论文阅读笔记01:深度学习技术在条纹投影三维成像中的应用
文章目录
- 01 基本原理
-
- 1.1 条纹分析
- 1.2 相位展开
- 1.3 相位与三维坐标转换
- 02 基于深度学习的条纹分析
-
- 2.1 单幅条纹分析(深度学习)
- 2.2 基于区域分块和标签增强的单幅条纹分析(深度学习)
- 2.3 条纹图像去噪
- 03 基于深度学习的相位展开
-
- 3.1 空域相位展开
-
- (1)条纹级次+后优化
- (2)一次预测
- 3.2 时域相位展开
- 04 基于深度学习的深度计算
- 05 基于深度学习的系统误差标定
- 06 基于深度学习的超快三维成像
- 07 挑战与未来研究方向
- 08 结论
标题:深度学习技术在条纹投影三维成像中的应用
作者:冯世杰,左超,尹维,陈钱
期刊:红外与激光工程
年份:2020.03
注:以后再补充,目前仅仅是作为一份论文阅读笔记。这块方法还有很多,另外还需要结合最新的3D深度学习论文找想法,打算先读大量论文,再做整个整理!
推荐读博心得:「博士期间导师教会我最重要的五件事」超爱我导师~
01 基本原理
核心:通过将立体视觉中的相机替换成光源发生器(如结构光中的投影仪,偏折术中的屏幕),主动投射特征点来实现重建功能。
系统原理示意图如下,变形的条纹即我们的特征点:
 |
|---|
| 图1 条纹投影三维成像原理 |
大致的步骤如下:
- 条纹分析:解出相位跳变的包裹相位
- 相位展开:将跳变的包裹相位展开为连续的绝对相位
- 相位与三维坐标转换标定:标定相位与三维坐标的转换关系,经过这步之后,我们得到绝对相位,即可根据绝对相位直接获取三维高度信息
下面我们来仔细讲一下每个阶段的具体细节。
1.1 条纹分析
参考链接:结构光相移法-多频外差原理+实践(上篇)
以投射的 N N N步相移图案为例,其表达式:
I n ( x , y ) = a + b cos [ φ ( x , y ) + 2 π ⋅ n N ] {I_n}\left( {x,y} \right) = a + b\cos \left[ {\varphi \left( {x,y} \right) + \frac{{2\pi \cdot n}}{N}} \right] In(x,y)=a+bcos[φ(x,y)+N2π⋅n]
注:通常,每次我们仅在一个方向上进行编码,比如编码 x x x 方向,那么 y y y 方向是完全一致的,如图1所示。
其中:
- a a a:平均光强(固定值)
- b b b:调制赋值(固定值)
- φ ( x , y ) \varphi(x,y) φ(x,y):相位值
- n = 0 , 2 , . . . , N − 1 n=0,2,...,N-1 n=0,2,...,N−1,为相移的步数
计算包裹相位 φ \varphi φ 的公式如下:
φ ( x , y ) = arctan ∑ n = 1 N I n sin ( 2 π n N ) ∑ n = 1 N I n cos ( 2 π n N ) \varphi \left( {x,y} \right) = \arctan \frac{{\sum\limits_{n = 1}^N {{I_n}\sin \left( {\frac{{2\pi n}}{N}} \right)} }}{{\sum\limits_{n = 1}^N {{I_n}\cos \left( {\frac{{2\pi n}}{N}} \right)} }} φ(x,y)=arctann=1∑NIncos(N2πn)n=1∑NInsin(N2πn)
1.2 相位展开
参考链接:结构光相移法-多频外差原理+实践(上篇)
解得的相位是包裹着的,存在 2 π 2 \pi 2π 相位跳变,为了获得连续的绝对相位,需要对其进行相位展开:
ϕ ( x , y ) = φ ( x , y ) + 2 π ⋅ k ( x , y ) \phi \left( {x,y} \right) = \varphi \left( {x,y} \right) + 2\pi \cdot k\left( {x,y} \right) ϕ(x,y)=φ(x,y)+2π⋅k(x,y)
其中:
- ϕ \phi ϕ:展开相位
- φ \varphi φ:包裹相位
- k ( x , y ) k(x,y) k(x,y):光栅级数(第几周期的条纹)
相位展开算法的目的在于确定光栅条纹的级数,得到级数,我们就可以获得连续的绝对相位。根据求取光栅级数的原理不同,可以分为两种:
- 空域相位展开
- 原理:利用相邻像素的相位值锁提供的约束来计算绝对相位值
- 缺点:该方法依赖物体表面连续假设,如果被测场景中包含多个孤立物体,或者被测物存在不连续表面边界的相邻像素的相位差值超过 2 π 2\pi 2π,则容易出现条纹级次歧义现象
- 时域相位展开
- 优点:任意复杂形状表面的包裹相位值
- 缺点:至少需要额外的一幅参考相位图
1.3 相位与三维坐标转换
参考链接:Zhang Song, GPU-assisted high-resolution, real-time 3-D shape measurement[J]. Opt. Express, 2006
TODO:后面补充这部分内容
有一种方法是,直接将“投影仪”当做“逆相机”处理。
02 基于深度学习的条纹分析
2.1 单幅条纹分析(深度学习)
单幅条纹,即空域相位解调法,传统的方法有:
- 傅里叶分析法
- 加窗傅里叶法
- 小波分析法
传统方法:
- 只适合处理表面高度变化平滑的物体,对轮廓陡变、不连续以及物体细节丰富的区域较为敏感,针对轮廓复杂物体,难以实现高精度、高分辨率的相位测量
- 需要操作者手动地设定、调节算法参数,难以完全实现自动化操作
为克服这些问题,Feng等人[40] 提出基于深度学习框架的单帧光栅条纹分析法,具体地:
TODO:细节不清楚,去看原理,估计是傅里叶。
一般而言,条纹图像可以表示为:
I ( x , y ) = A ( x , y ) + B ( x , y ) c o s [ φ ( x , y ) ] I(x,y)=A(x,y)+B(x,y)cos[\varphi(x,y)] I(x,y)=A(x,y)+B(x,y)cos[φ(x,y)]

如图2所示,结合条纹公式,构建了2个卷积神经网络:CNN1和CNN2:
- CNN1:从输入的条纹图像(I)中提取背景信息(A)
- CNN2:利用提取的背景图像(A)和原始输入图像(I),生成所需相位的正弦(M)和余弦(D)部分
最终代入反正切函数,即可得到最终的相位分布。该方法用标准12步相移算法作为标签,通过对大量样本的学习,它即可利用单幅条纹图像输出对应的高精度相位分布。
实验表明:相比较传统傅里叶方法,该方法误差降低50%以上,能够有效保持物体边界与轮廓的细节,总体测量效果接近12步相移法,实现了“高精度、高效率、全自动”。效果如图3所示:

2.2 基于区域分块和标签增强的单幅条纹分析(深度学习)
Shi等人[41]提出:
- 将原始大小为( 512 × 512 512 \times 512 512×512)图片,划分成更小,且具有领域交叠( 40 × 40 40 \times 40 40×40)的小图片作为输入
- 利用深度学习模型对进行相位计算的中间变量(光栅条纹的余弦信息)进行提取
- 对中间变量进行 H i b e r t Hibert Hibert 变换与反正切计算,计算最终相位
标签:四步像移+Shearlet变换法滤波,实现噪声抑制,如下:

2.3 条纹图像去噪
噪声存在会降低图像信噪比,进而影响相位恢复准确性,Yan[42]提出了方法,原理如下图所示:
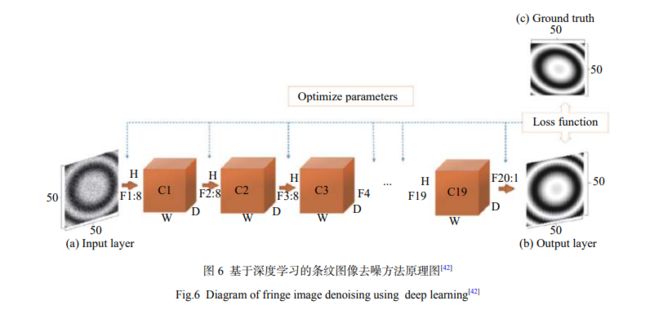
构建一个20层卷积神经网络:
- 输入:有噪声光栅图像
- 输出:抑制的光栅图像
- 标签:仿真的无噪声光栅图像
效果:

数据来自仿真。
03 基于深度学习的相位展开
基于深度学习的相位展开方法,同样分为两类:空域法和时域法。
3.1 空域相位展开
(1)条纹级次+后优化
Spoorthi G.E. 提出了PhaseNet,原理如下图所示:

输入:包裹相位,通过构建的神经网络 D C N N DCNN DCNN,使其输出条纹级次。该网络由一个编码器、解码器,和一个像素级的“分类层”组成。
另外,由于深度学习网络预测的条纹级次在 包裹相位跳变 和 存在相位陡变 区域容易发生错误进而提出 基于聚类的条纹级次后处理方法,通过合并互补的方式来增强相位空间分布的平滑度。
原始包裹相位+优化后的条纹级次,可计算最终的展开相位。效果如下所示:
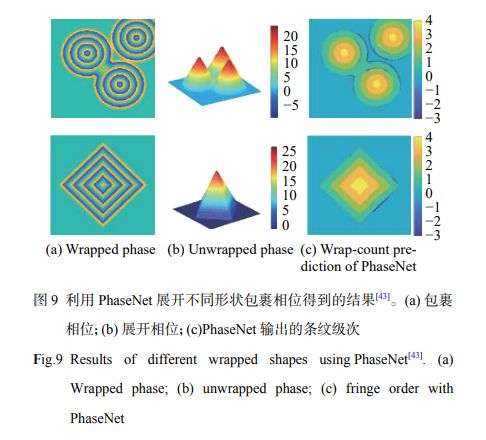
训练和测试数据来自仿真,而实际的包裹相位情况往往比仿真更复杂。
(2)一次预测
PhaseNet:预测条纹级次,再结合包裹相位,计算展开后的相位。
U-Net[44]:直接预测包裹相位对应的去包裹相位。

结果:

3.2 时域相位展开
传统方法:多频相位展开、多波长(外差)相位和数论方法。
为了提升测量效率,使用尽可能少的光栅图案,一种方法是:获取低频和高频两种频率的包裹相位。具体地:
- 低频光栅:频率为1,即投影光栅只包含一个正弦分布,帮助展开高频相位;
- 高频光栅:尽可能提升高频光栅的空间分辨率,最终三维数据的来源;
文献[45]:
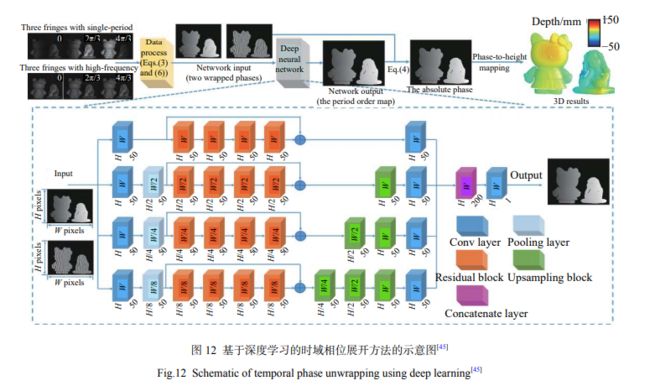
- 利用三步相移法,得到两个不同频率光栅对应的包裹相位
- 将它们作为输入,送入构建的一个四路径的卷积网络,网络经过训练,输出高频光栅包裹相位对应的条纹级次
- 结合高频包裹相位,进行相位展开,获得三维数据
功能和多频外差是一样的,但是去包裹误差更小,如下图所示:

采用深度学习辅助后,时域多频相位展开的正确率可得到大幅提升。
04 基于深度学习的深度计算
基于单幅图像的测量方法在测量速度、运动伪影的鲁棒性等方面,均优于基于多副图像的结构光技术。
Sam Vam [46] 提出完全基于深度学习的单帧光栅解调方法:从单幅变形的光栅中直接解调出表面的高度信息,结构如下图所示:

使用了仿真数据,真实数据,精度还有很大提升空间。
05 基于深度学习的系统误差标定
条纹投影将双目相机中一个相机替换成投影仪,构建了一种主动式的“双目”三维成像系统,但是投影仪的镜头与相机镜头,其在设计与功能上还是存在很大差异的,因此,简单的套用相机标定的模型,很难准确标定投影仪的畸变,进而造成三维轮廓出现失真。
文献[47]提出,如图16所示:

- 采用传统标定方法,对投影仪和相机的畸变进行校正
- 利用深度学习方法,校正剩余的投影仪畸变对三维轮廓造成的影响
LV等人,提出全连接网络:
- 输入:存在畸变残差的三维空间坐标 [ x , y , z ] T [x,y,z]^T [x,y,z]T
- 输出:该空间位置处的深度误差 Δ z \Delta z Δz
该方法用来补偿剩余畸变对三维重构造成影响。研究人员利用训练好的模型对平板测量进行验证,结果如下图所示:

需要一种精确的方式来确定不同姿态下平板表面真实三维数据。
06 基于深度学习的超快三维成像
这个方法,其实可以归位于时域相位展开,但是可以算作一个新的方向。
尽管目前 C M O S CMOS CMOS 可以实现每秒万帧、甚至百万帧的拍摄,但是由于运动模糊的关系,如何有效从拍摄到的二维图片获取三维深度图像,依然是个挑战。
文献[49],提出了微频深度轮廓术,原理如下所示:

使用三种不同频率中的相位信息,其中一幅用于重构三维轮廓,另外两幅用来辅助相位展开,最后根据标定的系统参数,重构光栅图像中包含的三维轮廓信息。
为了测试有效性,Feng设置了一个瞬态场景,包含一个静态的石膏像和一个下落的乒乓球,相机拍摄速度为20,000帧/s,记录了乒乓球落地、反弹的全过程。需要说明的是,两个物体均未在网络的训练过程中出现。

其中:
- 第一行:不同时刻拍摄的光栅图像
- 第二行:该时刻对应的重构三维模型
根据结果可知,效果还不错。
07 挑战与未来研究方向
- 学习到什么:深度学习,对研究人员来说,到底学习到了什么?
- 架构设计及优化:具体条纹应用,如计算包裹相位、相位展开、高动态范围程序等,到底什么样的神经网络合适,调参困难!
- 数据获取、标注成本高
- 神经网络泛化能力思考
- 数据驱动引入物理模型
08 结论
优势:
- 测量效率提升
- 测量精度提高
- 成像稳定性提升
缺点:
- 学习到什么
- 数据标注成本
- 泛化性能
极具发展前景!