MIT警示“深度学习过度依赖算力”,研究三年算法不如用10倍GPU
2020-07-17 01:25:51

作者 | 蒋宝尚、青暮
编辑 | 丛 末
目前深度学习的繁荣过度依赖算力的提升,在后摩尔定律时代可能遭遇发展瓶颈,在算法改进上还需多多努力。
根据外媒Venturebeat报道,麻省理工学院联合安德伍德国际学院和巴西利亚大学的研究人员进行了一项“深度学习算力”的研究。
在研究中,为了了解深度学习性能与计算之间的联系,研究人员分析了Arxiv以及其他包含基准测试来源的1058篇论文。论文领域包括图像分类、目标检测、问答、命名实体识别和机器翻译等。
得出的结论是:训练模型的进步取决于算力的大幅提高,具体来说,计算能力提高10倍相当于三年的算法改进。
而这算力提高的背后,其实现目标所隐含的计算需求——硬件、环境和金钱成本将无法承受。
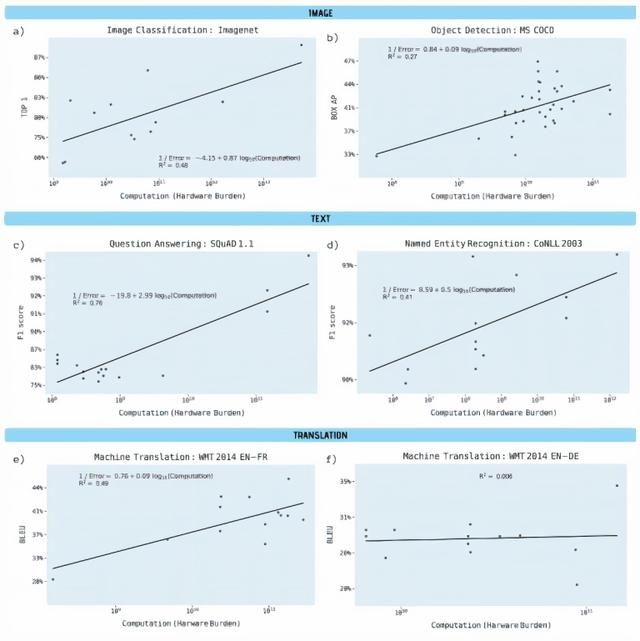
图注:模型指标的线性增长和计算代价的指数增长相关。
1
为什么说“深度学习过度依赖算力”?
他们得出这个结论的根据,是在1058篇论文中所统计的两个信息:
1、在给定的深度学习模型中,单次传播(即权重调整)所需的浮点操作数。
2、硬件负担,或用于训练模型的硬件的计算能力,计算方式为处理器数量乘以计算速率和时间。(研究人员承认,尽管这是一种不精确的计算方法,但在他们分析的论文中,对这种计算方式的报告比其他基准要广泛。)
为了更清楚的说明“单次传播所需的浮点操作数”和“硬件负担”这两个指标,作者在合著的研究报告中,举了ImageNet的例子。
作者说,通过分析这些论文,目标检测、命名实体识别和机器翻译尤其显示出硬件负担的大幅增加,而结果的改善却相对较小。在流行的开源ImageNet基准测试中,计算能力贡献了图像分类准确率的43%。
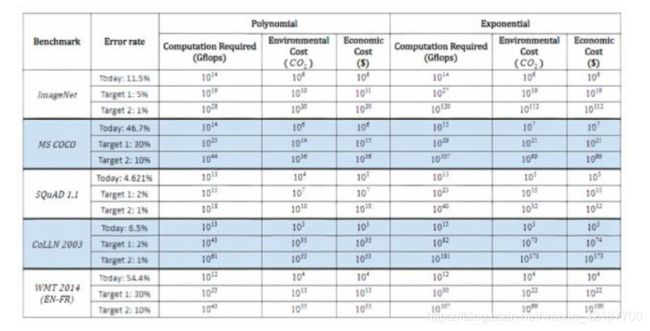
另外,即使是最乐观的计算,要降低ImageNet上的图像分类错误率,也需要进行10^5次以上的计算。
深度学习需要的硬件负担和计算次数自然涉及巨额资金花费。据Synced的一篇报告估计,华盛顿大学的Grover假新闻检测模型在大约两周的时间内训练费用为25,000美元。OpenAI花费了高达1200万美元来训练其GPT-3语言模型,而Google估计花费了6912美元来训练BERT,这是一种双向Transformer模型,重新定义了11种自然语言处理任务的SOTA。
在去年6月的马萨诸塞州大学阿默斯特分校的另一份报告中指出,训练和搜索某种模型所需的电量涉及大约626,000磅的二氧化碳排放量。这相当于美国普通汽车使用寿命内将近五倍的排放量。
当然,研究人员也同时指出,在算法水平上进行深度学习改进已经成为提升算力性能的重要方向。他们提到了硬件加速器,例如Google的TPU、FPGA和ASIC,以及通过网络压缩和加速技术来降低计算复杂性的尝试。他们还提到了神经架构搜索和元学习,这些方法使用优化来搜索在某一类问题上具有良好性能的架构。
OpenAI的一项研究表明,自2012年以来,将AI模型训练到ImageNet图像分类中相同性能所需的计算量每16个月减少一半。Google的Transformer架构超越了seq2seq,在seq2seq推出三年后,计算量减少了61倍。DeepMind的AlphaZero可以从头开始学习如何掌握国际象棋、将棋和围棋游戏,与一年前该系统的前身AlphaGoZero相比,其计算量减少了八倍。
计算能力的爆发结束了“AI的冬天”,并为各种任务的计算性能树立了新的基准。但是,深度学习对计算能力的巨大需求限制了它改善性能的程度,特别是在硬件性能改善的步伐变得缓慢的时代。研究人员说:“这些计算限制的可能影响迫使机器学习转向比深度学习更高效的技术。”
2
深度学习会被算力锁死么?顶层设计仍有希望
论文地址:https://science.sciencemag.org/content/368/6495/eaam9744
关于深度学习是否达到了计算能力上限这件事情,之前就有过讨论,例如MIT、英伟达、微软研究者合著的一篇 Science 论文便从软件、算法、硬件架构三个维度分析了算力的发展趋势。
在Science这篇论文中,作者给过去算力的提升归纳了两个原因:一个是“底部”的发展,即计算机部件的小型化,其受摩尔定律制约;另一个是“顶部”的发展,是上面提到的软件、算法、硬件架构的统称。
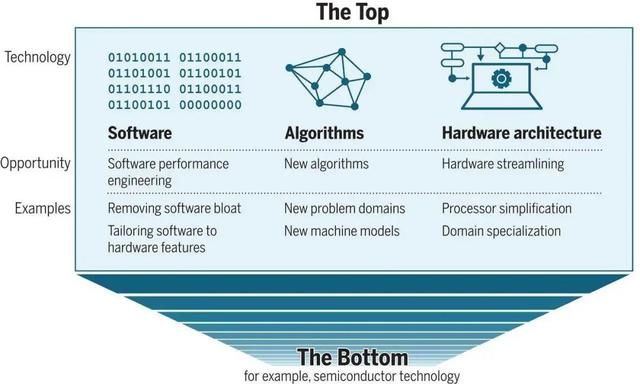
在文章中,作者提到,在后摩尔定律时代,提升计算性能的方法,虽然“底部”已经没有太多提升的空间,但“顶部”还有机会。
在软件层面,可以通过性能工程(performance engineering)提高软件的效率,改变传统软件的开发策略,尽可能缩短软件运行时间,而不是缩短软件开发时间。另外,性能工程还可以根据硬件的情况进行软件定制,如利用并行处理器和矢量单元。
在算法层面,在已有算法上的改进是不均匀的,而且具有偶然性,大量算法进展可能来源于新的问题领域、可扩展性问题、根据硬件定制算法。
另外,在今年的5月份,OpenAI针对AI算法在过去数年中性能的提升做了一个详细的分析。他们发现,自2012年以来,在 ImageNet 分类上训练具有相同性能的神经网络,所需要的计算量,每16个月降低一半。与2012年相比,现在将神经网络训练到 AlexNet 的性能,所需的计算量仅为原来的1/44(相比之下,摩尔定律仅降低为1/11)。
显然,算法上的进步相比服从摩尔定理的硬件的进步,能产生更多的效益。
在硬件层面,由于摩尔定律的制约,显然需要改进的是硬件的架构,主要问题就是如何简化处理器和利用应用程序的并行性。通过简化处理器,可以将复杂的处理核替换为晶体管数量需求更少的简单处理核。由此释放出的晶体管预算可重新分配到其他用途上,比如增加并行运行的处理核的数量,这将大幅提升可利用并行性问题的效率。
简化的另一种形式是领域专门化(domain specialization),即针对特定应用程序定制硬件。这种专门化允许考虑领域的特点,自定义简化硬件结构,具有极强的针对性。
Via https://venturebeat.com/2020/07/15/mit-researchers-warn-that-deep-learning-is-approaching-computational-limits/