来的问题就变成了:如何设计一个全局唯一 ID 发号器了。
对于如何设计一个全局唯一的 ID 发号器,就属于另外一个话题,我们这里就不深入探讨了。
性能优化
看到这里,我们基本上有了一个完整的思路:拿到长链地址后,可以用哈希算法或唯一 ID 分号器获取唯一字符串,从而建立长链与短链的映射关系。为了缩短短链长度,我们还可以将其用 62 进制数表示,整个短链生成过程如下图所示。
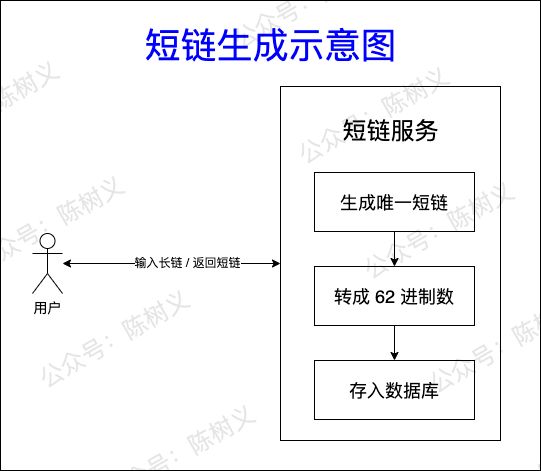
短链生成示意图
短链生成完,并且已经存到了数据库中,接下里该使用了。通常的做法是会根据请求的短链字符串,从数据库中找到数据,然后返回 HTTP 重定向原始地址。而在不断使用过程中,还有一些可能发现的优化点,这里简单讲讲。
索引优化
如果使用关系型数据库的话,对于短链字段需要创建唯一索引,从而加快查询速度。
增加缓存
并发量小的时候,我们都是直接访问数据库。但当并发量再次升高时,需要加上缓存抗住热点数据的访问。
读写分离
短链服务肯定是读远大于写的,因此对于短链服务,可以做好读写分离。
分库分表
如果是商用的短链服务,那么数据量上亿是很正常的,更不用说常年累月积累下的量了。这时候可以一开始就做好分库分表操作,避免后期再大动干戈。
对于分库分表来说,最关键的便是根据哪个字段去作为分库分表的依据了。对于短链服务来说,当然是用转化后的 62 进制数字做分表依据了,因为它是唯一的嘛。
至于怎么分库分表,就涉及到分库分表方面的知识,以及对于系统容量的预估了,这里就不细说了。有机会的话,我们找个时间来深入讲讲这方面的内容。
防止恶意攻击
开放到公网的服务,什么事情都可能发生,其中一个可能的点就是被恶意攻击,不断循环调用。
一开始我们可以做一下简单地限流操作,例如:
-
没有授权的用户,根据 IP 进行判断,1 分钟最多只能请求 10 次。
-
没有授权的用户,所有用户 1 分钟最多只能请求 4000 次,防止更换 IP 进行攻击。
简单地说,就是要不断提高攻击的成本,使得最坏情况下系统依然可以正常提供服务。
总结
本文首先讲了短链存在的三个价值:简洁、易于使用、节省成本,接着讲了短链的原理是 HTTP 重定向,最后着重讲了短链服务的设计思路。
在短链服务的设计思路上,最重要是解决两个问题:根据长链生成短链、根据短链找到长链。在根据长链生成短链的思路上,我们讲了两种实现思路,分别是:哈希算法生成短链、分布式全局 ID 生成短链,其中哈希算法涉及到哈希算法的选择,以及哈希冲突的处理。
最后我们还列举了一些短链服务后续可能的优化点,包括:如何让网址变得更短、索引优化、增加热点数据、读写分离、分库分表、防止恶意攻击等等。
如何设计一个短链服务?