知识图谱 | 阿里小蜜多模态知识图谱的构建及应用
每天给你送来NLP技术干货!
作者 | 徐国海@阿里巴巴
来源 | DataFunTalk
导读:本文由阿里巴巴达摩院阿里小蜜团队带来,介绍其在知识图谱方面一年多以来的一些工作进展。主要内容包括:
① 知识图谱的简介;② 领域知识图谱的构建及应用;③ 多模态知识图谱的构建及应用;④ Takeaways (心得领悟)。
01
知识图谱的简介
众所周知,知识图谱是对现实世界的实体概念及其关系的刻画和描述。大多以三元组为经典结构去表示知识。业界典型代表有 Google 和百度,他们通过数据挖掘方式获得了千亿级别量级的三元组。
知识图谱的典型应用其实大家也都很熟悉,比如像搜索推荐、智能问答、决策分析、智能创作等。

基于对业界的观察,阿里小蜜团队对知识图谱应用进行了解析,主要从以下两个维度出发:
第一维是应用的种类。我们将应用划分为了原图应用和算法赋能两类。
原图应用:查询图谱后获取相关信息,结果基本满足应用需求。(e.g., 搜索、推荐、问答……)
算法赋能:从图谱上获取信息后,作为下游任务模型的输入,联合建模完成应用需求。(e.g., 决策分析、智能创作、认知计算……)
原图类应用是指构建好图谱之后,从图谱中获取相应的信息,这个信息基本可以满足后面业务的特定需求。典型应用比如像搜索推荐、召回阶段、问答阶段等。
算法赋能类应用是指从图谱获取信息之后,作为下游模型的输入,通过联合建模的方式去完成业务需求。典型应用比如决策分析、智能创作等。
第二维是应用的形态。我们将应用归纳为下面三大类主要的应用形态。
业务应用:自营业务 + 数据 + 算法 (e.g., 阿里的商品知识图谱)
知识中台:平台/第三方业务 + 数据 + 服务 (e.g., 百度的知识图谱)
解决方案:算法 + 工具化 + 实施 (e.g., 阿里云、华为云)
业务应用是目前大家用的比较多的,主要是从自身业务出发去构建图片,实现对内部数据进行标准化,然后搭建相应的算法去供部门或者集团内其他部门使用的应用。
知识中台的应用形态更多的是通过不断积累数据,从而形成一个很庞大的知识中台,通过平台的方式去构建相应的服务。它既可以去服务企业内部的应用,也可以变成第三方的服务去赋能集团外的一些客户。
解决方案是指在构建和应用的过程中沉淀了很多的算法或模型,通过将这些算法模型进行工具化,进而通过上云、解决方案实施等方法,去赋能第三方客户。
下面来介绍一下阿里小蜜知识图谱的发展脉络。按照刚刚解析的过程,我们的工作大致可以分为两个阶段。第一个阶段是在客服助手、阿里小蜜阶段。会有非常多的 BU 需要问答的能力。我们尝试从业务出发,对业务知识进行结构化,从而构建相应的 KBQA(知识库问答)或者是 EBQA (Event-Based Question Answering,事件问答) 能力去完成业务。在 19 年中旬之后,我们更多的是转向去沉淀可复用的领域知识。希望从整个阿里小蜜,也就是中台的这样一个定位出发,去沉淀领域知识图谱和多模态知识图谱的工作。从而在店小蜜以及新赛道,比如虚拟主播这样的场景去得到应用。
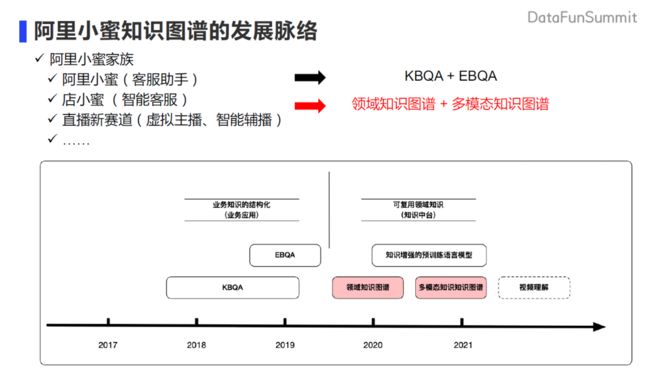
这次报告的内容主要就是介绍领域知识图谱和多模态知识图谱的一些工作。
02
领域知识图谱建设与应用
首先介绍一下领域知识图谱。
在新零售场景这样的业务场景下,它最核心的目标是如何去连接用户和商品。搜索是很好的一种方式。绝大部分用户的购物行为都是通过搜索来满足的,比如你知道自己想买什么东西,通过搜索(query)直接去搜索相应的商品。但是还是会有很多用户可能并不知道自己想买什么,或者说他选定了个商品之后,需要去咨询这个商品到底适不适合他,这就需要一个对话沟通的场景。阿里小蜜主要聚焦的就是这样的对话场景,去解决「如何有效的连接用户和商品」。

在对话场景下,经过实践,我们总结归纳了以下三个核心的问题:
问题 1:需要从用户问题推理用户诉求
问题 2:需要回答用户对商品具体信息的咨询
问题 3:推荐商品时给出解释性推荐理由,促进成交转化
在介绍核心问题之前先来看一下对话场景发生的位置。

我们把用户的消费购物决策链路划分为五个步骤。一开始用户会产生购物的需求;再到用户搜索商品;对候选的商品进行评估;评估完商品之后对部分商品做出是否需要购买的决策;最后购买商品之后会有相应的售后服务。
在需求识别阶段,对话场景中的用户会主动描述具体的一些体征,咨询产品是否合适。比如在美妆行业,用户可能会问到皮肤容易出现长痘的情况,那么希望的是我们的系统能具备推理出用户具体需求,也就是祛痘功效的能力。在评估商品的时候,用户可能会去咨询具体商品的属性,比如用户可能会去问这个商品男士、孕妇能不能用,这种情况下,用户可能更多关注商品具体的属性知识。购买决策阶段,当用户购买一个商品前与商家进行沟通的时候,我们希望我们的系统能够 get 到用户所关注的卖点,然后根据卖点去生成可解释性的推荐理由,进而更好的去促进成交转化。
以上这三个需求就是我们在对话场景中需要解决的问题。
「人、货、场」场景是电商、零售行业中非常经典的场景。但是在对话场景中会出现刚刚描述到的用户主动去表达自己的痛点的描述,比如会主动的表达长痘的痛点,那么就需要有一条链路去指导如何解决用户这个痛点。基于这个痛点去构造出该痛点所需要的诉求,如何得到所需要的诉求,以及在这个诉求之下如何去构建商品和商品的属性来满足这个诉求。所以我们又构造出另外一条链,就是商品的属性值,通过领域知识来关联商品。比如如果商品含有红没药醇这类成分的话,就具有祛痘功效。在这样的联动下,用户在表达痛点的时候,我们可以通过痛点诉求到商品属性的链路,将商品和用户的痛点关联起来。
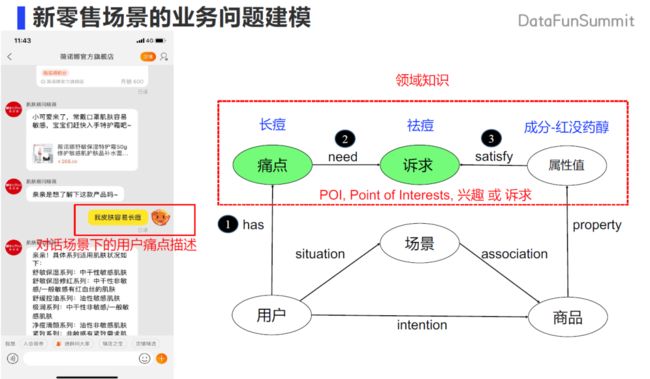
我们把诉求定义为 POI,Point of Interest,主要指用户兴趣,或者用户诉求。根据刚刚的分析,从痛点到诉求,以及属性值可以满足诉求这两类三元组,就是我们在对话场景中需要去挖掘的领域知识。这也就得到了我们 AliMe KG 领域知识图谱构建的目标「以 POI 知识去连接用户的问题和商品」。主要是挖掘三大类的知识:包括用户可能有的痛点,以及重点需要挖掘的 POI 知识,还有商品知识(其中商品知识可以从阿里已有的商品知识图谱中导入得到)。
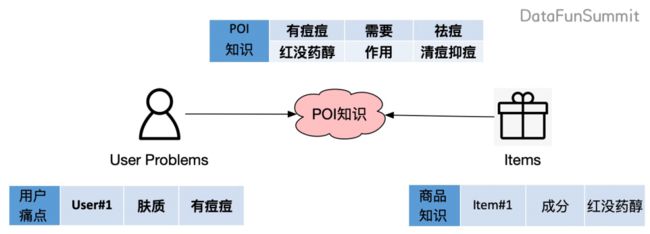
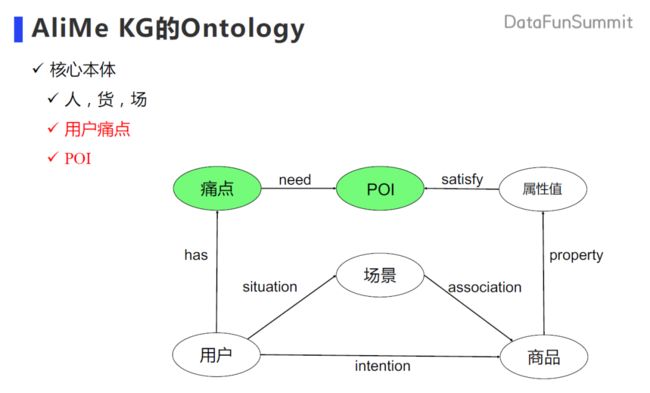
所以就得到了我们的这样一个本体的设计:在人、货、场的经典节点的基础上,增加了痛点和 POI 的节点。
后面重点讲解如何去构建这样的图谱。图谱的构建有两大类重要的技术:节点挖掘和关系构建。第一类技术是节点挖掘,它技术栈包括短语挖掘、同义词挖掘、短语 Typing 、实体识别等。第二类技术是关系构建,主要通过关系抽取从文本中挖掘出点与点之间的关系,也可以通过推理方式,比如知识补全的一些算法去做补充挖掘。
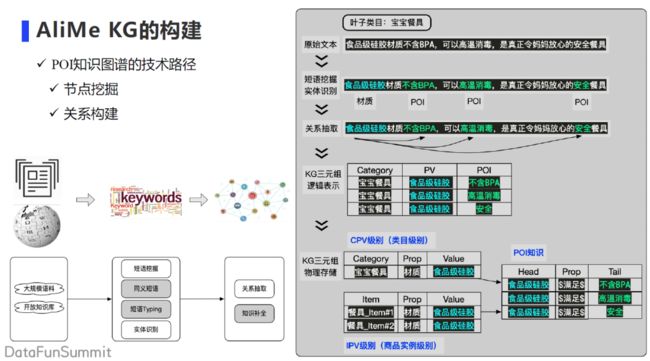
以上边的这个例子来讲解通过短语挖掘、实体识别、关系抽取如何去实现我们想要的属性值到 POI 的挖掘过程。当给定这个叶子类目是宝宝餐具时,我们会从文章中获取到相应的原始文本,通过短语挖掘来挖掘对应的词表,然后通过回标的方式训练实体识别模型,之后就可以识别出它的材质,即“食品级硅胶”,以及它的 POI,即“不含 BPA” 、“高温消毒”、“安全”等等。然后在下一个阶段,依赖关系抽取的方法去建立“食品级硅胶”和后面三个 POI 间的关系。就是说因为这个餐具它是有“食品级硅胶”的存在,所以它可以满足后面三个 POI 的逻辑关系,最终就得到了我们 KG 的逻辑表示。具体的物理存储,我们又会拆分为类目级别的信息,商品实例级别的信息以及 POI 级别的信息。
下面稍微再详细的讲一下刚刚提到了 3 个重点的技术。
1. 短语挖掘技术
远程监督获取种子短语
Wide and Deep 特征 + 随机森林分类器
Viterbi 句子解码 + EM 框架
BERT MLM 语言模型过滤 [可选]
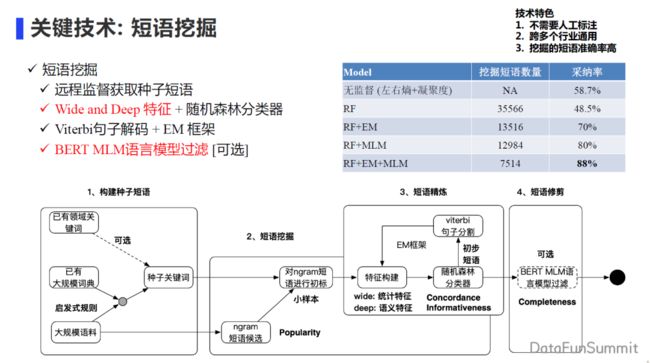
从已有的大规模字典,或者从积累的一些领域关键词中,得到种子关键词。通过种子关键词对侯选短语进行回标,得到 ngram 的正负样本,之后去构造 wide 和 deep 的特征。wide 特征主要是指一些统计特征,比如常见的 tfidf 等信息。deep 特征是 ngram 短语的 char_embedding 或者 Word embedding 等信息。之后再通过随机森林分类器去做预测。因为前面的短语的切分边界是有问题的,所以还需要通过维特比的算法检验框架进行迭代,对边界进行调整,重新统计得到更准确的统计特征。表格中实验结果可以看到该特征对挖掘效果有一个很明显的提升。最后基于大规模语言模型 BERT 的方法,再做更进一步的过滤。整个短语挖掘的框架我们是基于 AutoPhrase 方法基础上进行了改进。改进主要体现在两个方面:第一个就是刚刚提到的 wide 和 deep 的特征构造,第二个就是基于 BERT 模型会做再次的pruning,进一步提升模型的效果。
2. 实体识别技术
远程监督:基于词典回标
引入外部知识:
① Lexicon:自动短语挖掘;
② 词典知识:属性 PV 类型
CNN-CRF / FLAT-CRF
BERT-BILSTM-CRF

实体识别是指通过短语挖掘、人工标注之后,得到词典的信息,基于这个信息去回标得到大规模的弱监督语料,从而去训练模型。当然我们也会通过少量的人工标注数据去迭代和优化模型的效果。以离线模型 BERT 为例,经典的做法都是以 BERT 作为底座,基于刚刚得到的词汇特征,引入边界信息,或者基于词典特征引入类型信息。再把 BERT 的语义信息和构造的额外特征输入到 LSTM 模型中去,最终得到一个效果比较好的实体识别模型。当然在在线阶段, BERT 模型还是比较重的,很早之前我们尝试过 CNN 引入融入特征,现在改为基于 FLAT 的方式,在模型层去引入词汇和词典的特征。
3. 关系抽取技术
BILSTM + GCN + CNN
BERT + FC + softmax
+ Entity
+ 分隔符(Knowledge)
K-BERT
• ConceptNET
• HowNET
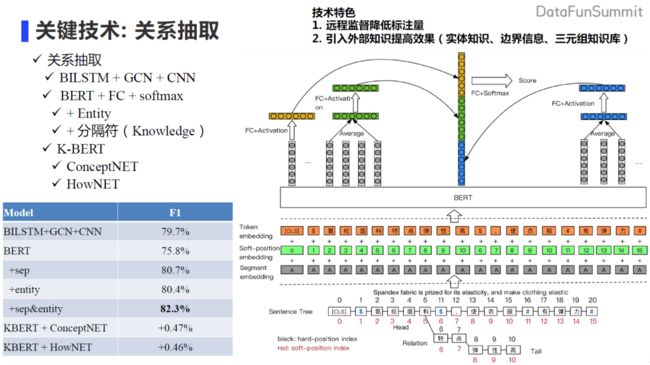
我们在关系抽取技术方面也做了大量的探索。从早期的 LSTM、 GCN 的方法,再到现在主流的 BERT 方法。这里主要讲解两大类方法,主要的核心思想还是 使用BERT 。大家可以看上面这个图的右上角,一开始我们用 BERT 的 CLS 特征,再用两个实体表示average 得到的特征,三个信息拼接之后送到 fc + softmax 中做分类,这样会得到非常好的效果。我们也尝试过基于KBERT方法引入三元组知识库的信息,得到一些效果的提升,具体数值大家可以参考表格中效果对比。
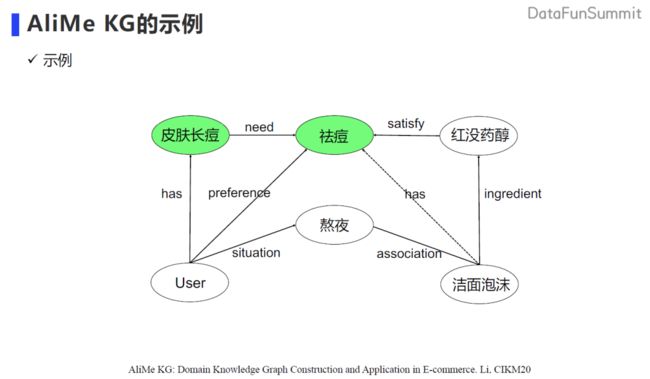
经过刚刚这样一个构建过程,我们就得到了如上图所示 AliMe KG 的一个示例。
现在阿里小蜜图谱的规模已经覆盖了重要的 50 个行业,模式层有百万级的三元组,实例层有十亿级别的三元组。同时我们会通过众包和外包结合的方式去保证这个模式层的准确性。
得到图谱之后,我们需要去应用到具体的业务。也就是去解决之前提到的对话场景中的三个问题。首先,基于痛点到诉求这条边,从用户的问题去推理用户的诉求。第二,利用商品本身的属性值信息去回答用户关于具体商品信息的咨询。第三,利用 POI 诉求来get 到用户的兴趣点,从而去生成基于商品客观属性值的一些可解释的推荐理由,更好的去促成转化。
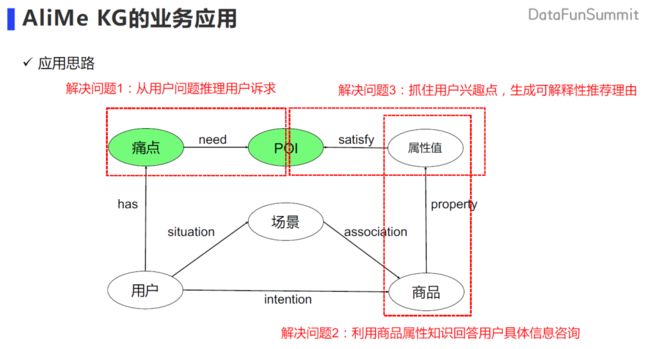
下面详细讲一下以上第一和第三个应用(第二个应用也会涉及)。
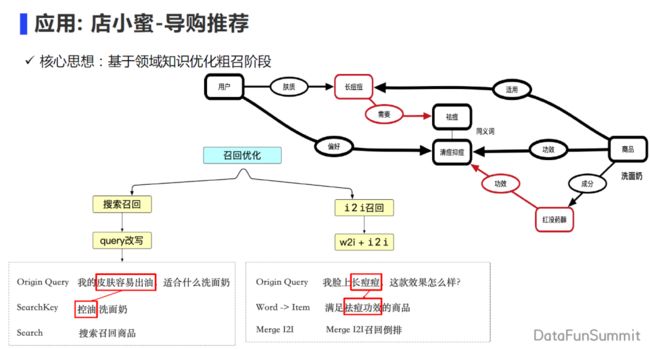
第一个应用是在导购推荐的领域,重点在召回阶段去优化粗召的环节。粗召环节主要会有两部分,第一部分是基于用户的 query 去搜索;通过用户表述自己问题,基于从问题到 POI 的改写,召回满足能解决用户问题的商品。第二部分是在 i2i 召回的阶段,我们会去基于用户的 word 词,找到对应的功效,去召回满足对应功效的商品,从而优化召回阶段。
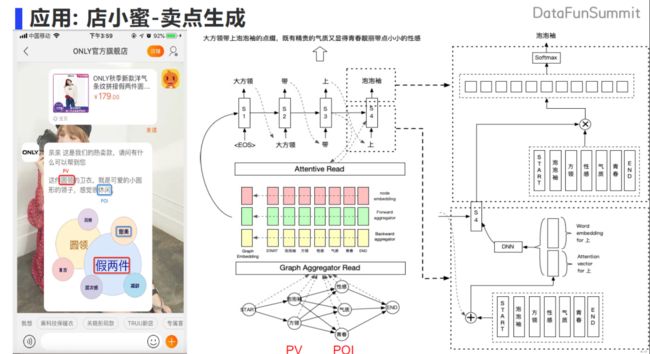
第二个应用是卖点生成。用户已经给定想咨询的商品,有潜在的购物想法,基于商品的属性,以及背后用户的画像,我们可以得知用户本身对“气质”、“青春”这类 POI 感兴趣,可以得到如下图的应用。通过 Graph Aggregator Read 的方法,得到图中每个节点的表示。通过节点得到 graph 的表示,然后再送到 decoder 模型当中。采用 attention 的方法生成对应的卖点文案。比如如图所示的业务场景,基于用户咨询到的商品,可以获知用户的兴趣点是偏休闲,就可以生成具备客观属性以及用户感兴趣 POI 内容的卖点文案,同时还可以把这个卖点子图通过 graph 的方式,可视化的展示出来。这样的应用在业务上取得不错的效果。
03
多模态知识图谱的建设与应用
多模态图谱的工作是在领域图谱的工作基础上进一步的扩展。扩展的原因是我们的业务有了新的发展。随着这个商业模式的变化,直播成为越来越多人购物选择,越来越多的人会去直播间购买商品。在直播的新赛道当中,阿里小蜜团队也打造了两款产品。虚拟主播和智能辅播。虚拟主播是一个智能的直播间虚拟人,通过自动生成图文剧本,再让虚拟人进行播报,为用户去介绍商品。智能辅播是在真人直播间构造了一个智能助理机器人,来协助主播去做商品介绍。

在直播场景下,我们希望能够去通过丰富的信息和多样的模态,让用户快速的去认知商品,进而激发用户对商品的兴趣。在这样的业务背景之下,就形成了多模态知识图谱的目标,即希望通过内容将商品介绍推送给用户。推送的内容必须有丰富的素材,素材还应具有不同模态的表达。由此也触发了我们对 AliMe MKG 本体的设计。
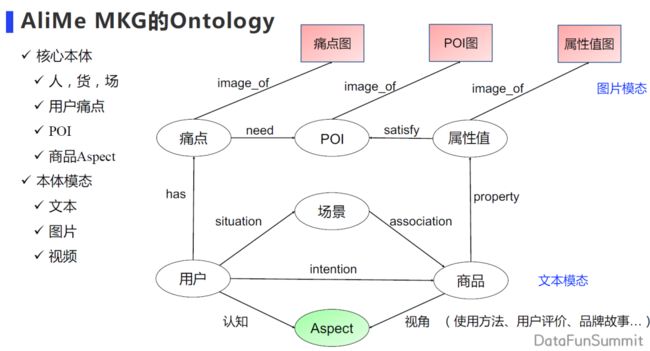
这个设计基于刚刚介绍的领域知识图谱之上,又做了两个大的优化改进。
第一个改进是模态上的扩展。如上图所示,下侧的六个节点是原先文本领域知识图谱文本的模态。在文本模态的基础上,我们希望扩展出图片、视频模态。比如痛点里面的原先只有文本描述,现在也会有痛点图片的描述,POI 也会有对应 POI 图片的描述。
第二个改进是图谱所包含内容上的扩展。原先我们会对商品打上很多场景 tag(标签),但这些标签都非常短,短的 tag 很难在直播间或者直播场景下给用户带来商品的介绍。我们希望包含商品更多的视角,这个视角可以是商品的使用方法、用户评价、品牌故事等信息,能够更好刻画商品,打造成商品的名片,让用户更好的去了解商品。在这样的一个需求之下,我们构建多模态知识图谱。
在此仅以如何去构建文本模态和图片模态的关联,来介绍图谱构建的过程。
1. AliMe MKG 的构建关键技术路径
文本知识挖掘
图片处理
多模态融合

第一个就是文本知识的挖掘,具体来说就是从文本知识挖掘得到文本节点的关联。在此基础之上,我们希望从商品内容的不同来源,去挖掘到商品对应的图片。但是这些图片都是零散的去表达这个商品的,进一步我们希望把这些图片关联到对应的文本节点上。可以通过图片分类或者图文匹配的方法来进行关联。
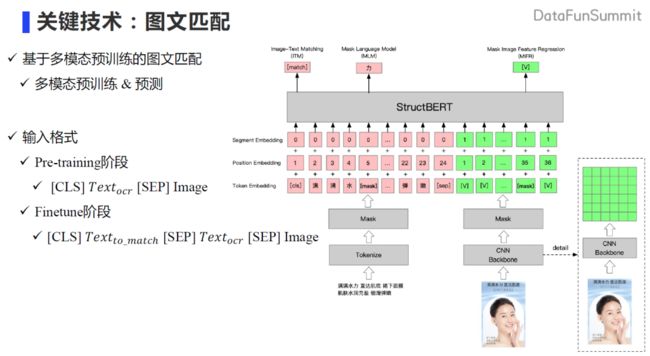
这里重点介绍图文匹配的方法。我们最大的想法是构建图谱、同时尽量少标数据。在技术调研时我们发现可以依赖多模态预训练模型的方法去做图文匹配,学术界有大量方法是采用基于目标检测来提取 ROI作为特征输入 ,但这种方法有一个劣势,就是公开的 region的类别非常有限,而且和电商领域的类别交集非常少。如果采用这个方法就需要标注大量的数据来训练模型提取 region,所以我们并没有采用这种方法。我们技术选型出发点是希望模型直接处理原始像素,因此我们整个架构是基于类似于 pixel BERT 的方式去构建的。模型输入主要是两部分,第一部分是文本信息,第二部分是图片信息,文本和图片是相对应的。文本可以利用OCR工具识别出来,通过 tokenize 分词的方法,整个过程和 BERT 的tokenize方式基本相似。如下图右边所示,提取图片的特征我们利用了 CNN 得到一个 6x6 的向量表示,进而拉平得到图像向量表示,输入到模型当中。整个的预训练任务主要有三个,第一个是图文是否匹配的任务,第二个是 mask 文本信息,这两个任务在 pixel BERT中都有利用。为了更好的实现文本信息和图片信息间交互,我们也尝试了 mask 图片的特征,通过 regression 的方式去做预测,得到了更好效果。整个的预训练的方式是这样的:在 pre-training 阶段收集了百万级别的数据去训练(文本加图片),在 finetune 阶段,将文本节点和图片节点进行匹配,输入就变成了带匹配的文本内容和图片的信息。当然这边图片的信息依然会把 OCR 的信息和图片的信息送入到模型当中去做预测。
基于刚刚的图文匹配的方法,就初步建立了现在的 AliMe MKG 多模态知识图谱。我们主要在美妆、服饰、零售三个行业得到了大量积累。商品层有百万级别,图片层达到了千万级别。
构建好这个多模态知识图谱之后,我们用它来应用和落地。直播场景下,主要是之前提到的两个产品,虚拟主播有图文剧本的生成,以及短视频的生成工作。智能辅播场景有基于多模态图谱的商品展示、商品问答工作。
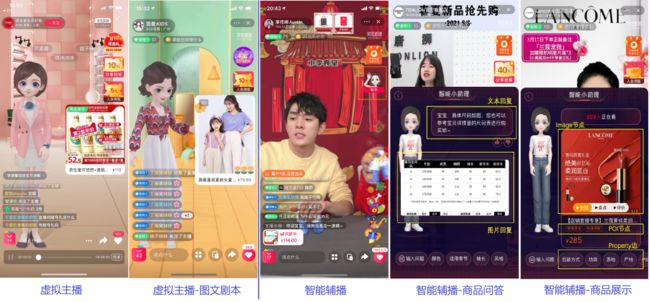
来看几个具体应用:
应用: 虚拟主播-图文剧本生成
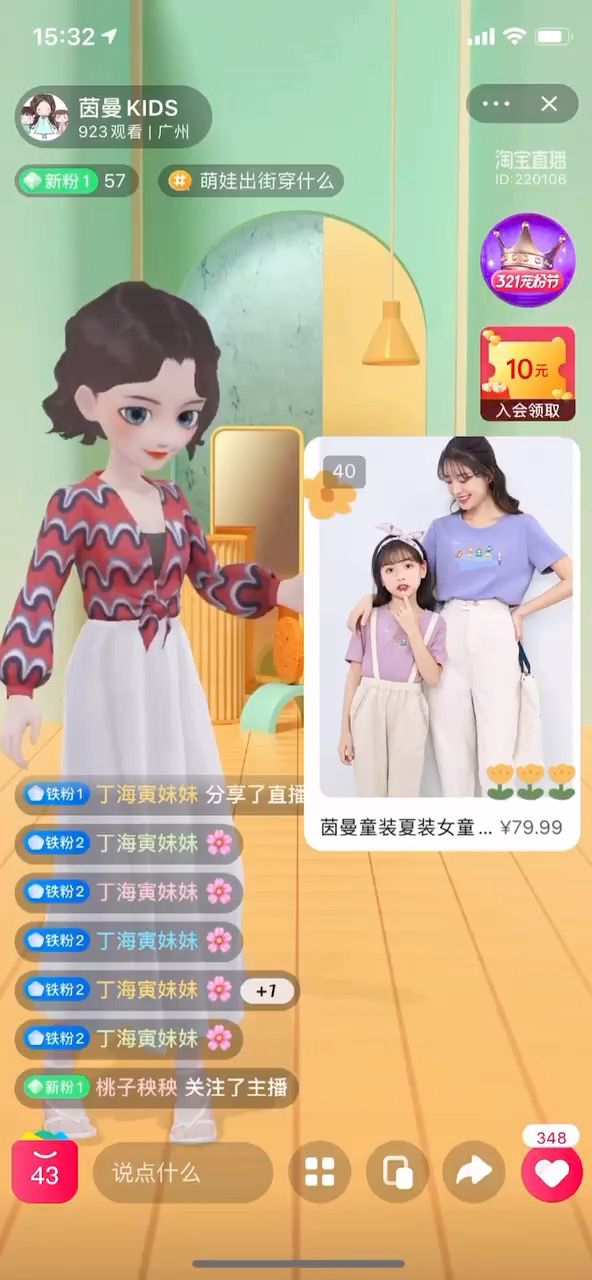
图文剧本生成
生成剧本
搭配图片
首先介绍一下虚拟主播中关于图文剧本的一些工作。如下表所示为自动生成的图文剧本。

图文剧本基本结构中属性句子、推荐理由句等素材句子都是通过图谱中的文本节点生成,或者通过挖掘、关联所得到的。得到这个剧本之后可以实时的进行图文匹配。图片也是从多模态图片中获取得到。
应用: 虚拟主播-短视频生成
短视频生成
规划路径
组织图片
生成剧本

第二个应用是短视频生成。在直播场景更多希望去产生丰富的内容,且这个内容具有吸引力。短视频就是满足这样丰富要求的非常好的表达,所以我们想基于图谱去生成短视频。短视频有两个很重要的问题需要解决,第一个问题就是合理性,或者逻辑性。视频内容的表达是需要有逻辑性的,通过在图谱上进行路径规划,从而更好满足逻辑性表达的需求。相应图片节点也可以丰富视频内容。针对图片组织之后,再去生成相应的文本剧本。知识图谱本身重点解决的就是逻辑性以及内容素材、图片素材的供给问题。第二个问题是图片与图片之间的衔接转化,以及音乐、配乐,这是另一个问题,这里暂且不讨论。
应用: 智能辅播-商品展示
商品搜索
商品澄清
商品展示
应用: 智能辅播-商品问答
基于多模态图谱的多模态回复问答

智能辅播产品里面的功能是非常丰富的,基于多模态知识图谱能够提供很多商品多模态知识展示和问答相关的功能。它能够对用户进来之后的意图去做识别,假如他对商品有意图的话肯定会去搜索商品,之后用户的 query 可能会有多个商品能够满足,比如说用户问的是口红,直播间内有多个口红。我们就会展示出来给用户进行浏览,当用户点击确认,选择一个感兴趣的口红之后,我们就会从知识图谱中抽取相应的图片节点、文本节点以及属性边信息。可以以商品卡片信息的方式,非常好的让用户和图片进行交互,可以进行放大、滑动操作。商品有比如像产地、质地等一些边的信息提供给用户,在不同模态、节点、边进行交互,从而更好的去满足他对商品的快速认知的需求。

除此之外,智能辅播商品问答可以提通多模态知识图谱的问答回复。辅播可以回答用户丰富的产品相关问题。比如用户问尺码的时候,辅播可以去推出文本介绍和对应的尺码图,用文本及图片来回答用户的咨询。
04
Takeaways
1. 小结 :
对话/推荐场景:
通过领域知识有效连接用户和商品 --> 领域知识图谱 AliMe KG
直播场景:
通过丰富的内容激发用户对商品的兴趣 --> 多模态知识图谱 AliMe MKG
本次交流主要就是围绕两个场景进行。第一个场景是就是对话场景,我们构建了领域知识图谱。通过领域知识图谱里面的 POI 知识去连接用户和商品,从而有效的解决用户显示表达自己问题,有效的满足用户购物需求的行为。第二个是直播场景,直播场景更多的是希望将商品丰富的内容展现给用户,所以多模态图谱是以内容为核心,以丰富的内容去激发用户的兴趣。
阿里小蜜在知识图谱上也遇到过非常多的问题,经过很长时间的思考与实践,我们总结出了三个我们认为非常重要的一些经验,分享给大家,希望为大家提供一些可以借鉴的价值。
2. 知识图谱的价值
① 雪中送炭
创作(文本,短视频)
冷启动(推荐的冷启动)
长尾场景(信息安全)…
② 锦上添花
知识融入
第一个是知识图谱的价值。现在做图谱工作的人越来越多,但用图谱去解决业务问题之前一定要想清楚,图谱对应用到底有什么价值?图谱本身比较大的价值是雪中送炭式的。什么叫雪中送碳呢?就是没有图谱是不行的,或者说没有图谱很难去支撑这个应用,比如智能创作的场景,需要通过图谱丰富的内容去生成文本,甚至生成短视频。再比如推荐的冷启动场景,冷启动的时候还没有积累用户和商品的交互行为,很难通过已有的一些算法去做推荐,那么就可以通过知识图谱去帮助进行平稳的过渡。长尾场景也很有价值,像信息安全对抗的场景,它会越来越多的出现长尾化的信息,模型泛化性肯定比较差,依赖实时构建的图谱去补充信息,从而更好的满足业务需求。所以说雪中送炭是知识图谱一种非常大的业务价值。但同时也有另外一种应用属于锦上添花的价值,它的价值相对比较小。因为即使不需要应用图谱,基于已有的标注数据后模型算法就已经达到非常好的效果。这时如果还想进一步提升,就可以尝试用图谱的方法去做。比如说基于知识融入方法去做提升下游任务,可以带来 1-2 个点的提升。因此,在应用知识图谱之前,业务价值必须要思考清楚,之后才能更好的对图谱的应用预期效果有一个比较准确的估计。
3. 知识图谱的应用种类
原图应用 vs. 算法赋能
第二个是知识图谱的应用种类。图谱的应用的种类主要有原图应用和算法赋能两种。如果应用方式主要是原图运用,大部分的精力一般都聚焦在如何构建这个图谱上。跟随着业务的不断发展,构建图谱的规模也会不断扩大。但是如果图谱应用是通过算法赋能的方式,去赋能下游的业务,那么在图谱构建之后,往往还需要花费比较多的时间对下游业务构建相应的算法,才能更好发挥图谱的效果。
4. 知识图谱的应用形态
业务应用 vs. 知识中台 vs. 解决方案
第三个就是应用形态。工作中经常需要去解决业务问题,可能会从业务本身出发去构建图谱,构建相应的算法,然后通过算法去解决业务问题。进一步随着业务的发展,会有越来越多的业务,那么就需要去抽象、归纳是否有可沉淀的知识,沉淀为类似于知识中台的这样的一个形态,平台化的去支持业务,以此更好的提高赋能业务的效率。再进一步就是提炼解决方案,在解决业务、做知识中台的过程中,为业务沉淀更多算法、模型,将这些算法和模型工具化,从而沉淀凝练为相应的解决方案,去解决和赋能其他业务,或者其他的合作伙伴。
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
整理不易,还望给个在看!05
References
1. 阿里小蜜团队相关工作:
· AliMe MKG: A Multi-modal Knowledge Graph for Live-streaming E-commerce. CIKM2021
· AliMe Avatar: Multi-modal Content Production and Presentation for Live-streaming E-commerce. SIGIR2021
· AliMe KG: Domain Knowledge Graph Construction and Application in E-commerce. CIKM2020
· AliMe KBQA: Question Answering over Structured Knowledge for E-commerce Customer Service.CCKS2019
· Using Event Graph to Improve Question Answering in E-commerce Customer Service. ISWC2019
· 《基于词汇增强的中文命名实体识别》,2020AICUG 人工智能社区分享
· 《结构化知识及其在阿里小蜜的应用》, 2019 知识图谱前沿技术论坛分享
2. 参考工作:
· Automated Phrase Mining from Massive Text Corpora. TKDE2018
· Mining Quality Phrases from Massive Text Corpora. SIGMOD2015
· Automated Phrase Mining from Massive Text Corpora. TKDE2018
· A Survey on Deep Learning for Named Entity Recognition. TKDE2020
· FLAT: Chinese NER Using Flat-Lattice Transformer. ACL2020
· Enriching Pre-trained Language Model with Entity Information for Relation Classification. arXiv2019
· K-BERT Enabling Language Representation with Knowledge Graph. AAAI2020
· SQL-to-Text Generation with Graph-to-Sequence Model. EMNLP2018
· Pixel-BERT: Aligning Image Pixels with Text by Deep Multi-Modal Transformers. arXiv2020