模型可解释性-树结构可视化
在算法建模过程中,我们一般会用测试集的准确率与召回率衡量一个模型的好坏。但在和客户的实际沟通时,单单抛出一个数字就想要客户信任我们,那肯定是不够的,这就要求我们摆出规则,解释模型。但不是所有的模型都是规则模型,一些黑盒模型(比如神经网络)有着更高的准确率,但是无法给出具体的规则,无法让普通人理解和信任模型的预测结果。尤其当模型应用到银行业等金融领域时,透明度和可解释性是机器学习模型是否值得信任的重要考核标准。我们需要告诉业务人员如何营销,告诉风控人员如何识别风险点,而不仅仅告诉他们预测的结果。一个预测表现接近完美、却属于黑盒的人工智能模型,会容易产生误导的决策,还可能招致系统性风险,导致漏洞被攻击,因而变得不安全可靠。因此我们需要建立一个解释器来解释黑盒模型,并且这个解释器必须满足以下特征:
可解释性
要求解释器的模型与特征都必须是可解释的,像决策树、线性模型都是很适合拿来解释的模型;而可解释的模型必须搭配可解释的特征,才是真正的可解释性,让不了解机器学习的人也能通过解释器理解模型。
局部保真度
既然我们已经使用了可解释的模型与特征,就不可能期望简单的可解释模型在效果上等同于复杂模型(比如原始CNN分类器)。所以解释器不需要在全局上达到复杂模型的效果,但至少在局部上效果要很接近,而此处的局部代表我们想观察的那个样本的周围。
与模型无关
这里所指的是与复杂模型无关,换句话说无论多复杂的模型,像是SVM或神经网络,该解释器都可以工作。
除了传统的特征重要性排序外,ICE、PDP、SDT、LIME、SHAP都是揭开机器学习模型黑箱的有力工具。
- 特征重要性计算依据某个特征进行决策树分裂时,分裂前后的信息增益(基尼系数);
- ICE和PDP考察某项特征的不同取值对模型输出值的影响;
- SDT用单棵决策树解释其它更复杂的机器学习模型;
- LIME的核心思想是对于每条样本,寻找一个更容易解释的代理模型解释原模型;
- SHAP的概念源于博弈论,核心思想是计算特征对模型输出的边际贡献;
模型可解释性-SHAPE
模型可解释性-LIME
模型可解释性-树结构可视化
目录
决策树概述
测试数据集说明
树可视化方式一
树可视化方式二
树可视化方式三
决策树概述
决策树是一种基于二叉树(最多有左右两个子树)的机器学习模型。决策树遍历训练数据并将信息浓缩为二叉树的内部节点和叶节点,从而学习训练集中的观测值之间的关系,这些观测值表示为特征向量x和目标值y。(注:向量为粗体,标量为斜体。)
决策树中的每个叶子都表示特定的预测结果。回归树中输出的预测是一个(连续的)值,例如价格;而分类树中输出的预测是(离散的)目标类别(在scikit中表示为整数),例如是否患有癌症。决策树将观测分为具有相似目标值的组,每个叶子代表其中一个分组。 对于回归而言,叶节点中观测的相似性意味着目标值之间的差异很小;而对于分类而言,则意味着大多数或所有观测属于同一类别。
任何一个从树根到叶节点的路径都要经过一系列(内部)决策节点。在训练过程中选出特定的分割点后,每个决策节点将x中的单个要素的值(xi)与分割点值进行比较。例如,在预测房租的模型中,决策节点会比较特征,如卧室数量和浴室数量等。(请参阅第3章,新样本预测的可视化效果。)即使在具有目标值离散的分类模型中,决策节点仍会比较数值特征值,这是因为在scitkit中,假定决策树模型的所有特征都是数值类型,因此分类变量必须要经过独热编码、合并、标签编码等处理。
为了得到决策节点,模型将遍历训练集的子集(或根节点的完整训练集)。 在训练过程中,根据相似性最大化的原则,决策树将根据选择节点的特征和该特征空间内的分割点,将观察结果放入左右两个桶中(子集)。(该选择过程通常要对特征和特征值进行详尽的比较)左子集中样本的xi特征值均小于分割点,而右子集中样本的xi均大于分割点。通过为左分支和右分支创建决策节点,递归地进行树的构造。当达到某个停止标准(例如,节点中包含的观测数少于5)时,决策树终止生长。
决策树可视化的关键因素
决策树可视化应该突出以下重要元素,我们将在下文中具体阐述。
- 决策节点的特征vs目标值分布(在本文中称为特征-目标空间)。 我们想知道能否基于特征和分割点将观测进行分类。
- 决策节点的特征和特征分割点。 我们需要知道每个决策节点所选择的待考察的特征变量,以及将观测分类的标准。
- 叶节点纯度,这会影响我们的预测置信度。 较高的纯度也就意味着那些在回归问题中较低方差的叶节点,以及分类问题中包含绝大多数目标的叶节点,它们都意味着更可靠的预测效果。
- 叶节点预测值。 基于训练集的目标值,该叶节点具体的预测结果。
- 决策节点中的样本数。 我们需要了解决策节点上大部分样本的归属。
- 叶节点中的样本数。 我们的目标是让决策树的叶节点更少,数目更大和纯度更高。如果样本的节点下的样本数太少,则可能由过拟合现象。
- 新样本如何从根节点开始被分到特定的叶节点。 这有助于解释为什么新样本得到了相应的预测。例如,在预测公寓租金价格的回归树中,由于决策节点检查了卧室的数量,而新样本的卧室数量大于3,因此预测价格偏高。
测试数据集说明
本测试数据来源于kaggle上一个很经典的评分卡案例 Give Me Some Credit ,通过改进信用评分技术,预测未来两年借款人会遇到财务困境的可能性。银行在市场经济中发挥关键作用。 他们决定谁可以获得融资,以及以何种条件进行投资决策。 为了市场和社会的运作,个人和公司需要获得信贷。信用评分算法可以猜测违约概率,这是银行用于确定是否应授予贷款的方法。目标是建立一个借款人可以用来帮助做出最佳财务决策的模型。
数据来源:https://www.kaggle.com/c/GiveMeSomeCredit/data
数据集介绍说明:
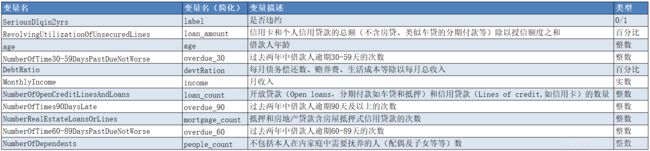
数据集示例:

数据集统计:

树可视化方式一
Graphviz 是一款由 AT&T Research 和 Lucent Bell 实验室开源的可视化图形工具,可以很方便的用来绘制结构化的图形网络,支持多种格式输出。Graphviz 的输入是一个用 dot 语言编写的绘图脚本,通过对输入脚本的解析,分析出其中的点、边及子图,然后根据属性进行绘制。
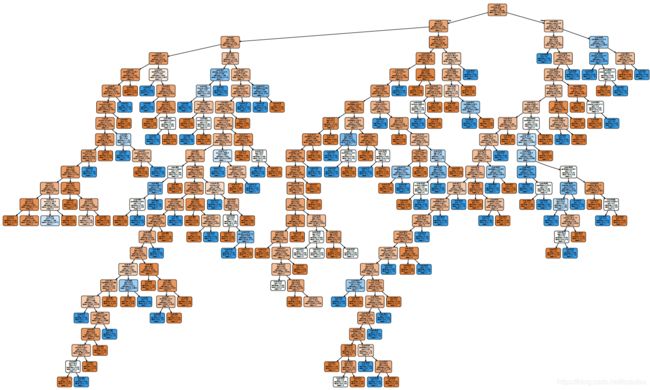
从全量的数据集中随机抽取 500 条数据做训练样本,基于Graphviz 的方式生成的树结构如下图所示(数据量越大,生成的树越复杂),其中橙色表示label为0,蓝色表示label为1,颜色的深浅表示概率的大小,最上面的为根节点,最下面的为叶子节点。
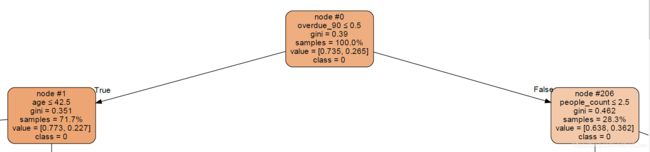
我们通过第一个节点(node #0)进行查看分析

node:节点位置,#0为0节点,#1为1节点;
overdue_90:变量名称,表示此节点根据 overdue_90 的取值进行划分,取值小于等于0.5(True)的划分到左边,大于0.5(False)0的划分到右边;
gini:基尼系数,此节点的划分标准是通过计算多个变量的基尼系数比较确定,取基尼系数最大的变量为划分标准,基尼系数最大为0.39,对应的变量 overdue_90 ,对应的变量的划分值为 0.5 ,为此外划分标准还有熵值,信息增益,增益率等;
samples:此节点划分的样本数量为多少,100%表示全部的样本进入这个节点划分;
value:此节点样本所属概率,表示74.5%概率label为0,26.5%的概率label为1(即所有的样本中初始的概率为74.5%概率label为0,26.5%的概率label为1);
class:此节点所属类别,0.735 概率 > 0.265 概率,输出label为0(即所有的样本中初始的类别为0);
通过我们上一篇文章中的 shap value 中的预测结果可视化中,基于划分树的这批数据集,我们随机抽取一个样本的变量可视化,我们看到基础值(base value)也为 0.265 (样本数量不同会导致 base value 浮动变化)

接着查看第二层节点:
所有的样本(samples = 100%)通过第一个节点(node #0)进行划分,按照变量 overdue_90 的取值进行划分,
有 71.7% 的样本,overdue_90取值小于等于0.5的(True)划分的左边节点,进入到 node #1 节点;
有 28.3% 的样本,overdue_90取值大于0.5的(False)划分的左边节点,进入到 node #206 节点;
在node #1 节点中,有 71.7% 的样本,这些样本通过计算所有变量的基尼系数,对比结果得出,基尼系数最大值为0.351,对应的变量 age,对应的变量的划分值为 42.5 ;
在node #206 节点中,有 28.3% 的样本,这些样本通过计算所有变量的基尼系数,对比结果得出,基尼系数最大值为0.462,对应的变量 people_count,对应的变量的划分值为 2.5 ;
再随机选取一部分节点查看分析:
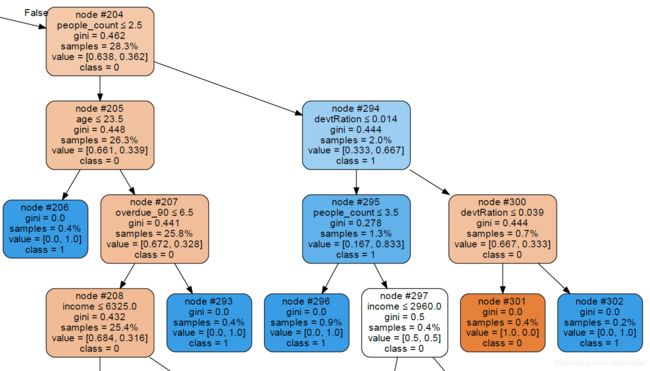
查看node #300节点,进入到此节点的有 0.7% 的样本。这 0.7% 的样本中,通过计算所有变量的基尼系数,对比结果得出,
基尼系数最大值为0.444,对应的变量 devRation,对应的变量的划分值为 0.039 ;
devRation <=0.039 的样本划分为 node301节点,进入此节点的样本全部为 class = 0 ;
devRation >0.039 的样本划分为 node302节点,进入此节点的样本全部为 class = 1 ;
node #301 和 node #302 两个节点为最下面节点(不再进行划分),称为叶子节点。
树可视化方式二
可视化软件是dtreeviz的一部分,它是一个新兴的Python机器学习库,生成的效果图如下,整体是一个树的结构,和上面树结构不同的是,每个树节点中,对所属此节点的样本分布进行条线图展示出来,可以更好的观察节点切分值的意义:

选取根节点进行查看分析
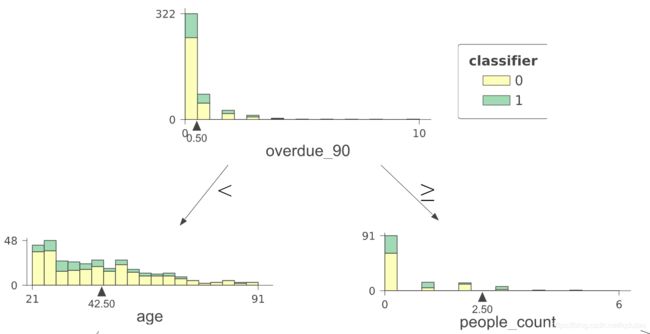
根节点的划分变量还是 overdue_90 变量,切分值为 0.50 ,overdue_90 > 0.50 的有322个样本;
基于 overdue_90 变量的所有样本的分布使用条形图展现出来;
根节点中,overdue_90 小于 0.50 的样本进入左边的节点,overdue_90 大于等于 0.50 的样本进入右边的节点,
左边的节点是以 age 变量为划分,划分值为 age=42.5 ;
右边的节点是以 people_count 变量为划分,划分值为 age=2.50 ;
随机选取一部分叶子节点查看分析:
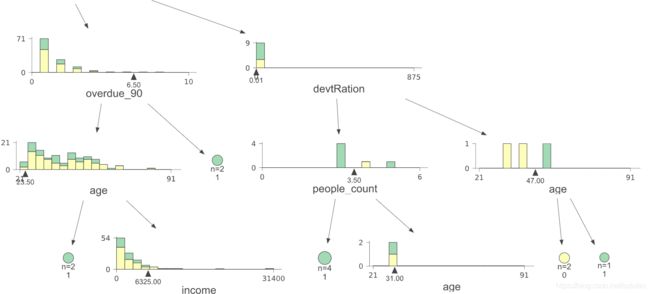
查看最右边的 age 节点,可以看到,
当 age<47的有2个样本,全部为label为0的样本,当 age>47的有1个样本,全部为label为1的样本,
可以从下面的叶子节点看到,黄色的为label为0的样本,数量为2(n=2),绿色的样本为label为1的样本(n=1)
树可视化方式三
本图的可视化软件也是dtreeviz的一部分,简化了条线图部分,使整个图看起来更简洁直观。

选取根节点查看

根节点是基于 overdue_90 变量进行划分,划分值为 0.50 ,<0.50 的划分到左边节点,>=0.50 的划分到右边节点;
划分标准都一样,省去了条线图,简化了整个图的内容;

叶子节点的表现方式保留,黄色的表示label为0的叶子节点,绿色表示label为1的叶子节点,圆圈的形状越大,表示划分到此节点的样本越多;
参考链接:https://zhuanlan.zhihu.com/p/114962861
参考链接:https://www.sohu.com/a/370408120_197042
参考链接:https://github.com/parrt/dtreeviz#classification-univariate-feature-target-space
参考链接:https://mlbook.explained.ai/