【白板推导系列笔记】线性分类-高斯判别分析(Gaussian Discriminant Analysis)-模型求解(求期望)&模型求解(求协方差)
L ( μ 1 , μ 2 , Σ , ϕ ) = ∑ i = 1 N [ log N ( μ 1 , Σ ) y i ⏟ ( 1 ) + log N ( μ 2 , Σ ) 1 − y i ⏟ ( 2 ) + log ϕ y i ( 1 − ϕ ) 1 − y i ⏟ ( 3 ) ] L(\mu_{1},\mu_{2},\Sigma,\phi)=\sum\limits_{i=1}^{N}[\underbrace{\log N(\mu_{1},\Sigma)^{y_{i}}}_{(1)}+\underbrace{\log N(\mu_{2},\Sigma)^{1-y_{i}}}_{(2)}+\underbrace{\log \phi^{y_{i}}(1-\phi)^{1-y_{i}}}_{(3)}] L(μ1,μ2,Σ,ϕ)=i=1∑N[(1) logN(μ1,Σ)yi+(2) logN(μ2,Σ)1−yi+(3) logϕyi(1−ϕ)1−yi]
求 ϕ \phi ϕ,显然只有 ( 3 ) (3) (3)与 ϕ \phi ϕ相关
( 3 ) = ∑ i = 1 N log ϕ y i ( 1 − ϕ ) 1 − y i = ∑ i = 1 N [ y i log ϕ + ( 1 − y i ) log ( 1 − ϕ ) ] ∂ ( 3 ) ∂ ϕ = ∑ i = 1 N [ y i ⋅ 1 ϕ − ( 1 − y i ) 1 1 − ϕ ] = 0 0 = ∑ i = 1 N [ y i ⋅ ( 1 − ϕ ) − ( 1 − y i ) ϕ ] 0 = ∑ i = 1 N ( y i − y i ϕ − ϕ + y i ϕ ) 0 = ∑ i = 1 N ( y i − ϕ ) 0 = ∑ i = 1 N y i + N ϕ ϕ ^ = ∑ i = 1 N y i N \begin{aligned} (3)&=\sum\limits_{i=1}^{N}\log \phi^{y_{i}}(1-\phi)^{1-y_{i}}\\ &=\sum\limits_{i=1}^{N}[y_{i} \log \phi+(1-y_{i})\log(1-\phi)]\\ \frac{\partial (3)}{\partial \phi}&=\sum\limits_{i=1}^{N}\left[y_{i}\cdot \frac{1}{\phi}-\left(1-y_{i}\right) \frac{1}{1-\phi}\right]=0\\ 0&=\sum\limits_{i=1}^{N}[y_{i}\cdot (1-\phi)-(1-y_{i})\phi]\\ 0&=\sum\limits_{i=1}^{N}(y_{i}-y_{i}\phi-\phi+y_{i}\phi)\\ 0&=\sum\limits_{i=1}^{N}(y_{i}-\phi)\\ 0&=\sum\limits_{i=1}^{N}y_{i}+N \phi\\ \hat{\phi}&= \frac{\sum\limits_{i=1}^{N}y_{i}}{N} \end{aligned} (3)∂ϕ∂(3)0000ϕ^=i=1∑Nlogϕyi(1−ϕ)1−yi=i=1∑N[yilogϕ+(1−yi)log(1−ϕ)]=i=1∑N[yi⋅ϕ1−(1−yi)1−ϕ1]=0=i=1∑N[yi⋅(1−ϕ)−(1−yi)ϕ]=i=1∑N(yi−yiϕ−ϕ+yiϕ)=i=1∑N(yi−ϕ)=i=1∑Nyi+Nϕ=Ni=1∑Nyi
求 μ 1 \mu_{1} μ1,显然只有 ( 1 ) (1) (1)与 μ 1 \mu_{1} μ1相关。对于 μ 2 \mu_{2} μ2类似于 μ 1 \mu_{1} μ1,只需要 1 − y i 1-y_{i} 1−yi替换 y i y_{i} yi即可
( 1 ) = ∑ i = 1 N log N ( μ 1 , Σ ) y i = ∑ i = 1 N y i log 1 ( 2 π ) p 2 ∣ Σ ∣ 1 2 exp [ − 1 2 ( x i − μ 1 ) T Σ − 1 ( x i − μ 1 ) ] μ 1 = a r g m a x μ 1 ( 1 ) = a r g m a x μ 1 ∑ i = 1 N y i [ − 1 2 ( x i − μ 1 ) T Σ − 1 ( x i − μ 1 ) ] = a r g m a x μ 1 − 1 2 ∑ i = 1 N y i ( x i T Σ − 1 − μ 1 T Σ − 1 ) ( x i − μ 1 ) = a r g m a x μ 1 − 1 2 ∑ i = 1 N y i ( x i T Σ − 1 x i ⏟ ∈ R − x i T Σ − 1 μ 1 ⏟ 1 × 1 − μ 1 T Σ − 1 x i ⏟ 1 × 1 + μ 1 T Σ − 1 μ 1 ) = a r g m a x μ 1 − 1 2 ∑ i = 1 N y i ( x i T Σ − 1 x i − 2 μ 1 T Σ − 1 x i + μ 1 T Σ − 1 μ 1 ) ⏟ Δ ∂ Δ ∂ μ 1 = − 1 2 ∑ i = 1 N y i ( − 2 Σ − 1 x i + 2 Σ − 1 μ 1 ) = 0 0 = ∑ i = 1 N y i ( Σ − 1 μ 1 − Σ − 1 x i ) 0 = ∑ i = 1 N y i ( μ 1 − x i ) ∑ i = 1 N y i μ 1 = ∑ i = 1 N y i x i μ 1 ^ = ∑ i = 1 N y i x i ∑ i = 1 N y i \begin{aligned} (1)&=\sum\limits_{i=1}^{N}\log N(\mu_{1},\Sigma)^{y_{i}}\\ &=\sum\limits_{i=1}^{N}y_{i}\log \frac{1}{(2\pi)^{\frac{p}{2}}|\Sigma|^{\frac{1}{2}}}\text{exp}\left[ - \frac{1}{2}(x_{i}-\mu_{1})^{T}\Sigma^{-1}(x_{i}-\mu_{1})\right]\\ \mu_{1}&=\mathop{argmax\space}\limits_{\mu_{1}}(1)\\ &=\mathop{argmax\space}\limits_{\mu_{1}}\sum\limits_{i=1}^{N}y_{i}\left[ - \frac{1}{2}(x_{i}-\mu_{1})^{T}\Sigma^{-1}(x_{i}-\mu_{1})\right]\\ &=\mathop{argmax\space}\limits_{\mu_{1}}- \frac{1}{2}\sum\limits_{i=1}^{N}y_{i}(x_{i}^{T}\Sigma^{-1}-\mu_{1}^{T}\Sigma^{-1})(x_{i}-\mu_{1})\\ &=\mathop{argmax\space}\limits_{\mu_{1}}- \frac{1}{2}\sum\limits_{i=1}^{N}y_{i}(\underbrace{x_{i}^{T}\Sigma^{-1}x_{i}}_{\in \mathbb{R}}-\underbrace{x_{i}^{T}\Sigma^{-1}\mu_{1}}_{1 \times 1}-\underbrace{\mu_{1}^{T}\Sigma^{-1}x_{i}}_{1 \times 1}+\mu_{1}^{T}\Sigma^{-1}\mu_{1})\\ &=\mathop{argmax\space}\limits_{\mu_{1}}\underbrace{- \frac{1}{2}\sum\limits_{i=1}^{N}y_{i}(x_{i}^{T}\Sigma^{-1}x_{i}-2\mu_{1}^{T}\Sigma^{-1}x_{i}+\mu_{1}^{T}\Sigma^{-1}\mu_{1})}_{\Delta }\\ \frac{\partial \Delta }{\partial \mu_{1}}&=- \frac{1}{2}\sum\limits_{i=1}^{N}y_{i}(-2\Sigma^{-1}x_{i}+2\Sigma^{-1}\mu_{1})=0\\ 0&=\sum\limits_{i=1}^{N}y_{i}(\Sigma^{-1}\mu_{1}-\Sigma^{-1}x_{i})\\ 0&=\sum\limits_{i=1}^{N}y_{i}(\mu_{1}-x_{i})\\ \sum\limits_{i=1}^{N}y_{i}\mu_{1}&=\sum\limits_{i=1}^{N}y_{i}x_{i}\\ \hat{\mu_{1}}&=\frac{\sum\limits_{i=1}^{N}y_{i}x_{i}}{\sum\limits_{i=1}^{N}y_{i}} \end{aligned} (1)μ1∂μ1∂Δ00i=1∑Nyiμ1μ1^=i=1∑NlogN(μ1,Σ)yi=i=1∑Nyilog(2π)2p∣Σ∣211exp[−21(xi−μ1)TΣ−1(xi−μ1)]=μ1argmax (1)=μ1argmax i=1∑Nyi[−21(xi−μ1)TΣ−1(xi−μ1)]=μ1argmax −21i=1∑Nyi(xiTΣ−1−μ1TΣ−1)(xi−μ1)=μ1argmax −21i=1∑Nyi(∈R xiTΣ−1xi−1×1 xiTΣ−1μ1−1×1 μ1TΣ−1xi+μ1TΣ−1μ1)=μ1argmax Δ −21i=1∑Nyi(xiTΣ−1xi−2μ1TΣ−1xi+μ1TΣ−1μ1)=−21i=1∑Nyi(−2Σ−1xi+2Σ−1μ1)=0=i=1∑Nyi(Σ−1μ1−Σ−1xi)=i=1∑Nyi(μ1−xi)=i=1∑Nyixi=i=1∑Nyii=1∑Nyixi
这里我们设
C 1 = { x i ∣ y i = 1 , i = 1 , 2 , ⋯ , N } , ∣ C 1 ∣ = N 1 C 0 = { x i ∣ y i = 0 , i = 1 , 2 , ⋯ , N } , ∣ C 0 ∣ = N 0 N = N 1 + N 0 \begin{aligned} C_{1}&=\left\{x_{i}|y_{i}=1,i=1,2,\cdots,N\right\},|C_{1}|=N_{1}\\ C_{0}&=\left\{x_{i}|y_{i}=0,i=1,2,\cdots,N\right\},|C_{0}|=N_{0}\\ N&=N_{1}+N_{0} \end{aligned} C1C0N={xi∣yi=1,i=1,2,⋯,N},∣C1∣=N1={xi∣yi=0,i=1,2,⋯,N},∣C0∣=N0=N1+N0
因此
μ 1 ^ = ∑ i = 1 N y i x i N 1 \hat{\mu_{1}}=\frac{\sum\limits_{i=1}^{N}y_{i}x_{i}}{N_{1}} μ1^=N1i=1∑Nyixi
再用 1 − y i 1-y_{i} 1−yi替换 y i y_{i} yi得 μ 2 ^ \hat{\mu_{2}} μ2^
μ 2 ^ = ∑ i = 1 N ( 1 − y i ) x i ∑ i = 1 N ( 1 − y i ) = ∑ i = 1 N ( 1 − y i ) x i N − N 1 = ∑ i = 1 N ( 1 − y i ) x i N 0 \hat{\mu_{2}}=\frac{\sum\limits_{i=1}^{N}(1-y_{i})x_{i}}{\sum\limits_{i=1}^{N}(1-y_{i})}=\frac{\sum\limits_{i=1}^{N}(1-y_{i})x_{i}}{N-N_{1}}=\frac{\sum\limits_{i=1}^{N}(1-y_{i})x_{i}}{N_{0}} μ2^=i=1∑N(1−yi)i=1∑N(1−yi)xi=N−N1i=1∑N(1−yi)xi=N0i=1∑N(1−yi)xi
求 Σ \Sigma Σ,显然只有 ( 1 ) , ( 2 ) (1),(2) (1),(2)与 Σ \Sigma Σ相关
( 1 ) + ( 2 ) = ∑ i = 1 N y i log N ( μ 1 , Σ ) + ∑ i = 1 N ( 1 − y i ) log N ( μ 2 , Σ ) = ∑ x i ∈ C 1 log ( μ 1 , Σ ) + ∑ x i ∈ C 2 log N ( μ 2 , Σ ) ∑ i = 1 N log N ( μ , Σ ) = ∑ i = 1 N 1 ( 2 π ) p 2 ∣ Σ ∣ 1 2 exp [ − 1 2 ( x i − μ ) T Σ − 1 ( x i − μ ) ] = ∑ i = 1 N [ log 1 ( 2 π ) p 2 + log ∣ Σ ∣ 1 2 + ( − 1 2 ( x i − μ ) T Σ − 1 ( x i − μ ) ) ] = ∑ i = 1 N [ C − 1 2 log ∣ Σ ∣ − 1 2 ( x i − μ ) T Σ − 1 ( x i − μ ) ] = C − 1 2 N log ∣ Σ ∣ − 1 2 ∑ i = 1 N ( x i − μ ) T Σ − 1 ( x i − μ ) ⏟ ∈ R ∑ i = 1 N ( x i − μ ) T Σ − 1 ( x i − μ ) = ∑ i = 1 N tr [ ( x i − μ ) T Σ − 1 ( x i − μ ) ] = ∑ i = 1 N tr [ ( x i − μ ) ( x i − μ ) T Σ − 1 ] = tr [ ∑ i = 1 N ( x i − μ ) ( x i − μ ) T ⏟ x i 的方差 S Σ − 1 ] 设 S = 1 N ∑ i = 1 N ( x i − μ ) ( x i − μ ) T = N ⋅ tr ( S Σ − 1 ) 带回 ∑ i = 1 N log N ( μ , Σ ) ∑ i = 1 N log N ( μ , Σ ) = C − 1 2 N log ∣ Σ ∣ − 1 2 ∑ i = 1 N ( x i − μ ) T Σ − 1 ( x i − μ ) = − 1 2 N log ∣ Σ ∣ − 1 2 N ⋅ tr ( S ⋅ Σ − 1 ) + C 带回 ( 1 ) + ( 2 ) ( 1 ) + ( 2 ) = − 1 2 N 1 log ∣ Σ ∣ − 1 2 N ⋅ tr ( S ⋅ Σ − 1 ) − 1 2 N 2 log ∣ Σ ∣ − 1 2 N ⋅ tr ( S 2 Σ − 1 ) + C = − 1 2 N log ∣ Σ ∣ − 1 2 N ⋅ tr ( S 2 Σ − 1 ) − 1 2 N ⋅ tr ( S ⋅ Σ − 1 ) + C = − 1 2 [ N log ∣ Σ ∣ + N 1 tr ( S 1 Σ − 1 ) + N 2 tr ( S 2 Σ − 1 ) ] + C ∂ ( 1 ) + ( 2 ) ∂ Σ = − 1 2 ( N ⋅ 1 ∣ Σ ∣ ∣ Σ ∣ Σ − 1 − N 1 S 1 Σ − 1 Σ − 1 − N 2 S 2 Σ − 1 Σ − 1 ) = 0 N Σ − N 1 S 1 − N 2 S 2 = 0 Σ ^ = 1 N ( N 1 S 1 + N 2 S 2 ) \begin{aligned} (1)+(2)&=\sum\limits_{i=1}^{N}y_{i}\log N(\mu_{1},\Sigma)+\sum\limits_{i=1}^{N}(1-y_{i})\log N(\mu_{2},\Sigma)\\ &=\sum\limits_{x_{i}\in C_{1}}^{}\log(\mu_{1},\Sigma)+\sum\limits_{x_{i}\in C_{2}}^{}\log N(\mu_{2},\Sigma)\\ \sum\limits_{i=1}^{N}\log N(\mu,\Sigma)&=\sum\limits_{i=1}^{N} \frac{1}{(2\pi)^{\frac{p}{2}}|\Sigma|^{\frac{1}{2}}}\text{exp}\left[- \frac{1}{2}(x_{i}-\mu)^{T}\Sigma^{-1}(x_{i}-\mu)\right]\\ &=\sum\limits_{i=1}^{N}\left[\log \frac{1}{\left(2\pi\right)^{\frac{p}{2}}}+ \log |\Sigma|^{\frac{1}{2}}+\left(- \frac{1}{2}(x_{i}-\mu)^{T}\Sigma^{-1}(x_{i}- \mu)\right)\right]\\ &=\sum\limits_{i=1}^{N}\left[C - \frac{1}{2}\log|\Sigma|- \frac{1}{2}(x_{i}-\mu)^{T}\Sigma^{-1}(x_{i}-\mu)\right]\\ &=C- \frac{1}{2}N \log|\Sigma|- \frac{1}{2}\underbrace{\sum\limits_{i=1}^{N}(x_{i}-\mu)^{T}\Sigma^{-1}(x_{i}-\mu)}_{\in \mathbb{R}}\\ \sum\limits_{i=1}^{N}(x_{i}-\mu)^{T}\Sigma^{-1}(x_{i}-\mu)&=\sum\limits_{i=1}^{N}\text{tr }[(x_{i}-\mu)^{T}\Sigma^{-1}(x_{i}-\mu)]\\ &=\sum\limits_{i=1}^{N}\text{tr }[(x_{i}-\mu)(x_{i}-\mu)^{T}\Sigma^{-1}]\\ &=\text{tr }\left[\underbrace{\sum\limits_{i=1}^{N}(x_{i}-\mu)(x_{i}-\mu)^{T}}_{x_{i}的方差S}\Sigma^{-1}\right]\\ &设S= \frac{1}{N}\sum\limits_{i=1}^{N}(x_{i}-\mu)(x_{i}-\mu)^{T}\\ &=N \cdot \text{tr }(S \Sigma^{-1})\\ &带回\sum\limits_{i=1}^{N}\log N(\mu,\Sigma)\\ \sum\limits_{i=1}^{N}\log N(\mu,\Sigma)&=C- \frac{1}{2}N \log|\Sigma|- \frac{1}{2}\sum\limits_{i=1}^{N}(x_{i}-\mu)^{T}\Sigma^{-1}(x_{i}-\mu)\\ &=- \frac{1}{2}N \log|\Sigma|- \frac{1}{2}N \cdot \text{tr }(S \cdot \Sigma^{-1})+C\\ &带回(1)+(2)\\ (1)+(2)&=- \frac{1}{2}N_{1}\log|\Sigma|- \frac{1}{2}N \cdot \text{tr }(S \cdot \Sigma^{-1})- \frac{1}{2}N_{2}\log|\Sigma|- \frac{1}{2}N \cdot \text{tr }(S_{2}\Sigma^{-1})+C\\ &=- \frac{1}{2}N \log|\Sigma|- \frac{1}{2}N \cdot \text{tr }(S_{2}\Sigma^{-1})- \frac{1}{2}N \cdot \text{tr }(S \cdot \Sigma^{-1})+C \\ &=- \frac{1}{2}[N \log|\Sigma|+ N_{1}\text{tr }(S_{1}\Sigma^{-1})+N_{2}\text{tr }(S_{2}\Sigma^{-1})]+C\\ \frac{\partial (1)+(2)}{\partial \Sigma}&=- \frac{1}{2}(N \cdot \frac{1}{|\Sigma|}|\Sigma|\Sigma^{-1}-N_{1}S_{1}\Sigma^{-1}\Sigma^{-1}-N_{2}S_{2}\Sigma^{-1}\Sigma^{-1})=0\\ N \Sigma-N_{1}S_{1}-N_{2}S_{2}&=0\\ \hat{\Sigma}&=\frac{1}{N}(N_{1}S_{1}+N_{2}S_{2}) \end{aligned} (1)+(2)i=1∑NlogN(μ,Σ)i=1∑N(xi−μ)TΣ−1(xi−μ)i=1∑NlogN(μ,Σ)(1)+(2)∂Σ∂(1)+(2)NΣ−N1S1−N2S2Σ^=i=1∑NyilogN(μ1,Σ)+i=1∑N(1−yi)logN(μ2,Σ)=xi∈C1∑log(μ1,Σ)+xi∈C2∑logN(μ2,Σ)=i=1∑N(2π)2p∣Σ∣211exp[−21(xi−μ)TΣ−1(xi−μ)]=i=1∑N[log(2π)2p1+log∣Σ∣21+(−21(xi−μ)TΣ−1(xi−μ))]=i=1∑N[C−21log∣Σ∣−21(xi−μ)TΣ−1(xi−μ)]=C−21Nlog∣Σ∣−21∈R i=1∑N(xi−μ)TΣ−1(xi−μ)=i=1∑Ntr [(xi−μ)TΣ−1(xi−μ)]=i=1∑Ntr [(xi−μ)(xi−μ)TΣ−1]=tr ⎣ ⎡xi的方差S i=1∑N(xi−μ)(xi−μ)TΣ−1⎦ ⎤设S=N1i=1∑N(xi−μ)(xi−μ)T=N⋅tr (SΣ−1)带回i=1∑NlogN(μ,Σ)=C−21Nlog∣Σ∣−21i=1∑N(xi−μ)TΣ−1(xi−μ)=−21Nlog∣Σ∣−21N⋅tr (S⋅Σ−1)+C带回(1)+(2)=−21N1log∣Σ∣−21N⋅tr (S⋅Σ−1)−21N2log∣Σ∣−21N⋅tr (S2Σ−1)+C=−21Nlog∣Σ∣−21N⋅tr (S2Σ−1)−21N⋅tr (S⋅Σ−1)+C=−21[Nlog∣Σ∣+N1tr (S1Σ−1)+N2tr (S2Σ−1)]+C=−21(N⋅∣Σ∣1∣Σ∣Σ−1−N1S1Σ−1Σ−1−N2S2Σ−1Σ−1)=0=0=N1(N1S1+N2S2)
迹的性质
tr ( A B ) = tr ( B A ) tr ( A B C ) = tr ( C A B ) = tr ( B C A ) \begin{aligned} \text{tr }(AB)&=\text{tr }(BA)\\\text{tr }(ABC)&=\text{tr }(CAB)=\text{tr }(BCA)\end{aligned} tr (AB)tr (ABC)=tr (BA)=tr (CAB)=tr (BCA)
矩阵求导
∂ tr ( A B ) ∂ A = B − 1 ∂ ∣ A ∣ ∂ A = ∣ A ∣ ⋅ A T \begin{aligned} \frac{\partial \text{tr }(AB)}{\partial A}&=B^{-1}\\\frac{\partial |A|}{\partial A}&=|A|\cdot A^{T}\end{aligned} ∂A∂tr (AB)∂A∂∣A∣=B−1=∣A∣⋅AT
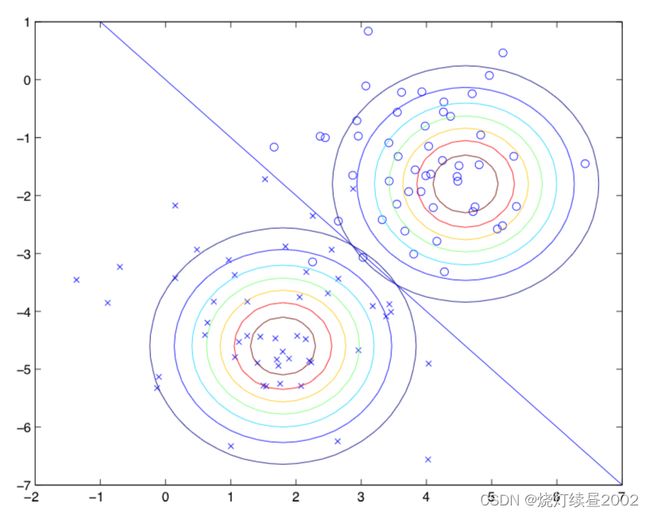
图中圆圈代表正样本,叉号代表负样本,直线p(y = 1|x) = 0.5代表分类边界(decision boundary)。因为Σ相同所以两个形状相同,但是具有不同的μ 。
作者:张文翔
链接:Andrew Ng Stanford机器学习公开课 总结(5) - 张文翔的博客 | BY ZhangWenxiang (demmon-tju.github.io)