中文自然语言处理--TextCNN文本分类(keras实现)
提到卷积神经网络(CNN),相信大部分人首先想到的是图像分类,比如 MNIST 手写体识别。CNN 已经在图像识别方面取得了较大的成果,随着近几年的不断发展,在文本处理领域,基于文本挖掘的文本卷积神经网络(textCNN)被证明是有效的。自然语言通常是一段文字,那么在特征矩阵中,矩阵的每一个行向量(比如 word2vec 或者 doc2vec)代表一个 Token,包括词或者字符。如果一段文字包含有 n 个词,每个词有 m 维的词向量,那么我们可以构造出一个 n*m 的词向量矩阵,在 NLP 处理过程中,让过滤器宽度和矩阵宽度保持一致整行滑动。
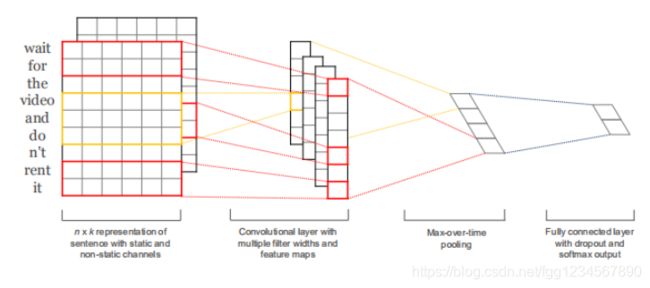
基本结构图:
from sklearn.model_selection import train_test_split
import pandas as pd
import jieba
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.utils import to_categorical
from keras.layers import Dense, Input, Flatten, Dropout, Conv1D, MaxPooling1D, BatchNormalization, concatenate
from keras.layers import Embedding
from keras.models import Sequential, Model
from sklearn import metrics
import numpy as np
from keras.utils import plot_model
from keras.models import load_model
#构建CNN分类模型(LeNet-5)
#模型结构:嵌入-卷积池化*2-dropout-BN-全连接-dropout-全连接
def CNN_model(x_train_padded_seqs, y_train, x_test_padded_seqs, y_test):
model = Sequential()
model.add(Embedding(len(vocab) + 1, 300, input_length=50)) #使用Embeeding层将每个词编码转换为词向量
model.add(Conv1D(256, 5, padding='same'))
model.add(MaxPooling1D(3, 3, padding='same'))
model.add(Conv1D(128, 5, padding='same'))
model.add(MaxPooling1D(3, 3, padding='same'))
model.add(Conv1D(64, 3, padding='same'))
model.add(Flatten())
model.add(Dropout(0.1))
model.add(BatchNormalization()) # (批)规范化层
model.add(Dense(256, activation='relu'))
model.add(Dropout(0.1))
model.add(Dense(3, activation='softmax'))
model.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy'])
print(model.summary())
#生成一个模型图,第一个参数为模型,第二个参数为要生成图片的路径及文件名,还可以指定两个参数:
#show_shapes:指定是否显示输出数据的形状,默认为False
#show_layer_names:指定是否显示层名称,默认为True
plot_model(model,to_file='./CNN_model.png', show_shapes=True, show_layer_names=True)
one_hot_labels = to_categorical(y_train, num_classes=3) # 将标签转换为one-hot编码
model.fit(x_train_padded_seqs, one_hot_labels,epochs=5, batch_size=800)
# 模型的保存
model.save('CNN_model.h5')
# 模型的加载
model = load_model('CNN_model.h5')
y_predict = model.predict_classes(x_test_padded_seqs) # 预测的是类别,结果就是类别号
y_predict = list(map(str, y_predict))
print('准确率', metrics.accuracy_score(y_test, y_predict))
print('平均f1-score:', metrics.f1_score(y_test, y_predict, average='weighted'))
# 构建TextCNN模型
# 模型结构:词嵌入-卷积池化*3-拼接-全连接-dropout-全连接
def TextCNN_model_1(x_train_padded_seqs, y_train, x_test_padded_seqs, y_test):
main_input = Input(shape=(50,), dtype='float64')
# 词嵌入(使用预训练的词向量)
embedder = Embedding(len(vocab) + 1, 300, input_length=50, trainable=False)
embed = embedder(main_input)
# 词窗大小分别为3,4,5
cnn1 = Conv1D(256, 3, padding='same', strides=1, activation='relu')(embed)
cnn1 = MaxPooling1D(pool_size=48)(cnn1)
cnn2 = Conv1D(256, 4, padding='same', strides=1, activation='relu')(embed)
cnn2 = MaxPooling1D(pool_size=47)(cnn2)
cnn3 = Conv1D(256, 5, padding='same', strides=1, activation='relu')(embed)
cnn3 = MaxPooling1D(pool_size=46)(cnn3)
# 合并三个模型的输出向量
cnn = concatenate([cnn1, cnn2, cnn3], axis=-1)
flat = Flatten()(cnn)
drop = Dropout(0.2)(flat)
main_output = Dense(3, activation='softmax')(drop)
model = Model(inputs=main_input, outputs=main_output)
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
#生成一个模型图,第一个参数为模型,第二个参数为要生成图片的路径及文件名,还可以指定两个参数:
#show_shapes:指定是否显示输出数据的形状,默认为False
#show_layer_names:指定是否显示层名称,默认为True
plot_model(model,to_file='./TextCNN_model_1.png', show_shapes=True, show_layer_names=True)
print(model.summary())
one_hot_labels = to_categorical(y_train, num_classes=3) # 将标签转换为one-hot编码
model.fit(x_train_padded_seqs, one_hot_labels, batch_size=800, epochs=10)
# 模型的保存
model.save('TextCNN_model_1.h5')
# 模型的加载
model = load_model('TextCNN_model_1.h5')
# y_test_onehot = keras.utils.to_categorical(y_test, num_classes=3) # 将标签转换为one-hot编码
result = model.predict(x_test_padded_seqs) # 预测样本属于每个类别的概率
result_labels = np.argmax(result, axis=1) # 获得最大概率对应的标签
y_predict = list(map(str, result_labels))
print('准确率', metrics.accuracy_score(y_test, y_predict))
print('平均f1-score:', metrics.f1_score(y_test, y_predict, average='weighted'))
# 构建TextCNN模型
def TextCNN_model_2(x_train_padded_seqs, y_train, x_test_padded_seqs, y_test, embedding_matrix):
# 模型结构:词嵌入-卷积池化*3-拼接-全连接-dropout-全连接
main_input = Input(shape=(50,), dtype='float64')
# 词嵌入(使用预训练的词向量)
embedder = Embedding(len(vocab) + 1, 300, input_length=50, weights=[embedding_matrix], trainable=False)
# embedder = Embedding(len(vocab) + 1, 300, input_length=50, trainable=False)
embed = embedder(main_input)
# 词窗大小分别为3,4,5
cnn1 = Conv1D(256, 3, padding='same', strides=1, activation='relu')(embed)
cnn1 = MaxPooling1D(pool_size=38)(cnn1)
cnn2 = Conv1D(256, 4, padding='same', strides=1, activation='relu')(embed)
cnn2 = MaxPooling1D(pool_size=37)(cnn2)
cnn3 = Conv1D(256, 5, padding='same', strides=1, activation='relu')(embed)
cnn3 = MaxPooling1D(pool_size=36)(cnn3)
# 合并三个模型的输出向量
cnn = concatenate([cnn1, cnn2, cnn3], axis=-1)
flat = Flatten()(cnn)
drop = Dropout(0.2)(flat)
main_output = Dense(3, activation='softmax')(drop)
model = Model(inputs=main_input, outputs=main_output)
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
print(model.summary())
#生成一个模型图,第一个参数为模型,第二个参数为要生成图片的路径及文件名,还可以指定两个参数:
#show_shapes:指定是否显示输出数据的形状,默认为False
#show_layer_names:指定是否显示层名称,默认为True
plot_model(model,to_file='./TextCNN_model_2.png', show_shapes=True, show_layer_names=True)
one_hot_labels = to_categorical(y_train, num_classes=3) # 将标签转换为one-hot编码
model.fit(x_train_padded_seqs, one_hot_labels, batch_size=800, epochs=20)
# 模型的保存
model.save('TextCNN_model_2.h5')
# 模型的加载
model = load_model('TextCNN_model_2.h5')
# y_test_onehot = to_categorical(y_test, num_classes=3) # 将标签转换为one-hot编码
result = model.predict(x_test_padded_seqs) # 预测样本属于每个类别的概率
result_labels = np.argmax(result, axis=1) # 获得最大概率对应的标签
y_predict = list(map(str, result_labels))
print('准确率', metrics.accuracy_score(y_test, y_predict))
print('平均f1-score:', metrics.f1_score(y_test, y_predict, average='weighted'))
# Keras文本预处理代码实现
if __name__ == '__main__':
dataset = pd.read_csv('./data_train.txt', sep=' ',
names=['ID', 'type', 'review', 'label']).astype(str)
cw = lambda x: list(jieba.cut(x))
dataset['words'] = dataset['review'].apply(cw)
print(dataset)
tokenizer = Tokenizer() # 创建一个Tokenizer对象
# fit_on_texts函数可以将输入的文本中的每个词编号,编号是根据词频的,词频越大,编号越小
tokenizer.fit_on_texts(dataset['words'])
vocab = tokenizer.word_index # 得到每个词的编号
print(vocab)
x_train, x_test, y_train, y_test = train_test_split(dataset['words'], dataset['label'], test_size=0.1)
# 将每个样本中的每个词转换为数字列表,使用每个词的编号进行编号
x_train_word_ids = tokenizer.texts_to_sequences(x_train)
x_test_word_ids = tokenizer.texts_to_sequences(x_test)
# 序列模式
# 每条样本长度不唯一,将每条样本的长度设置一个固定值
x_train_padded_seqs = pad_sequences(x_train_word_ids, maxlen=50) # 将超过固定值的部分截掉,不足的在最前面用0填充
x_test_padded_seqs = pad_sequences(x_test_word_ids, maxlen=50)
CNN_model(x_train_padded_seqs, y_train, x_test_padded_seqs, y_test)
TextCNN_model_1(x_train_padded_seqs, y_train, x_test_padded_seqs, y_test)
w2v_model = {"卷积":np.random.random(300), "神经网络":np.random.random(300), "作者":np.random.random(300), "。":np.random.random(300),
"模型":np.random.random(300), "很":np.random.random(300), "简单":np.random.random(300)}
# 预训练的词向量中没有出现的词用0向量表示
embedding_matrix = np.zeros((len(vocab)+1, 300))
for word, i in vocab.items():
try:
embedding_vector = w2v_model[str(word)]
embedding_matrix[i] = embedding_vector
except KeyError:
continue
print(embedding_matrix)
TextCNN_model_2(x_train_padded_seqs, y_train, x_test_padded_seqs, y_test, embedding_matrix)