【大数据技术Hadoop+Spark】HDFS Shell常用命令及HDFS Java API详解及实战(超详细 附源码)
需要源码请点赞关注收藏后评论区留言私信~~~
一、HDFS的Shell介绍
Shell在计算机科学中俗称“壳”,是提供给使用者使用界面的进行与系统交互的软件,通过接收用户输入的命令执行相应的操作,Shell分为图形界面Shell和命令行式Shell。
文件系统(FS)Shell包含了各种的类Shell的命令,可以直接与Hadoop分布式文件系统以及其他文件系统进行交互。
常用命令如下

二、案例-Shell命令




三、HDFS的Java API
由于Hadoop是使用Java语言编写的,因此可以使用Java API操作Hadoop文件系统。HDFS Shell本质上就是对Java API的应用,通过编程的形式操作HDFS,其核心是使用HDFS提供的Java API构造一个访问客户端对象,然后通过客户端对象对HDFS上的文件进行操作(增、删、改、查)。
Hadoop整合了众多文件系统,HDFS只是这个文件系统的一个实例。

在Java中操作HDFS,创建一个客户端实例主要涉及以下两个类:
Configuration:该类的对象封装了客户端或者服务器的配置,Configuration实例会自动加载HDFS的配置文件core-site.xml,从中获取Hadoop集群的配置信息。
FileSystem:该类的对象是一个文件系统对象。
FileSystem对象的一些方法可以对文件进行操作,常用方法如下:
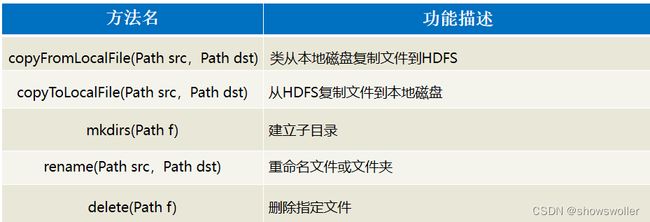
四、案例-使用Java API操作HDFS
1:搭建项目环境
创建一个项目名为“HadoopDemo”,包名为“com.chapter03”的Maven项目,并在项目的pom.xml文件中引入hadoop-common、hadoop-hdfs、hadoop-client以及单元测试junit的依赖。
2:初始化客户端对象
首先在项目src文件夹下创建com.chapter03. hdfsdemo包,并在该包下创建HDFS_API_TEST.java文件,编写Java测试类,构建Configuration和FileSystem对象,初始化一个客户端实例进行相应的操作。
3:上传文件到HDFS
由于采用Java测试类来实现JavaApi对HDFS的操作,因此可以在HDFS_CRUD.java文件中添加一个AddFileToHdfs()方法来演示本地文件上传到HDFS的示例。
4. 从HDFS下载文件到本地
在HDFS_CRUD.java文件中添加一个DownloadFileToLocal()方法,来实现从HDFS中下载文件到本地系统的功能。
5. 目录操作
在文件添加一个MkdirAndDeleteAndRename()方法,实现创建,删除,重命名文件。
6. 查看目录中的文件信息
在文件中添加一个ListFiles()方法,实现查看目录中所有文件的详细信息的功能。
java类代码如下
package com.chapter03.hdfsdemo;
import java.io.FileNotFoundException;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.BlockLocation;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.LocatedFileStatus;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.RemoteIterator;
import org.junit.Before;
import org.junit.Test;
public class HDFS_API_TEST {
FileSystem fs = null;
@Before
public void init() throws Exception {
// 构造配置参数对象
Configuration conf = new Configuration();
// 设置访问的hdfs的URI
conf.set("fs.defaultFS", "hdfs://172.16.106.69:9000");
// 设置本机的hadoop的路径
System.setProperty("hadoop.home.dir", "D:\\hadoop");
// 设置客户端访问身份
System.setProperty("HADOOP_USER_NAME", "root");
// 通过FileSystem的静态get方法获取文件系统客户端对象
fs = FileSystem.get(conf);
}
@Test
public void testAddFileToHdfs() throws IOException {
// 要上传的文件所在本地路径
Path src = new Path("D:/test.txt");
// 要上传到hdfs的目标路径
Path dst = new Path("/testFile");
// 上传文件方法
fs.copyFromLocalFile(src, dst);
// 关闭资源
fs.close();
}
// 从hdfs中复制文件到本地文件系统
@Test
public void testDownloadFileToLocal() throws IllegalArgumentException, IOException {
// 下载文件
fs.copyToLocalFile(new Path("/testFile"), new Path("D:/"));
}
// 创建,删除,重命名文件
@Test
public void testMkdirAndDeleteAndRename() throws Exception {
// 创建目录
fs.mkdirs(new Path("/test1"));
fs.rename(new Path("/test1"),new Path("/tes3"));
// 删除文件夹,如果是非空文件夹,参数2必须给值true
fs.delete(new Path("/test2"), true);
}
// 查看目录信息,只显示文件
@Test
public void testListFiles() throws FileNotFoundException, IllegalArgumentException, IOException {
// 获取迭代器对象
RemoteIterator listFiles = fs.listFiles(new Path("/"), true);
while (listFiles.hasNext()) {
LocatedFileStatus fileStatus = listFiles.next();
// 打印当前文件名
System.out.println(fileStatus.getPath().getName());
// 打印当前文件块大小
System.out.println(fileStatus.getBlockSize());
// 打印当前文件权限
System.out.println(fileStatus.getPermission());
// 打印当前文件内容长度
System.out.println(fileStatus.getLen());
// 获取该文件块信息(包含长度,数据块,datanode的信息)
BlockLocation[] blockLocations = fileStatus.getBlockLocations();
for (BlockLocation bl : blockLocations) {
System.out.println("block-length:" + bl.getLength() + "--" + "block-offset:" + bl.getOffset());
String[] hosts = bl.getHosts();
for (String host : hosts) {
System.out.println(host);
}
}
System.out.println("----------------------------");
}
}
// 查看文件及文件夹信息
@Test
public void ListFileAll() throws FileNotFoundException, IllegalArgumentException, IOException {
// 获取HDFS系统中文件和目录的元数据等信息
FileStatus[] listStatus = fs.listStatus(new Path("/"));
String filelog = "文件夹-- ";
for (FileStatus fstatus : listStatus) {
// 判断是文件还是文件夹
if (fstatus.isFile()) {
filelog = "文件-- ";
}
System.out.println(filelog + fstatus.getPath().getName());
}
}
}
创作不易 觉得有帮助请点赞关注收藏