京东零售大数据云原生平台化实践
导读:今天为大家介绍京东零售大数据的云原生平台化实践,主要包括以下几大方面内容:
-
云原生的定义和理解
-
云原生相关技术的演化
-
京东大数据在云原生平台化上的实践
-
云原生应用平台的发展
分享嘉宾:刘仲伟 京东 架构师
编辑整理:张明宇 广州某银行
出品社区:DataFun
01/云原生的定义和理解
1. 云原生的定义
云原生这个概念大家已经很熟悉了,但是否有一个准确的定义呢?每个人都在说云原生,但大家对云原生的理解是不同的。
CNCF对云原生的定义如下:

很多时候,大家会想应用容器化就等于云原生化,应用上了Kubernetes是否等于云原生化,使用了Kubernetes的API是否等于云原生化?答案是不一定,因为云原生的定义在变化。
2015年CNCF成立,对云原生的定义如下:

Pivotal在2019年也对云原生做了定义。虽然Pivotal现在已经被收购,但其在云原生的定义和发展方面起了很大的作用。Pivotal对云原生的定义涉及几个方面:Devops, Continuous Delivery, Microservices和Containers。
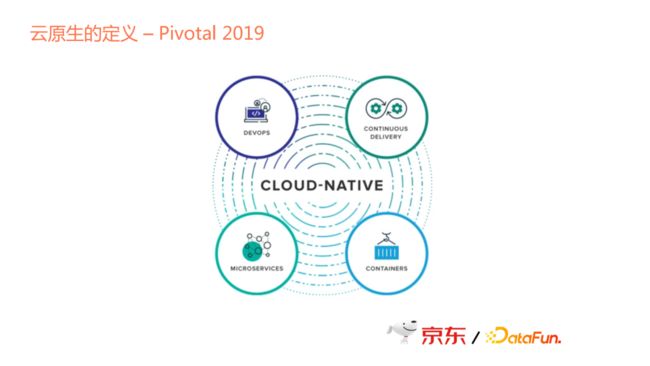
综上所述,不同公司或不同的组织,对其定义不同。随着时间的变化,云原生的定义也发生着变化。
2. 云原生的理解
我们今天所讨论的云原生是大数据范畴内的云原生。云原生可以分为云和原生两部分。

-
云(Cloud)

云(Cloud)是什么?我们回顾云的发展,起初没有云,只有Traditional On-Premises IT,经过后续的发展,云(上图中深色部分)作为提供的基础设施(或服务)变得越来越多。作为一个企业或企业的应用开发者,需要维护的东西越来越少,云会提供许多服务。
-
原生(Native)
流行词典中对native的定义如下:

如上图中所示,native相当于土著,即在何处出生、生活。前几年大家做的最多的是上云或迁移到云这个动作,即你的产品、应用并不是在云上设计的,而是在云还没有提供服务之前就已经设计好了。Hadoop刚出来时,整个生态并不是为云设计的,如果云已经像今天这样成熟的话,那么可能就是另外一个样子了,因为Yarn做的很多事情是编排调度。现在,编排调度或容器化的服务,已经完全跟Hadoop当年提出时不同,所以从Hadoop生态来说,它其实并不是On the Cloud。
对于云原生,我提出这样的理解:生于云,长于云。

生于云即应用或整个产品在设计时,是按照有云服务进行设计的,公有云、私有云或者混合云的形式,为应用或产品提供很多特性或服务。我要做的是专注于本身应用的特性和逻辑,把可扩展性、弹性、安全性等特性,放到云上或云提供的能力上来使用,而不是我的应用自己去做。
长于云是指除了在应用设计时利用云服务,在应用的维护和演进过程中,也会使用云提供的服务。随着云服务能力的不断壮大,应用的新需求也会考虑使用云服务新特性来实现,达到“长于云”。
大数据云原生意味着什么?容器化上Kubernetes的确是一种云原生,但如果现在新设计一些应用或产品,可能不只是上Kubernetes这么简单,而是要考虑这个产品哪些部分是可以剥离出来的、不用在自己的应用里面去考虑的,以及哪些部分是可以直接依托于云厂商或平台去做的。
02/云原生相关技术的演化
云原生技术有哪些?我这里列了一些时间点。

更早期的虚拟化技术我没有列,因为那些技术属于上一个时代的事情,我从docker开始。因为docker开始,大家对于容器化有了共同的认知。
2013年有了docker,2014年有了Kubernetes,但2014年Kubernetes刚发布时并未掀起太多风浪。2015年,CNCF正式成立,它把Kubernetes当成第一个项目去运作。2018年Kubernetes毕业时,云原生仿佛有了依托,上Kubernetes就变成了云原生,Kubernetes变成了一个事实性的标准。后面像Istio的发布,Knative的开源,这些技术的出现,相当于是在Kubernetes上添砖加瓦,让Kubernetes变得更加丰富,Istio相当于容器间的通信者,Knative相当于无服务器的平台框架。
如上图下方所示,云原生从微服务时代发展到服务网格时代,最后步入Serverless时代。
2021年1月,KubeVela1.0发布,KubeVela 1.0可能没有前面这几个项目那么有名。一是因为推出的时间晚,二是因为不是由Google推出。kubeVela相当于是阿里云推出的一个项目,是作为应用PaaS层的一个框架,有点类似于Knative作为一个无服务器的平台框架。
03/京东大数据在云原生平台化上的实践
1. 云原生技术选型

先看Knative这部分,上文中提到它是一个无服务的PaaS框架。对于京东大数据,Knative并不是好的选择。因为它必须是一个无状态的http服务,而且还不能挂载PVC,所以只能去做无服务器短时任务的调度。

再看Service Mesh,它通过Sidecar的方式去提供容器间通信,但这个通信有成本,因为它本来是两个app之间的通信,变成了要通过sidecar去跳,那么这个跳就意味着通信成本的增加,所以也不是很好的选择。因此,我们现在并没有直接使Service Mesh来管理容器间的通信。

除了上述几个技术之外,在开源界的另一选择是在Kubernetes上面去做Operator,就像Operators Hub,大家可以看到有很多开源服务它本身已经提供了Operator,而且也方便用,但问题是每个Operator都是各个组织自己开发的,并没有一个公共的抽象,我们想改的话,需要对每个Operator进行修改,成本很大,所以这也不是我们的选择。
2. 京东大数据的实践
接下来看一下我们在京东的云原生方式。

首先我们要定位。定位是一个PaaS层,但PaaS层是在Kubernetes的基础之上去提供一些能力,包括资源、安全、API、应用组件配置等一系列管理能力,也包括控制能力。为什么单独讲控制能力呢?因为我们做的方式跟社区的Operator逻辑一致,但又有些不同,我们把它抽象成一个统一的模型来做,而不是每个产品都做一个Operator。

业务模型分成三层,第一层是组件。Yarn里面Node Manager或Resource Manager本身就一个程序,可以定义成一个组件。
第二层是应用模版。多个组件组合在一起就是一个应用,这个应用模板定义了一个应用。比如Yarn这个应用,它由多个组件组成。一个应用可能是单组件,也可能是多个组件,每个应用可以自己灵活组装,提供了应用定义的灵活性。
第三层是系统模板。我们提供一个大数据的平台,大数据平台不是仅有一个Hadoop,而是带着一系列产品,包括HBase、Yarn、Spark,还可以带着数据传输、数据调度、数据管理、数据分析、甚至BI等一系列应用在一起,组合成一个大数据系统。
这个大数据系统可能会对不同的部门,或对不同的服务对象,可能存在不同的组合。有的可能是一个轻量级的,由最精简的几个应用组合成一个系统;有的可能很大规模,所以我们需要带一系列标准。对于后面的使用者来说,只需要一个实例化的过程就可以使用。
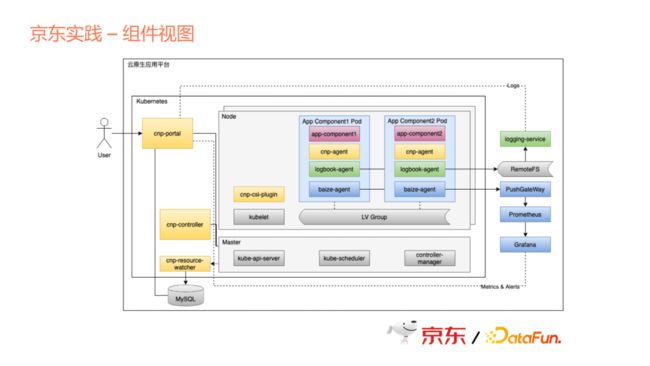
上图中可以看到我们有几个主要的组件,一个是Portal,这部分是我们的管控台,在这个管控台里面去定义上文中说的应用。从组件开始定义,组件里面又包含了各个组件的配置文件、组件的镜像image、一些动态配置,哪些配置项可以动态生成,在组件或者应用创建时,需要动态输入。
另外,上文说的去组合成一个应用模板,以及组合成一个系列,这一系列都在合作区,由用户来定义,定义之后会渲染出来Kubernetes里面一个应用crd,应用crd由controller负责生成应用。Resource Watcher也是一个重要的组件,是去watch Kubernetes上面各个资源的状态,然后再更新到外部数据库中。
我们用了Sidecar的模式提供很多应用特性。上文说到云原生的关键是可以提供一些平台级的特性,这些特性我们是作为Sidecar来以平台的方式统一提供,但是各个应用可以选择性地去配置。当然每个特性其实都在于背后的一些服务,我们会作为一个平台统一去提供。
这里其实是一个具体的翻译过程,从用户提供的具体镜像,镜像里面需要带配置文件、一些脚本、一些二进制、包括Docker file,相当于是把这些应用的差异性下沉到应用组件里面,由组件内部去控制差异性。如果把每个应用配置文件都做在每个Operator里面,必然会导致整个Operator的膨胀。所以,我们的做法更多是将这些差异性放到每个组件内部,但是我们的控制器会负责调用这些脚本,由这些脚本把差异性实现出来。
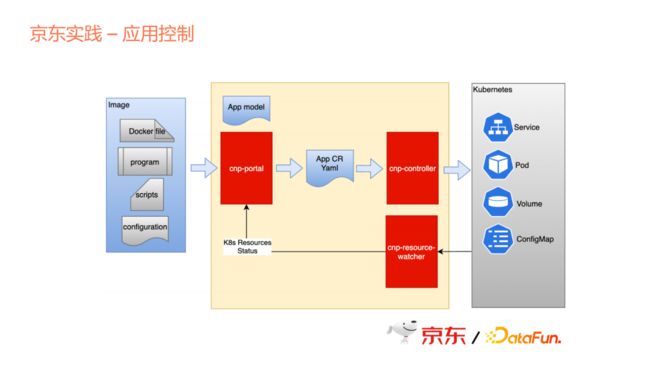
整个过程与上文相同,从Portal里面产生Application的Yaml,这是我们自定义的一个资源格式,然后再由controller翻译成Kubernetes里面的Service、Pod、Volume、ConfigMap等资源。
从这里可以看出,对于用户来说,不管是应用的生产者,还是使用者,都不需要太关心Kubernetes的这些概念。因为对于整个行业的从业者来说,Kubernetes并非一个很简单的东西,特别是随之衍生出来的Knative或者Istio,很难让大家都理解这些,并能熟练地应用所有的资源。只要我们能够提供一层平台,就可以把这些屏蔽掉,想要用哪个应用就用哪个。

再看一下应用crd的例子。
我们定义为cnp,我们内部的一个Cloud Native Platform,在这个Application里面我们可以看到它的volumes的定义,这个volumes跟Kubernetes里面的volumes不太相同,里面更多是具体的PVC的关联声明。Volumes template是我们自己独创的一个概念,在这个模板里面,可以定义这个模板如何声明,为每个Pod声明出自己对应的volume。在每个Application里面有多个Components,我们这个components是一个抽象的逻辑概念。在Application里面分成多个Components,每个component可以有自己的定义。这个是对于HBase而言的,分成Master和Region Server。这里我们特意加了一系列的Sidecar containers,这是我们平台提供的一个特性,里面提供一些监控或日志的能力。每个Sidecar会在Application里面根据Portal取得它的定义和选择,把Sidecar定义进来。
大家如果熟悉KubeVela的项目,会看到我们在概念上有一些类似,比如我们都有统一的Application,也都有Components这样的概念。但我们的特点在于我们是平台直接构建Application的能力和特性,而不是一个开发框架。
因为我们是要提供一个平台,京东内部会统一去使用,对外提供商业化服务时也是基于这个平台提供大数据产品和应用,所以并不需要把这个平台做成一个框架。
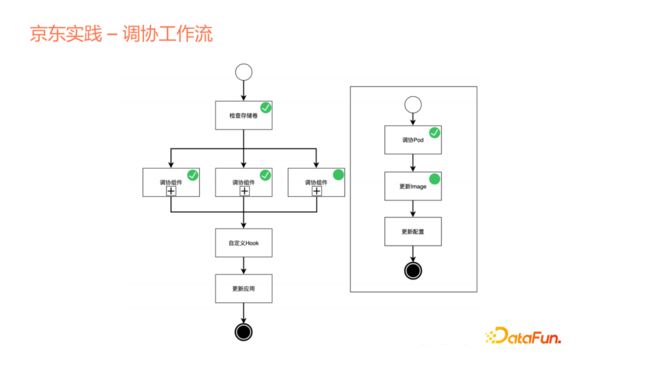
再介绍我们平台中的一个特别点——协调工作流。
上文说到我们的controller跟云原生operation里面的controller是一致的,但也有不同,不同就在于引入了工作流的概念。我们使用声明式的API来声明,或者说创建一个Application的时候,并不是让这个Application创建的过程完全变成一个controller内部的黑盒,我们是把这个controller协调的逻辑开放出来,展示给用户看,整个Application是如何去协调出来的,包括存储卷的检查、申请和后面各个组件如何去做,然后在组件内部,依然可以结合成子工作流的方式,把内部的流程再一步步展露出来。
第二个目的是可以去做自定义的Hook,这是我们平台可以支撑多个产品的一个原因。我们可以把一些Hook点暴露出来,让各个产品有机会在这些节点上去做自己的定义。比如在多个组件都已经启动后,会做集群的初始化动作,在这边定义后,会把这个命令传递到集群各个Pod里面去。另外还可以支持组件之间的传递,比如component A创建或启动之后,会产生一个dns,我们会把这个dns参数作为下一个组件的输入。这个很常见,在大数据里面,比如需要启动一个Zookeeper,启动了Zookeeper这个多节点集群之后,这个Zookeeper会作为下一个服务输入,比如Hbase或其它多个组件。

在Kubernetes的很多其他扩展work node中,不支持这种大数据里面的多shard概念。对于每个应用来说,pod相对来说是独立或平等的,在大数据里面自然存在一种shard的概念。举个例子,上了1、2、3,那1、2、3每个里面存在自己的replica,我们会支持shard的定义,既支持多shard,也支持单shard。如果存在多shard,我们会对每个shard做亲和性和反亲和性的支持。pod的命名比较有意思,对于一些多shard应用来说,我们的命名方式可以很清晰地看到这个pod是属于哪个shard里面的第几个副本分片,这也是我们的特点之一。
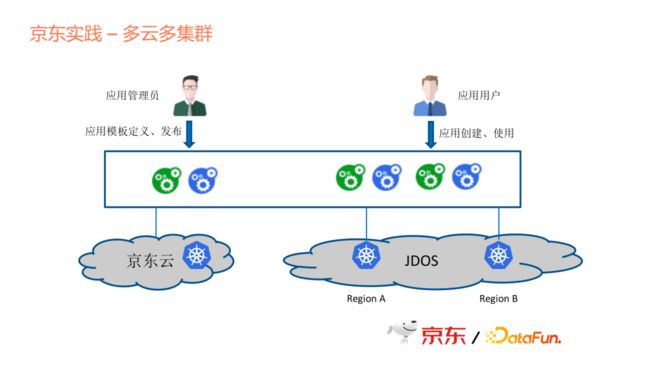
上图是一个典型的应用场景,作为一个应用管理员,京东内部的这些大数据产品里面有很多团队,每个团队集成到应用平台的时候,他来负责应用模板的定义和发布,发布到应用市场。对于用户来说,他需要做的是应用的创建和使用。
京东内部有多个云台盘,比如京东云,是对外开放的一个公有云市场,我们在京东云上面,自己申请资源去做开发和测试的一些工作。Jdos是我们的一个生产环节的云,我们在这上面将多地区多集群进行部署,然后连到平台上统一管理。但是我们现在还没有去做跨集群的部署能力,这是后面会考虑的事情。我们现在更多是把应用放在单个集群,因为从需求优先级来说,在单机群上的效率会更高。后面如果考虑多集群的高可用支持,我们也会考虑到地域分布和集群间的通信,综合考量如何去做多集群的高可用。
04/云原生应用平台的发展
我们再来看一下过去十几年PaaS的发展,也由此展望后续的发展方向。

-
Heroku
2009年提出,在推动云原生发展过程中起到了关键作用,不过Heroku在2010年就被Sales Force收购了,但现在Heroku仍然作为一个产品对外销售,它是一个企业级的应用,平台做得很成熟。但有一点很可惜,它是一个闭源的系统,你必须是一个资深的Heroku用户,才能参与到开发和定制的工作。
-
Cloud Foundry
这是第一个开源的PaaS平台,由Pivotal公司提供。
-
Openshift
Openshift是红帽的。因为它们有自己的容器化技术,不是我们后面所认知的容器化标准,所以造成了它现在的生命力问题。虽然到15年的时候,Open shift第三版兼容了Docker,但很复杂,很难迭代。从开源或者社区角度来说,大家去选择或模仿它的动力不足。
-
国内项目
Rainbond、Kubesphere是青云提供的容器云概念,把现在流行的好用的组件都装在了上面。但它并不是一个完整的应用抽象的概念,而是把一堆好用的组件集合在一起。
接下来是KubeVela,它提出的是云原生应用的概念,以应用为中心去做云原生,但它提供的是PaaS的开发框架。从我们自己的思考来看,我们并没有完全使用这样一个框架,因为我们有些思路和他们的定义并不完全一致。
我希望通过今天的这个分享引导大家去思考各自公司的云原生平台该如何设计,主要有两部分,一部分是它是否生于云,另一部分是这个平台后续的发展是不是长在云上。
今天的分享就到这里,谢谢大家。
分享嘉宾:
