深度学习——性别识别
第一次写博客,与大家分享刚刚学习的性别识别(不是图像)。
根据一个人的身高,体重,性别,判断性别
1.背景
神经网络具有预测,拟合,分类的作用
神经网络就是把一堆神经元连接在一起。
2.目标
通过原始数据集性别,体重与体重的对应,实验神经网络的训练。并最终完成输入体重和身高的数据,预测性别。
3.数据集
sex_train.txt 和 sex_val.txt
4.算法结构模型。神经网络。
隐藏层是夹在输入输入层和输出层之间的部分,一个神经网络可以有多个隐藏层。
把神经元的输入向前传递获得输出的过程称为前馈(feedforward)。
我们已经学会了如何搭建神经网络,现在我们来学习如何训练它,其实这就是一个优化的过程。
在训练神经网络之前,我们需要有一个标准定义它到底好不好,以便我们进行改进,这就是损失(loss)。
顾名思义,均方误差就是所有数据方差的平均值,我们不妨就把它定义为损失函数。预测结果越好,损失就越低,训练神经网络就是将损失最小化。
比如用均方误差(MSE)来定义损失:
5.安装pytorch
首先确保进入虚拟环境,输入命令:pip install torch torchvision
需要用到sex_train.txt 和 sex_val.txt,这两个文件在群里有共享python_competition.zip里,把他们放在你的代码相同目录下。该文件的格式是每行三个数,分别表示一个人的身高、体重、性别,其中性别1表示男,0表示女。
在PyCharm里新建工程,然后创建源文件(py文件),参考代码如下:
要特别注意在PyCharm里需要设置正确的解释器。菜单-File-Settings,打开如下图。假设你在任务一里的虚拟环境是d:\Anaconda3\envs\py38,则应把解释器设置为d:\Anaconda3\envs\py38\python.exe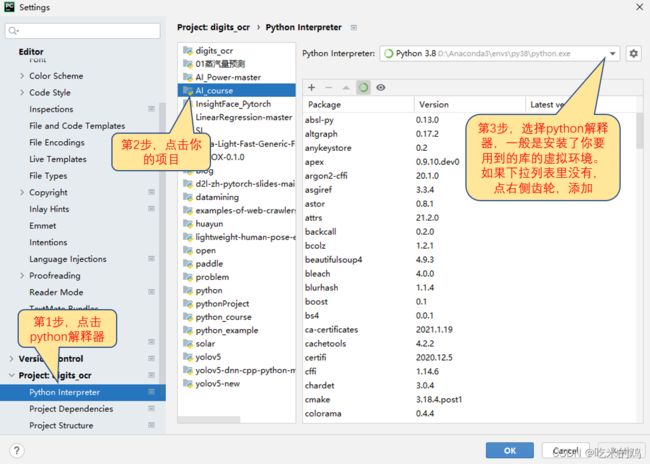
import torch
import math
import torch.nn as nn
from torch.autograd import Variable
from torchvision import transforms, models
import argparse
import os
from torch.utils.data import DataLoader
from torch.utils.data import Dataset
import random
class sexnet(nn.Module):
def __init__(self):
super(sexnet, self).__init__()
self.dense = nn.Sequential(
nn.Linear(2, 2),
)
def forward(self, x):
out = self.dense(x)
return out
class SexDataset(Dataset):
def __init__(self, txt, transform=None, target_transform=None):
fh = open(txt, 'r')
data = []
for line in fh:
line = line.strip('\n')
line = line.rstrip()
words = line.split()
data.append((float(words[0]) / 2.0, float(words[1]) / 80.0, int(words[2])))
random.shuffle(data)
self.data = data
def __getitem__(self, index):
return torch.FloatTensor([self.data[index][0], self.data[index][1]]), self.data[index][2]
def __len__(self):
return len(self.data)
def train():
os.makedirs('./output', exist_ok=True)
batchsize = 10
train_data = SexDataset(txt='sex_train.txt')
val_data = SexDataset(txt='sex_val.txt')
train_loader = DataLoader(dataset=train_data, batch_size=batchsize, shuffle=True)
val_loader = DataLoader(dataset=val_data, batch_size=batchsize)
model = sexnet()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=1e-3)
scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer, [10, 20], 0.1)
loss_func = nn.CrossEntropyLoss()
epochs = 100
for epoch in range(epochs):
# training-----------------------------------
model.train()
train_loss = 0
train_acc = 0
for batch, (batch_x, batch_y) in enumerate(train_loader):
batch_x, batch_y = Variable(batch_x), Variable(batch_y)
out = model(batch_x)
loss = loss_func(out, batch_y)
train_loss += loss.item()
pred = torch.max(out, 1)[1]
train_correct = (pred == batch_y).sum()
train_acc += train_correct.item()
print('epoch: %2d/%d batch %3d/%d Train Loss: %.3f, Acc: %.3f'
% (epoch + 1, epochs, batch, math.ceil(len(train_data) / batchsize),
loss.item(), train_correct.item() / len(batch_x)))
optimizer.zero_grad()
loss.backward()
optimizer.step()
scheduler.step() # 更新learning rate
print('Train Loss: %.6f, Acc: %.3f' % (train_loss / (math.ceil(len(train_data) / batchsize)),
train_acc / (len(train_data))))
# evaluation--------------------------------
model.eval()
eval_loss = 0
eval_acc = 0
for batch_x, batch_y in val_loader:
batch_x, batch_y = Variable(batch_x), Variable(batch_y)
out = model(batch_x)
loss = loss_func(out, batch_y)
eval_loss += loss.item()
pred = torch.max(out, 1)[1]
num_correct = (pred == batch_y).sum()
eval_acc += num_correct.item()
print('Val Loss: %.6f, Acc: %.3f' % (eval_loss / (math.ceil(len(val_data) / batchsize)),
eval_acc / (len(val_data))))
# save model --------------------------------
if (epoch + 1) % 1 == 0:
torch.save(model.state_dict(), 'output/params_' + str(epoch + 1) + '.pth')
if __name__ == '__main__':
train()
print('finished')
运行成功。
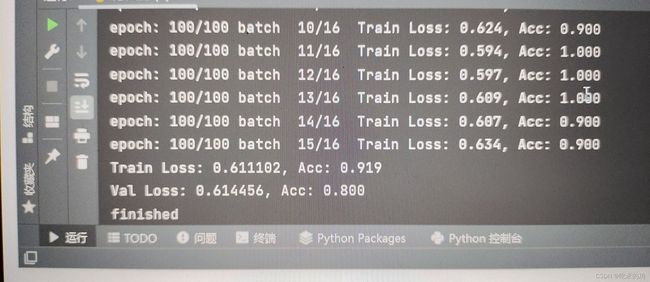
pythonProject 2022-01-09 20-51-06
下次见test代码和过程