matplotlib实现散点图,数据可视化
***附:matplotlib内函数参数超详解
***附:matplotlib:颜色、标记和线类型,刻度、标签和图例,注释与子图加工
一、分析1996~2015年人口数据特征间的关系:
需求说明:
人口数据总共拥有6个特征,分别为年末总人口、男性人口、女性人口、城镇人口、乡村人口和年份。查看各个特征随着时间推移发生的变化情况可以分析出未来男女人口比例、城乡人口变化的方向。
要求:
使用NumPy库读取人口数据。
创建画布,并添加子图。
在两个子图上分别绘制散点图和折线图。
保存,显示图片。
分析未来人口变化趋势
代码:
import numpy as np
import matplotlib.pyplot as plt
#1 分析1996~2015年人口数据特征间的关系
#使用numpy库读取人口数据
data=np.load('D:/Users/Administrator/Desktop/populations.npz',allow_pickle=True)
print(data.files)#查看文件中的数组便于对其操作
print(data['data'])
print(data['feature_names'])
plt.rcParams['font.sans-serif']='SimHei'#设置中文显示
plt.rcParams['axes.unicode_minus']=False #正常显示负号
name=data['feature_names']#提取其中的feature_names数组,视为数据的标签
values=data['data']#提取其中的data数组,视为数据的存在位置
p1=plt.figure(figsize=(12,12))#确定画布大小
pip1=p1.add_subplot(2,1,1)#创建一个两行一列的子图并开始绘制
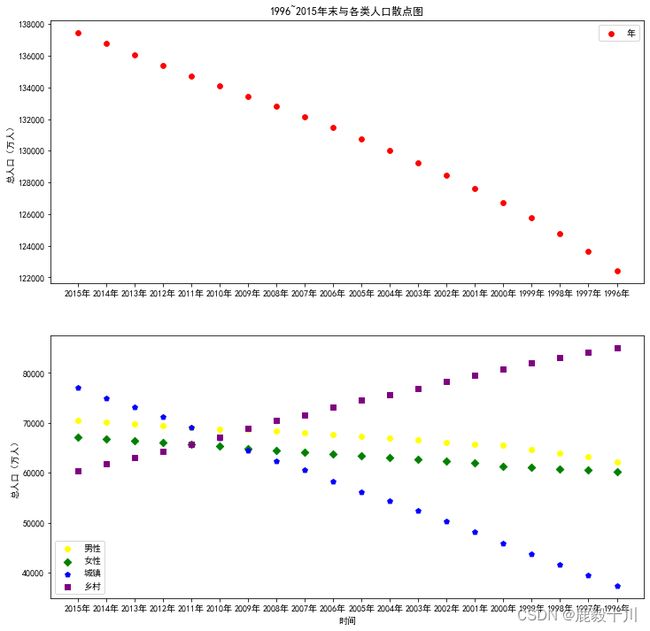
#在子图上绘制散点图
plt.scatter(values[0:20,0],values[0:20,1],marker='8',color='red')
#values[0:20,0]表示从第一列取出1到20行的数据,即年份
#values[0:20,1]表示从第二列取出1到20行的数据,即总人口(两个values表示取出两部分的值)
#marker='8'表示连线标记为八边形
plt.ylabel('总人口(万人)')#注释y轴
plt.legend('年末')#显示图例
plt.title('1996~2015年末与各类人口散点图')#图标题
pip2=p1.add_subplot(2,1,2)#绘制子图,2行1列,相当于两个子图,第2个
plt.scatter(values[0:20,0],values[0:20,2],marker='o',color='yellow')
plt.scatter(values[0:20,0],values[0:20,3],marker='D',color='green')
plt.scatter(values[0:20,0],values[0:20,4],marker='p',color='blue')
plt.scatter(values[0:20,0],values[0:20,5],marker='s',color='purple')
#分别取出时间和每类人口的数据
#'o'表示圈,'D'表示菱形,'p'表示五边形,'s'表示正方形
plt.xlabel('时间')#注释x轴
plt.ylabel('总人口(万人)')#注释y轴
plt.xticks(values[0:20,0])#把x的值传递给x轴
plt.legend(['男性','女性','城镇','乡村'])#显示图例
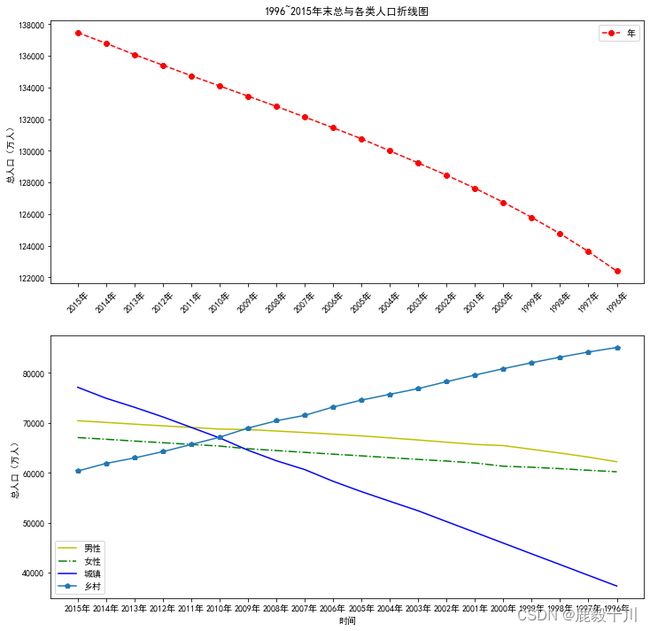
#在子图上绘制折线图
p2=plt.figure(figsize=(12,12))#确定画布大小
p1=p2.add_subplot(2,1,1)#创建一个两行一列的子图并开始绘制
plt.plot(values[0:20,0],values[0:20,1],color='r',linestyle='--',marker='8')
#linestyle='--'表示点之间的连接用'--'
plt.ylabel('总人口(万人)')#注释y轴
plt.xticks(range(0,20,1),values[range(0,20,1),0],rotation=45)#rotation设置倾斜度
plt.legend('年末')#图例
plt.title('1996~2015年末总与各类人口折线图')#标题
p2=p2.add_subplot(2,1,2)#绘制子图,2行1列,相当于两个子图,第2个
plt.plot(values[0:20,0],values[0:20,2],'y-')
plt.plot(values[0:20,0],values[0:20,3],'g-.')
plt.plot(values[0:20,0],values[0:20,4],'b-')
plt.plot(values[0:20,0],values[0:20,5],'p-')
#'y-',颜色标记和线类型的简写,表示各点用黄色以'-'连接,后面的同理
plt.xlabel('时间')
plt.ylabel('总人口(万人)')
plt.xticks(values[0:20,0])#把x的值传递给x轴
plt.legend(['男性','女性','城镇','乡村'])#图例
#显示图片
plt.show()
二、读取并查看P2P网络贷款数据主表的基本信息
需求说明:
P2P贷款主表数据主要存放了网贷用户的基本信息。探索数据的基本信息,能够洞察数据的整体分布、数据的类属关系、从而发现数据间的关联。
要求:
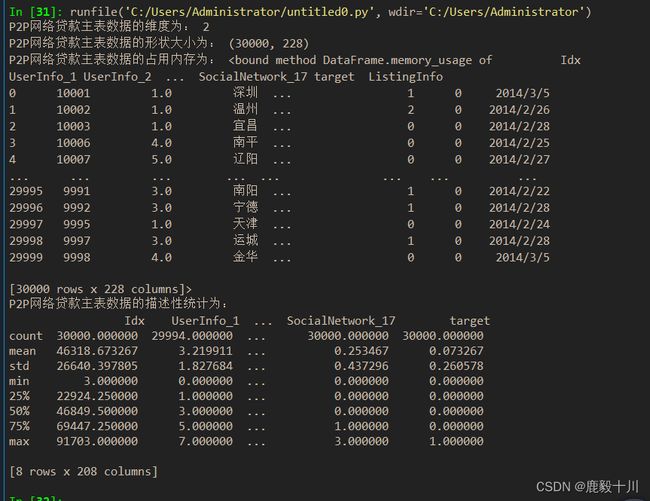
使用ndim、shape、memory_usage属性分别查看维度、大小、占用内存信息。
代码:
import os import pandas as pd #读取文件 master = pd.read_csv('D:/Users/Administrator/Desktop/Training_Master.csv',encoding='gbk') print('P2P网络贷款主表数据的维度为:',master.ndim)#查看维度 print('P2P网络贷款主表数据的形状大小为:',master.shape)#查看数据形状 print('P2P网络贷款主表数据的占用内存为:',master.memory_usage) print('P2P网络贷款主表数据的描述性统计为:\n',master.describe())
三、提取用户信息更新表和登录信息表的时间信息
需求说明:
用户信息更新表和登录信息表汇总均存在大量的时间数据,提取时间数据内存在的信息,一方面可以加深对数据的理解,另一方面能够探索这部分信息和目标的关联程度。同时用户登录时间、借款成交时间、用户信息更新时间这些时间的时间差信息冶能反映出P2P网络贷款不同用户的行为信息。
要求:
使用to_datetime函数转换用户信息更新表和登录信息表的时间字符串
代码:
import pandas as pd
# 读取文件
LogInfo = pd.read_csv('D:/Downloads/Training_LogInfo.csv',encoding='gbk')
Userupdate = pd.read_csv('D:/Downloads/Training_Userupdate.csv',encoding='gbk')
# 转换时间字符串
LogInfo['Listinginfo1']=pd.to_datetime(LogInfo['Listinginfo1'])#转换Listinginfo1列的时间
LogInfo['LogInfo3']=pd.to_datetime(LogInfo['LogInfo3'])#转换LogInfo3列的时间
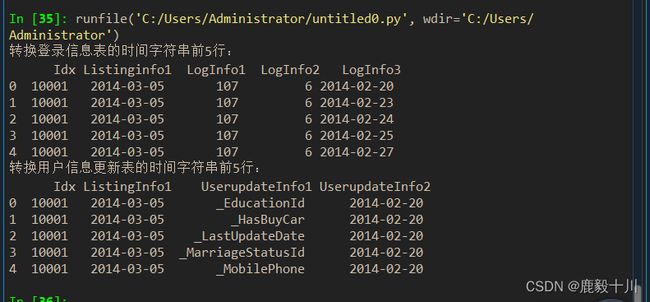
print('转换登录信息表的时间字符串前5行:\n',LogInfo.head())
Userupdate['ListingInfo1']=pd.to_datetime(Userupdate['ListingInfo1'])
Userupdate['UserupdateInfo2']=pd.to_datetime(Userupdate['UserupdateInfo2'])
print('转换用户信息更新表的时间字符串前5行:\n',Userupdate.head())
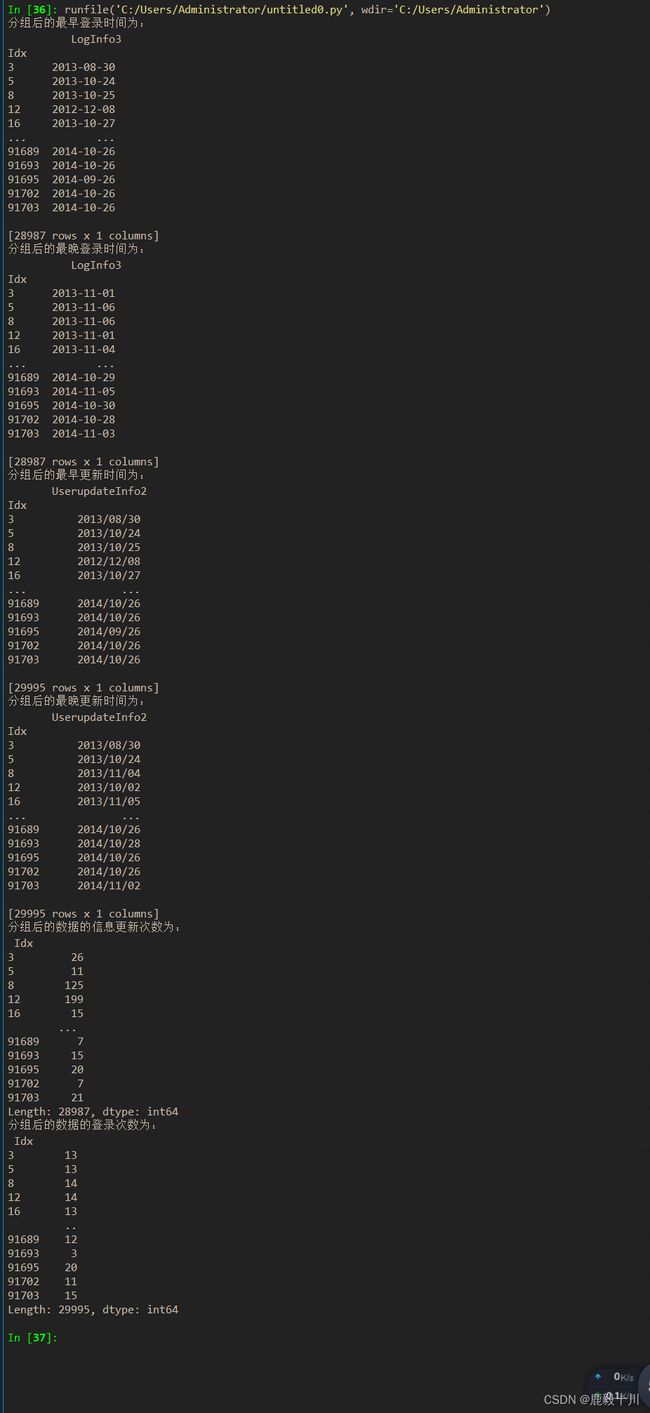
四、使用分组聚合方法进一步分析用户信息更新表和登录信息表
需求说明:
分析用户信息更新表和登录信息表时,除了提取时间本身的信息外,还可以结合用户编号进行分组聚合,然后进行组内分析。通过组内分析可以得出每组组内的最早和最晚信息更新时间、最早和最晚登录时间、信息更新的次数、登录的次数等信息。
要求:
使用groupby方法对用户信息更新表和登录信息表进行分组。
使用agg方法求取分组后的最早和最晚更新及登录时间。
使用size方法求取分组后的数据的信息更新次数与登录次数。
代码:
import pandas as pd
import numpy as np
LogInfo = pd.read_csv('D:/Downloads/Training_LogInfo.csv',encoding='gbk')
Userupdate = pd.read_csv('D:/Downloads/Training_Userupdate.csv',encoding='gbk')
# 使用groupby方法对用户信息更新表和登录信息表进行分组
LogGroup = LogInfo[['Idx','LogInfo3']].groupby(by = 'Idx')
UserGroup = Userupdate[['Idx','UserupdateInfo2']].groupby(by = 'Idx')
# 使用agg方法求取分组后的最早,最晚,更新登录时间
print('分组后的最早登录时间为:\n',LogGroup.agg(np.min))
print('分组后的最晚登录时间为:\n',LogGroup.agg(np.max))
print('分组后的最早更新时间为:\n',UserGroup.agg(np.min))
print('分组后的最晚更新时间为:\n',UserGroup.agg(np.max))
# 使用size方法求取分组后的数据的信息更新次数与登录次数
print('分组后的数据的信息更新次数为:\n',LogGroup.size())
print('分组后的数据的登录次数为:\n',UserGroup.size())