【论文精读】……ConvNeXt……(CNN和Transformer打起来了,A ConvNet for the 2020s)
文章目录
- 一、Abstract(摘要):
- 二、Introduction(引言):
- 三、Modernizing a ConvNet: a Roadmap(现代化路线)
-
- 1.Macro Design模块
- 2.ResNeXt-ify模块
- 3.Inverted Bottleneck模块:
- 4.Large Kernel Sizes模块:
- 5.various layer-wise Micro Design模块
- 四、小总结
论文题目: A ConvNet for the 2020s
论文下载地址:https://arxiv.org/pdf/2201.03545.pdf
在这篇文章之前,CV领域被Transformer给刷榜了,什么Vit啊 Swim啊各种的Transformer的模型,这个作者写这篇文章 ,题目起的真的刚,20年代的卷积网络,就是想告诉你们,如今这个被Transformer占领的时代,我们CNN要重回第一。
之前的Vit或者Swim什么的都是要完全抛弃CNN,并且模型出来之后也证实了,抛弃CNN之后模型精准度等直接冲到第一了。我估计CNN阵营的大佬们看了之后坐不住了,直接发了一个这个模型,好家伙两边打起来了哈哈。
一、Abstract(摘要):
摘要的第一句 Roaring 20s 咆哮的20年代哈哈,其实就是指腾空出世的基于Transformer模型的Vit和Swim,他们已经可以说完全取代CNN作为CV领域任务的backbone,并且取得了SOTA的效果。
相较于Vit ,Swim在CV领域的下游任务中均取得了很好的效果,作者在思考取得好效果的原因,发现并不是因为Swim应用了CNN中的归纳偏置,而是Transformer的特有优势,随后作者开始参考Transformer,以ResNet为基础最优化CNN模型,毕竟是两边打架,这篇论文的作者也强调,他们无论如何优化,都是CNN模型。
摘要最后一句话,作者提出的ConvNeXt效果比Transformer好。
二、Introduction(引言):
引言的前四段都可以直接略过,都是在介绍之前的工作,害,要不是大佬的文章,我都觉得是凑字数,也可能是这种论文的必要点,学会了,我写论文的时候也这么凑字数。
不过值得关注的是他这前几段所介绍到的论文都可以读一读,虽然大部分已经读过了,MobileNet [34]、EfficientNet [71]这两个好像是轻量化网络,还没有看过,关注一下。
作者说 Vit性能的好归功于Transformer的超强的缩放行为,因其加持了关键组件MSA(多头自注意力机制)。
然后作者受到启发,开始基于Resnet50改造。
作者引言里给了张图:

在imagenet-1K数据集上,可以看到ConvNeXt的性能已经超过了Swin了。
三、Modernizing a ConvNet: a Roadmap(现代化路线)
一般论文的惯例这一章节都是准备工作,本文这里直接就开始介绍作者如何改造他的模型了。
作者直接给出了一个大图,这个图里就是作者应用各种改造手段对比原先模型所提升的效果。

也就五个模块:
- Macro Design
- ResNeXt-ify
- Inverted Bottleneck
- Large Kernel Sizes
- various layer-wise Micro Design
论文中2.1节主要是介绍他们训练的基础,作者首先利用训练vision Transformers的策略去训练原始的ResNet50模型(例如 使用AdamW 优化器),发现比原始效果要好很多,并将此结果作为后续实验的基准baseline。
下面来逐一看看各个模块。
先放一张ResNet的图,毕竟后面都是基于这个改造的。

1.Macro Design模块
这个模块里主要有两个策略,一个是stage ratio,另一个是 “patchify stem”。
- stage ratio
作者参考了Swim的stage比例去调整Resnet50的stage比例。
ResNet50中stage1到stage4堆叠block的次数是(3, 4, 6, 3)比例大概是1:1:2:1,但在Swin Transformer中,比如Swin-T的比例是1:1:3:1,Swin-L的比例是1:1:9:1。在Swin Transformer中,stage3堆叠block的占比更高。所以作者就将ResNet50中的堆叠次数由(3, 4, 6, 3)调整成(3, 3, 9, 3)。
由此带来的精度提升 78.8% -> 79.4%:

- patchify stem
这里的stem就是指模型一开始的那个下采样步骤:
Resnet里就是下面这两步:

原始的ResNet50:7 * 7 的卷积 加上 3* 3 的最大池化 = 下采样四倍。
但在Transformer模型中一般都是通过一个卷积核非常大且相邻窗口之间没有重叠的(即stride等于kernel_size)卷积层进行下采样。
比如在Swin Transformer中采用的是一个卷积核大小为4x4步长为4的卷积层构成patchify,同样是下采样4倍。
所以作者将ResNet中的stem也换成了和Swin Transformer一样的patchify。替换后准确率从79.4% 提升到79.5%,并且FLOPs也降低了一点:

2.ResNeXt-ify模块
先说一下分组卷积 grouped convolution:
将卷积的输入feature map分成组,每个卷积核也相应地分成组,在对应的组内做卷积,如上图所示,图中分组数,即上面的一组feature map只和上面的一组卷积核做卷积,下面的一组feature map只和下面的一组卷积核做卷积。每组卷积都生成一个feature map,共生成2个feature map。
group conv常用在轻量型高效网络中,因为它用少量的参数量和运算量就能生成大量的feature map,大量的feature map意味着能够编码更多的信息!
从分组卷积的角度来看,分组数g就像一个控制旋钮,最小值是1,此时的g=1卷积就是普通卷积;最大值是输入feature map的通道数C,此时g=C的卷积就是depthwise sepereable convolution,即深度分离卷积,又叫逐通道卷积。
论文中直接使用 depthwise convolution 我看那个意思就是深度分离卷积。
深度分离卷积:

如上图所示,深度分离卷积是分组卷积的一种特殊形式,其分组数,是feature map的通道数。即把每个feature map分为一组,分别在组内做卷积,组内一个卷积核生成一个feature map。这种卷积形式是最高效的卷积形式,相比普通卷积,用同等的参数量和运算量就能够生成c个feature map,而普通卷积只能生成一个feature map。
再上一张Xception里的图帮助理解深度可分离卷积:
- Xception论文精度

作者在这里就是用了Xception里的那个深度可分离卷积。
原来的ResNet50的输入维度是64,Swin-t的输入维度是96,所以作者直接照搬将本文模型改成Swin的96输入维度。
这一改动之后的精度提升:

3.Inverted Bottleneck模块:
MobileNet v2中有一个结构就是Inverted residual block(倒残差结构),在残差结构中是1x1卷积降维->3x3卷积->1x1卷积升维,在倒残差结构中正好相反,是1x1卷积升维->3x3DW卷积->1x1卷积降维。为什么要这样做,原文的解释是高维信息通过ReLU激活函数后丢失的信息更少。
本文作者认为Transformer block中的MLP模块非常像MobileNetV2中的Inverted Bottleneck模块。
下图a是ReNet中采用的Bottleneck模块,b是MobileNetV2采用的Inverted Botleneck,c是ConvNeXt采用的是Inverted Bottleneck模块。

于是作者采用Inverted Bottleneck模块后,在较小的模型上准确率由80.5%提升到了80.6%,在较大的模型上准确率由81.9%提升到82.6%。

4.Large Kernel Sizes模块:
- Moving up depthwise conv layer
即将depthwise conv模块上移,
- 原来是1x1 conv -> depthwise conv -> 1x1 conv,
- 现在变成了depthwise conv -> 1x1 conv -> 1x1 conv。
就是这个图:

这么做是因为在Transformer中,MSA模块是放在MLP模块之前的,所以这里进行效仿,将depthwise conv上移。这样改动后,准确率下降到了79.9%,同时FLOPs也减小了

- Increasing the kernel size
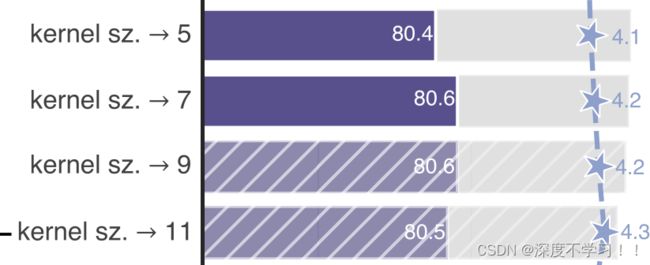
作者将depthwise conv的卷积核大小由3x3改成了7x7(和Swin Transformer一样),当然作者也尝试了其他尺寸,包括3, 5, 7, 9, 11发现取到7时准确率就达到了饱和。并且准确率从79.9% (3×3) 增长到 80.6% (7×7)。
5.various layer-wise Micro Design模块
对应原文中2.6 Micro Design。
这一节都是细小的改动。
- Replacing ReLU with GELU
在Transformer中激活函数基本用的都是GELU,而在卷积神经网络中最常用的是ReLU,于是作者又将激活函数替换成了GELU,替换后发现准确率没变化。


- Fewer activation functions
使用更少的激活函数。在卷积神经网络中,一般会在每个卷积层或全连接后都接上一个激活函数。但在Transformer中并不是每个模块后都跟有激活函数,比如MLP中只有第一个全连接层后跟了GELU激活函数。接着作者在ConvNeXt Block中也减少激活函数的使用,减少后发现准确率从80.6%增长到81.3%。

- Fewer normalization layers
使用更少的Normalization。同样在Transformer中,Normalization使用的也比较少,接着作者也减少了ConvNeXt Block中的Normalization层,只保留了depthwise conv后的Normalization层。此时准确率已经达到了81.4%,已经超过了Swin-T。

- Substituting BN with LN
将BN替换成LN。Batch Normalization(BN)在卷积神经网络中是非常常用的操作了,它可以加速网络的收敛并减少过拟合。但在Transformer中基本都用的Layer Normalization(LN),因为最开始Transformer是应用在NLP领域的,BN又不适用于NLP相关任务。接着作者将BN全部替换成了LN,发现准确率还有小幅提升达到了81.5%。

- Separate downsampling layers
单独的下采样层。在ResNet网络中stage2-stage4的下采样都是通过将主分支上3x3的卷积层步距设置成2,捷径分支上1x1的卷积层步距设置成2进行下采样的。但在Swin Transformer中是通过一个单独的Patch Merging实现的。接着作者就为ConvNext网络单独使用了一个下采样层,就是通过一个Laryer Normalization加上一个卷积核大小为2步距为2的卷积层构成。更改后准确率就提升到了82.0%。

作者也像Swim那样提出了很多的版本,C就是通道数,B就是block堆叠的stage的那个数量。

到这基本的ConvNeXt就完了,后面都是和各个模型对比的实验,大概看一遍略过了。
四、小总结
这篇论文对于大佬们来说可能是水文,没什么特别的干货,也没提出什么特别的结构或者模块。 对我们来说应该是个干货论文,我愿称之为究极消融实验调参指南。
这篇论文再次证明DL就是炼丹,文章通篇没有给出任何推论,基本都是 啊那个Transformer这样做,我拿CNN也这样做,我想向Swim靠拢(doge)。