大数据量query,QP意图理解搜索引擎算法测试
搜索引擎质量指标(nDCG) 参考博客https://blog.csdn.net/LintaoD/article/details/82661206
特征feature:相关性 时效性 质量 点击率 权威度 冷启动
搜索/推荐业务哪一些场景要放到缓存
搜索:特征
大页cache和小页cache 实现区别
小页缓存是为了提高进入搜索结果页的加载速度,是渐进加载或者叫预加载,将原来的1页内容分两页返回,第一页请求回30个,分为两页返回,第一页返回10个,第二页返回20个。
大页缓存是对一次完整的请求结果,只不过不是像原来的请求一页30个,现在第一次请求会70多个结果,最开始是一下请求回5页共150个结果
推荐:分user和item,是单独存的。然后user又分为很多个feature
需求1:给一批query,保证每个query下都返回卡片A的a字段(数据脱敏)
需求2:给上万个keyword校验每个keyword算法接口下召回A且B或A或B或AB都没有的比率
需求3:意图理解测试(要求手动测试,标注,但可以用脚本实现)。给一批新的词表,纠错类的一共70。其他的一共700,头部一共有400,腰部200,尾部100。乱序排的,哪层都有。

意图接口测试:类目预测、纠错、改写、qt(query tagging分词)。qp的当前线上结果也会出现badcase,所以需要人工审核下数据
对于超时无结果的可以查接口补充数据,如下:
改写的结果 :
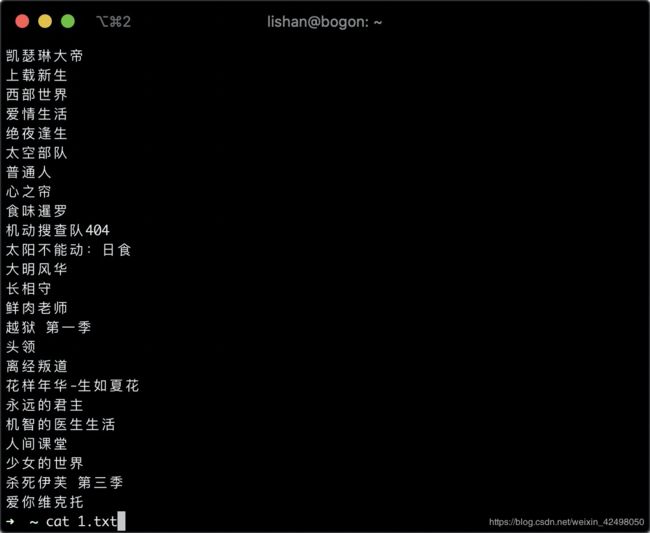
设计:query准备,PM提供的Excel格式,转换为txt格式,但是没有,
shell脚本处理
把文件1.txt的内容在每行结尾添加,写到2.txt
➜ ~ sed 's/$/&,/g' 1.txt > 2.txt
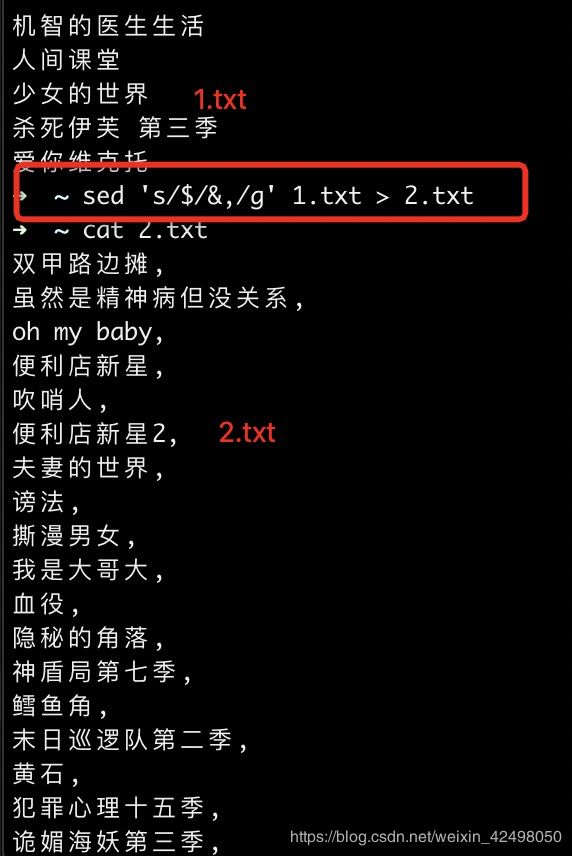
[文本处理] 多列合并一行的SHELL,以,隔开
➜ ~ awk '{a=a?a","$1:$1;b=b?b","$2:$2}END{print a,b}' 1.txt

脚本部分-线上环境:
业务需求1:logOnlineReadFiles70-纠错
接口取值--多层nodes下取需求字段
QP算法接口返回的数据:qc(纠错词) qaGrade(纠错词级别) keyword(原始query)
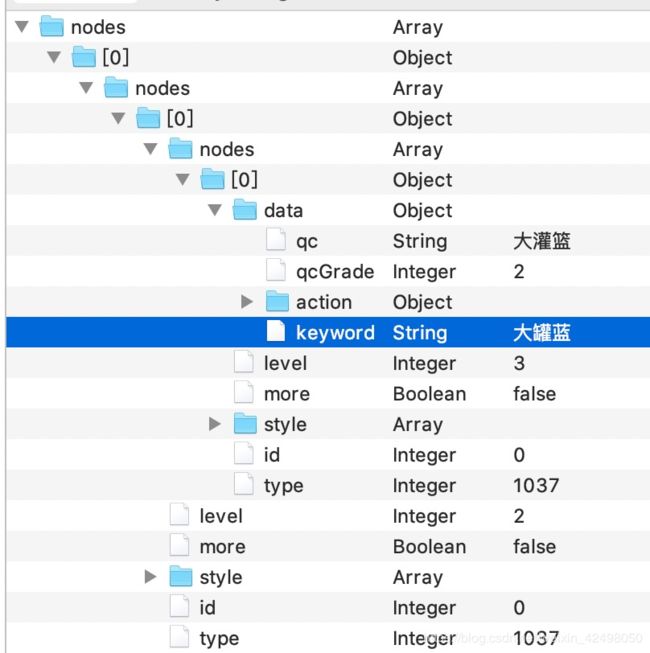
业务接口:取第二个卡片的类型-标题 docSource-object_title,因为第1个(index=0)的nodes为纠错词,第二个(index=1)为业务卡片
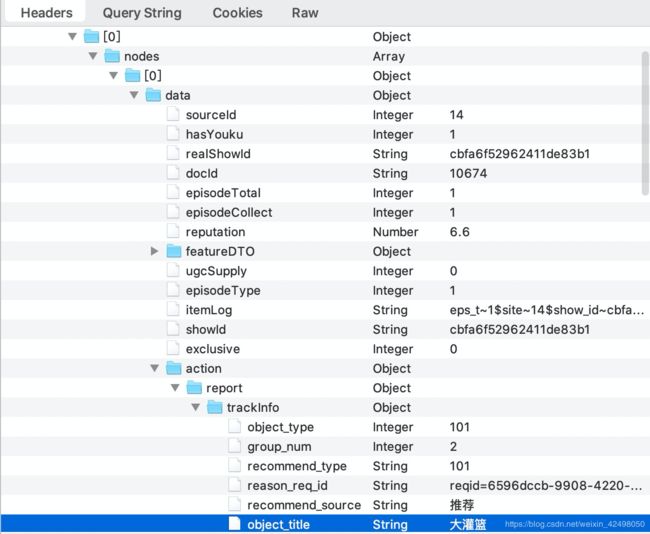
业务需求2:logOnlineReadFiles700-改写
logOnlineReadFilesQP-类目预测category,打分level,分词数组query tagging
业务接口:取第一个卡片的类型-标题 docSource-object_title,因为无纠错词,第一个(index=0)为业务卡片
算法接口:取打分、分词、改写、纠错、类型标注
特殊字段查找,CR代码:
/**
* 纠错词级别:1提示,2替换查询
*/
private int qcGrade;
框架设计:取算法接口和业务接口同时判断
基于httpclient框架,以及对文件解析处理,按照需求设计需要的列,如ABC列分别abc三个文件。CD两列写入c文件
整体设计:shell解析Excel文件内容,读取txt文件,query分类(3类),3类接口结果按需求要求写入文本,每次运行程序前删除txt文件,新数据可每次写入
代码如下:
1. 70个纠错词query-业务代码实现
package com.alibaba.searchQP.utils;
import com.alibaba.fastjson.JSONObject;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.*;
import static com.alibaba.searchQP.utils.ReadFiles.readTxt;
/**
* Excel文本处理:query粘贴放到1.txt文件,执行awk '{a=a?a","$1:$1;b=b?b","$2:$2}END{print a,b}' 1.txt
* 处理70个纠错词query,Excel原始query取纠错词以及取第一个卡片类型-标题
*/
public class logOnlineReadFiles70 {
private static Logger logger = LoggerFactory.getLogger(logOnlineReadFiles700.class);
public static void main(String[] args) {
// 运行程序(读取新的log文件)之前,清空旧文件(上次的log日志信息)
FileWrite.deleteAllLogFile();
FileWrite.deleteAllLogCopyFile();
startSearch();
}
// 定义集合,把搜索场景放到list集合
public static List list = new ArrayList<>();
public static void startSearch() {
long startTime = System.currentTimeMillis();
System.out.println("===程序开始执行===");
// 拼接的传参参数为中文,需要把中文放到map
// 方法1:把待测试的query top排行前1000在odps查询出,存到本地,再通过接口拼接
String filePath = "/Users/lishan/Desktop/code/xx/qp.txt";
System.out.println(filePath);
String[] keywords = readTxt(filePath);
// System.out.println("strings:" + Arrays.toString(keywords));
// String keywords=record.getString("f1");
// 方法2:代码读取odps工具类,查询top1000的query,再通过接口拼接
// 见logOnlineReadODPS
// String[] keywords={"吴亦凡","杨幂","唐嫣"};
// String[] keywords = {"吴亦凡"};
int only1 = 0;
String query1 = "";
int totalCount = 0;
try {
for (int i = 0; i < keywords.length; i++) {
Map query = new HashMap<>();
query.put("keyword", keywords[i]);
// 如果URL没有公共参数,则把 ?去掉;
// 业务接口传参增加cmd=4拿到引擎字段返回
String url_pre = "http://xx";
// 开始请求,域名、接口名==url+请求参数param(hashMap)
// String response = HTTPCommonMethod.doGet(url_pre, url_online, map, count);
System.out.println("第" + (i + 1) + "条数据==" + query);
String response = HTTPCommonMethod.doGet(url_pre, query, i);
JSONObject responseJson = JSONObject.parseObject(response);
int type = responseToParse(i, keywords[i], responseJson);
// 仅节目卡
if (type == 1) {
only1++;
query1 = query1 + keywords[i] + ",";
// 仅系列卡
}
// 打印接口返回的数据
// System.out.println("第【" + i + "】条日志,预发环境pre接口返回response为=======" + response);
totalCount = i + 1;
// System.out.println("每次循环的totalCount=="+totalCount);
}
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("totalCount==" + totalCount);
float rate3 = (float) only1 / (float) totalCount;
System.out.println("------------------------------------------------------------------------------------------------");
System.out.println("------------------------------------------------------------------------------------------------");
System.out.println("only1---召回纠错词卡==【" + only1 + "】个,总数" + totalCount + "个,---比率为==【" + rate3 + "】---query1==【" + query1 + "】");
long endTime = System.currentTimeMillis();
System.out.println("===程序结束执行===");
long durationTime = endTime - startTime;
System.out.println("===程序耗时===【" + durationTime + "】毫秒");
// System.out.println("===程序耗时===【" + durationTime / 1000 / 60 + "】分钟");
}
/**
* @param count
* @param query
* @param response
* @return 1:返回纠错词卡片 2: 未返回
*/
public static int responseToParse(int count, String query, JSONObject response) {
try {
// HashMap hm = new HashMap();
boolean qpResult = false;
if (!response.isEmpty()) {
// 获取JSONObject
// 意图理解算法接口:是否纠错qcGrade。纠错词级别:1提示,2替换查询
// 业务接口:取第一个纠错词结果的卡片标题和卡片类型
// QP接口
JSONObject data0 = response.getJSONArray("nodes").getJSONObject(0).
getJSONArray("nodes").getJSONObject(0).
getJSONArray("nodes").getJSONObject(0).
getJSONObject("data");
// 纠错词类型
Integer qcGrade = data0.getInteger("qcGrade");
// qc为纠错词,如keyword=新白胖子传奇,qc=新白娘子传奇
String qc = data0.getString("qc");
// keyword为原始query(用户输入),如keyword=新白胖子传奇
String keyword = data0.getString("keyword");
// 业务接口
JSONObject data1 = response.getJSONArray("nodes").getJSONObject(1).
getJSONArray("nodes").getJSONObject(0).
getJSONArray("nodes").getJSONObject(0).
getJSONObject("data");
String object_title = data1.getJSONObject("action").getJSONObject("report").
getJSONObject("trackInfo").getString("object_title");
Integer docSource = data1.getInteger("docSource");
// QP算法接口和业务接口同时满足时
if (qcGrade == 2 && (!qc.equals(keyword))) {
if (!object_title.isEmpty() && docSource != 0) {
System.out.println("第【" + (count + 1) + "】条日志,搜索query为==【" + query + "】,纠错词qc为==【" + qc + "】," +
"docSource==【" + docSource + "】,第一个卡片标题==【" + object_title + "】");
// 用于写入正常日志文件originLog,再做字段拆分,从而写入数据库,记录读取的log日志
// 全部数据
// FileWrite.originLog(FileWrite.rex + query + FileWrite.rex + qc + FileWrite.rex + docSource + "-" + object_title);
// 单个字段写入-原始query 纠错词qc 类型-第一个卡片的主标题
FileWrite.keywordLog(query);
FileWrite.qcLog(qc);
FileWrite.videoTitleLog(docSource + "-" + object_title);
qpResult = true;
} else {
System.err.println("BUG!BUG!BUG!QP接口识别错误,未纠错!!!第【" + (count + 1) + "】条日志," +
"搜索query为==【" + query + "】,纠错词qc为==【" + qc + "】," +
"docSource==【" + docSource + "】,第一个卡片标题==【" + object_title + "】");
}
}
if (qpResult) {
// 是纠错词卡片
return 1;
//
} else {
return 0;
}
} else {
System.err.println("第【" + count + "】条日志,搜索query为==【" + query + "】,接口返回为空");
}
} catch (Exception e) {
e.printStackTrace();
}
return 2;
}
public static JSONObject jsonObject = new JSONObject();
} 700个query类目预测-业务代码实现
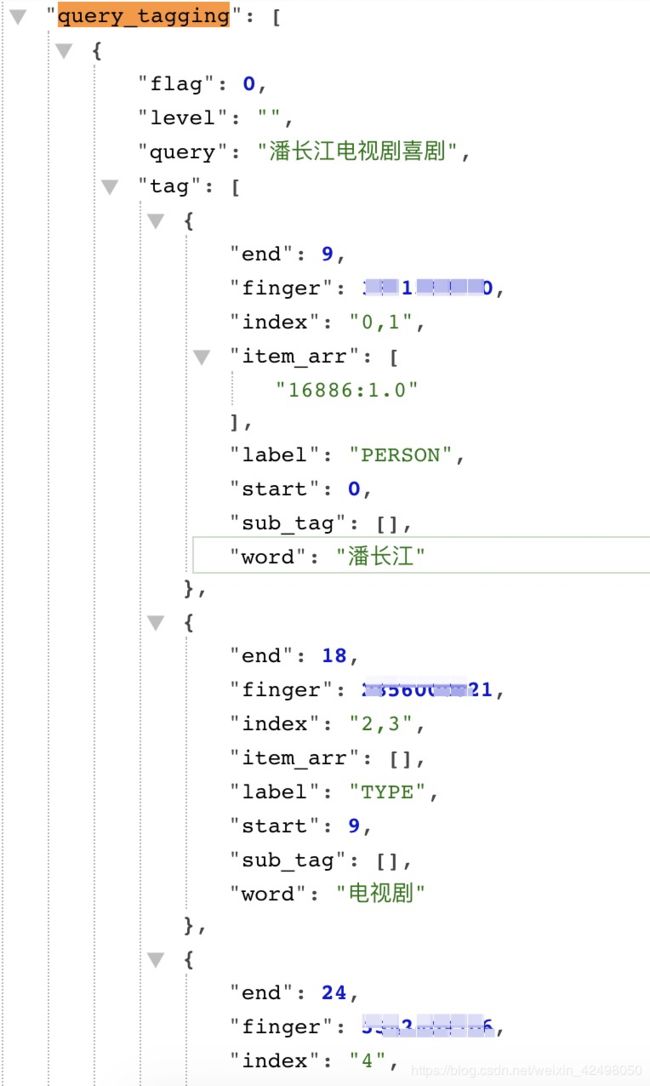
算法接口-分词,对应query_tagging.tag.word
package com.alibaba.searchQP.utils;
import com.alibaba.fastjson.JSONObject;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.*;
import static com.alibaba.searchQP.utils.ReadFiles.readTxt;
/**
* Excel文本处理:query粘贴放到1.txt文件,执行awk '{a=a?a","$1:$1;b=b?b","$2:$2}END{print a,b}' 1.txt
* 处理700个query,纠错、类目预测 、改写、qt(query tagging分词),Excel原始query取第一个卡片类型-标题
* 人物卡-12 scg播单-98 banner(大图推广)-24 节目大词-10 等返回的json格式略微不同,时间原因,暂未开发对此类query的支持。所以这部分数据抓取结果为空,可以手动移动下
* 跑700个query 直接用此脚本运行
*/
public class logOnlineReadFiles700 {
private static Logger logger = LoggerFactory.getLogger(logOnlineReadFiles700.class);
public static void main(String[] args) {
// 运行程序(读取新的log文件)之前,清空旧文件(上次的log日志信息)
FileWrite.deleteAllLogFile();
FileWrite.deleteAllLogCopyFile();
startSearch();
}
// 定义集合,把搜索场景放到list集合
public static List list = new ArrayList<>();
public static void startSearch() {
long startTime = System.currentTimeMillis();
System.out.println("===程序开始执行===");
// 拼接的传参参数为中文,需要把中文放到map
// 方法1:把待测试的query top排行前1000在odps查询出,存到本地,再通过接口拼接
String filePath = "/Users/lishan/Desktop/code/xx/qp.txt";
System.out.println(filePath);
String[] keywords = readTxt(filePath);
// System.out.println("strings:" + Arrays.toString(keywords));
// String keywords=record.getString("f1");
// 方法2:代码读取odps工具类,查询top1000的query,再通过接口拼接
// 见logOnlineReadODPS
// String[] keywords={"吴亦凡","杨幂","唐嫣"};
// String[] keywords = {"吴亦凡"};
int only1 = 0;
String query1 = "";
int totalCount = 0;
try {
for (int i = 0; i < keywords.length; i++) {
Map query = new HashMap<>();
query.put("keyword", keywords[i]);
// 如果URL没有公共参数,则把 ?去掉;
// 业务接口传参增加cmd=4拿到引擎字段返回
String url_pre = "http://xx";
// 开始请求,域名、接口名==url+请求参数param(hashMap)
// String response = HTTPCommonMethod.doGet(url_pre, url_online, map, count);
System.out.println("第" + (i + 1) + "条数据==" + query);
String response = HTTPCommonMethod.doGet(url_pre, query, i);
JSONObject responseJson = JSONObject.parseObject(response);
int type = responseToParse(i, keywords[i], responseJson);
// 仅节目卡
if (type == 1) {
only1++;
query1 = query1 + keywords[i] + ",";
// 仅系列卡
}
// 打印接口返回的数据
// System.out.println("第【" + i + "】条日志,预发环境pre接口返回response为=======" + response);
totalCount = i + 1;
// System.out.println("每次循环的totalCount=="+totalCount);
}
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("totalCount==" + totalCount);
float rate3 = (float) only1 / (float) totalCount;
System.out.println("------------------------------------------------------------------------------------------------");
System.out.println("------------------------------------------------------------------------------------------------");
System.out.println("only1---召回纠错词卡==【" + only1 + "】个,总数" + totalCount + "个,---比率为==【" + rate3 + "】---query1==【" + query1 + "】");
long endTime = System.currentTimeMillis();
System.out.println("===程序结束执行===");
long durationTime = endTime - startTime;
System.out.println("===程序耗时===【" + durationTime + "】毫秒");
// System.out.println("===程序耗时===【" + durationTime / 1000 / 60 + "】分钟");
}
/**
* @param count
* @param query
* @param response
* @return 1:获取第一个卡片的类型-标题 2: 未返回
*/
public static int responseToParse(int count, String query, JSONObject response) {
try {
// HashMap hm = new HashMap();
boolean qpResult = false;
if (!response.isEmpty()) {
// 获取JSONObject
// 意图理解算法接口:是否纠错qcGrade。纠错词级别:1提示,2替换查询
// 业务接口:取第一个纠错词结果的卡片标题和卡片类型
// QP接口
JSONObject data0 = response.getJSONArray("nodes").getJSONObject(0).
getJSONArray("nodes").getJSONObject(0).
getJSONArray("nodes").getJSONObject(0).
getJSONObject("data");
// 业务接口
String object_title = data0.getJSONObject("action").getJSONObject("report").
getJSONObject("trackInfo").getString("object_title");
Integer docSource = data0.getInteger("docSource");
if (!object_title.isEmpty()) {
if (docSource == null) {
System.err.println("第【" + (count + 1) + "】条日志,原始keyword为==【" + query + "】," +
"docSource==【null】,第一个卡片标题object_title==【" + object_title + "】");
FileWrite.keywordLog(query);
FileWrite.videoTitleLog("null-" + object_title);
qpResult = true;
return 3;
}
if (docSource > 0) {
System.out.println("第【" + (count + 1) + "】条日志,原始keyword为==【" + query + "】," +
"docSource==【" + docSource + "】,第一个卡片标题object_title==【" + object_title + "】");
// 用于写入正常日志文件originLog,再做字段拆分,从而写入数据库,记录读取的log日志
// 全部数据
// FileWrite.originLog(FileWrite.rex + query + FileWrite.rex + qc + FileWrite.rex + docSource + "-" + object_title);
// 单个字段写入-原始query 纠错词qc 类型-第一个卡片的主标题
FileWrite.keywordLog(query);
FileWrite.videoTitleLog(docSource + "-" + object_title);
qpResult = true;
} else if (docSource <= 0) {
System.err.println("BUG!BUG!BUG!业务接口docSource枚举值错误!!!第【" + (count + 1) + "】条日志," +
"原始keyword为==【" + query + "】," +
"docSource==【" + docSource + "】,第一个卡片标题object_title==【" + object_title + "】");
}
// }
} else if (object_title == null) {
System.err.println("第【" + (count + 1) + "】条日志,原始keyword为==【" + query + "】," +
"docSource==【" + docSource + "】,第一个卡片标题object_title==【null】");
// 单个字段写入-原始query 纠错词qc 类型-第一个卡片的主标题
FileWrite.keywordLog(query);
FileWrite.videoTitleLog(docSource + "-null");
// System.err.println("第【" + count + "】条日志,原始keyword为==【" + query + "】,object_title为空");
qpResult = true;
return 3;
}
if (object_title == null && docSource == null) {
System.err.println("第【" + (count + 1) + "】条日志,原始keyword为==【" + query + "】," +
"docSource==【null】,第一个卡片标题object_title==【null】");
// 单个字段写入-原始query 纠错词qc 类型-第一个卡片的主标题
FileWrite.keywordLog(query);
FileWrite.videoTitleLog("null-null");
qpResult = true;
return 3;
}
if (qpResult) {
// 是纠错词卡片
return 1;
//
} else {
return 0;
}
} else {
System.err.println("第【" + count + "】条日志,原始keyword为==【" + query + "】,接口返回为空");
}
} catch (Exception e) {
e.printStackTrace();
}
return 2;
}
public static JSONObject jsonObject = new JSONObject();
} 2. 基于httpclient框架,解析请求
package com.alibaba.searchQP.utils;
import org.apache.commons.httpclient.Header;
import org.apache.commons.httpclient.HttpClient;
import org.apache.commons.httpclient.NameValuePair;
import org.apache.commons.httpclient.methods.GetMethod;
import org.apache.commons.httpclient.util.EncodingUtil;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
public class HTTPCommonMethod {
/**
* get 请求,只需将变动的参数传入params中即可
*
* @param url_pre
* @param params
* @return
*/
public static String requestURL;
public static String doGet(String url_pre, Map params, int count) {
try {
Header header = new Header("Content-type", "application/json");
String response = "";
// HttpClient是Apache Jakarta Common下的子项目,用来提供高效的、最新的、功能丰富的支持HTTP协议的客户端编程工具包,并且它支持HTTP协议最新的版本和建议。
// HttpClient已经应用在很多的项目中,比如Apache Jakarta上很著名的另外两个开源项目Cactus和HTMLUnit都使用了HttpClient。
// 使用HttpClient发送请求、接收响应
HttpClient httpClient = new HttpClient();
if (url_pre != null) {
// NameValuePair是简单名称值对节点类型。多用于Java像url_pre发送Post请求。在发送post请求时用该list来存放参数
// getParamsList(url_online, params, count);
// 预发环境value替换线上环境value
List qparams_pre = getParamsList_pre(params);
if (qparams_pre != null && qparams_pre.size() > 0) {
String formatParams = EncodingUtil.formUrlEncode(qparams_pre.toArray(new NameValuePair[qparams_pre.size()]),
"utf-8");
url_pre = url_pre.indexOf("?") < 0 ? url_pre + "?" + formatParams : url_pre + "&" + formatParams;
}
requestURL = url_pre;
System.out.println("第【" + (count+1) + "】条日志,预发环境pre imerge请求的url_pre==" + url_pre);
GetMethod getMethod = new GetMethod(url_pre);
getMethod.addRequestHeader(header);
/*if (null != headers) {
Iterator var8 = headers.entrySet().iterator();
while (var8.hasNext()) {
Map.Entry entry = (Map.Entry)var8.next();
getMethod.addRequestHeader((String)entry.getKey(), (String)entry.getValue());
}
}*/
//System.out.println(getMethod.getRequestHeader("User-Agent"));
int statusCode = httpClient.executeMethod(getMethod);
// 如果请求失败则打印出失败的返回码
if (statusCode != 200) {
System.out.println("第" + statusCode + "【" + count + "】条日志,预发环境请求出错,错误码为=======" + statusCode);
return response;
}
response = new String(getMethod.getResponseBody(), "utf-8");
}
return response;
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
// 参数格式化
private static List getParamsList_pre(Map paramsMap) {
if (paramsMap != null && paramsMap.size() != 0) {
List params = new ArrayList();
Iterator var2 = paramsMap.entrySet().iterator();
while (var2.hasNext()) {
Map.Entry map = (Map.Entry) var2.next();
// 预发环境最新版本日志回放,请求参数打开以下if else,注释掉最后一行
// 参数格式化,commons-httpclient自带的方法NameValuePair会自动将==转为=,还有特殊符号格式化
// NameValuePair是简单名称值对节点类型。多用于Java像url_pre发送Post请求。在发送post请求时用该list来存放参数
params.add(new NameValuePair(map.getKey() + "", map.getValue() + ""));
// params.add(new NameValuePair(map.getKey() + "", map.getValue() + ""));
}
return params;
} else {
return null;
}
}
}
3. 文件读取解析
package com.alibaba.searchQP.utils;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStreamReader;
import java.util.Arrays;
public class ReadFiles {
public static String[] readTxt(String filePath) {
StringBuilder builder = new StringBuilder();
try {
File file = new File(filePath);
if (file.isFile() && file.exists()) {
InputStreamReader isr = new InputStreamReader(new FileInputStream(file), "utf-8");
BufferedReader br = new BufferedReader(isr);
String lineTxt = null;
int num = 0;
long time1 = System.currentTimeMillis();
while ((lineTxt = br.readLine()) != null) {
System.out.println(lineTxt);
builder.append(lineTxt);
builder.append(",");
num++;
// System.out.println("总共" + num + "条数据!");
}
//System.out.println("总共"+num+"条数据!");
long time2 = System.currentTimeMillis();
long time = time1 - time2;
// System.out.println("共花费" + time + "秒");
br.close();
} else {
System.out.println("文件不存在!");
}
} catch (Exception e) {
System.out.println("文件读取错误!");
}
String[] strings = builder.toString().split(",");
return strings;
}
public static void main(String[] args) {
String filePath = "/Users/lishan/Desktop/xx.txt";
System.out.println(filePath);
String[] strings = readTxt(filePath);
System.out.println("strings:"+Arrays.toString(strings));
}
}4. 测试结果:按Excel写入(时间原因,不支持直接插入Excel,需要手动拷贝)
召回纠错词卡==【10】个,总数10个,---比率为==【1.0】---query1==【七小英雄,因为爱情有多美吻,少主慢行,大罐蓝,三叉记,乡材爱情8,那一场呼唤而过的青春,国产电视剧赵丽颕主演的楚乔传,神战权利之眼,干物埋小妹,】
===程序结束执行===
===程序耗时===【4194】毫秒
5. 优化脚本,将控制台输出的日志写入文件。每次运行程序之前删除历史日志文件
package com.alibaba.searchQP.utils;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
public class FileWrite {
// 定义path全局路径 原始日志存放路径pathOrigin 错误日志存放路径pathError
public static String pathAll = "/Users/lishan/Desktop/xx/HistoryLog";
public static String rex = " ";
public static void main(String[] args) {
String content = "a log will be write in file";
System.out.println(content + "" + "");
originLog(content + "" + "");
errorLog(content + "" + "");
}
public static void originLog(String content) {
try {
// File.separator代表系统目录中的间隔符,说白了就是斜线 '\',不过有时候需要双线,有时候是单线,用这个静态变量就解决兼容问题了。
File file = new File(pathAll + File.separator + "origin_log.txt");
if (!file.exists()) {
file.createNewFile();
}
FileWriter fileWriter = new FileWriter(file.getAbsoluteFile(), true);
BufferedWriter bw = new BufferedWriter(fileWriter);
bw.write(content + "\r\n");
bw.close();
System.out.println("finish");
} catch (IOException e) {
e.printStackTrace();
}
}
public static void keywordLog(String content) {
try {
// File.separator代表系统目录中的间隔符,说白了就是斜线 '\',不过有时候需要双线,有时候是单线,用这个静态变量就解决兼容问题了。
File file = new File(pathAll + File.separator + "keyword_log.txt");
if (!file.exists()) {
file.createNewFile();
}
FileWriter fileWriter = new FileWriter(file.getAbsoluteFile(), true);
BufferedWriter bw = new BufferedWriter(fileWriter);
bw.write(content + "\r\n");
bw.close();
System.out.println("finish");
} catch (IOException e) {
e.printStackTrace();
}
}
public static void qcLog(String content) {
try {
// File.separator代表系统目录中的间隔符,说白了就是斜线 '\',不过有时候需要双线,有时候是单线,用这个静态变量就解决兼容问题了。
File file = new File(pathAll + File.separator + "qc_log.txt");
if (!file.exists()) {
file.createNewFile();
}
FileWriter fileWriter = new FileWriter(file.getAbsoluteFile(), true);
BufferedWriter bw = new BufferedWriter(fileWriter);
bw.write(content + "\r\n");
bw.close();
System.out.println("finish");
} catch (IOException e) {
e.printStackTrace();
}
}
public static void videoTitleLog(String content) {
try {
// File.separator代表系统目录中的间隔符,说白了就是斜线 '\',不过有时候需要双线,有时候是单线,用这个静态变量就解决兼容问题了。
File file = new File(pathAll + File.separator + "videoTitle_log.txt");
if (!file.exists()) {
file.createNewFile();
}
FileWriter fileWriter = new FileWriter(file.getAbsoluteFile(), true);
BufferedWriter bw = new BufferedWriter(fileWriter);
bw.write(content + "\r\n");
bw.close();
System.out.println("finish");
} catch (IOException e) {
e.printStackTrace();
}
}
public static void errorLog(String content) {
try {
// File.separator代表系统目录中的间隔符,说白了就是斜线 '\',不过有时候需要双线,有时候是单线,用这个静态变量就解决兼容问题了。
File file = new File(pathAll + File.separator + "error_log.txt");
if (!file.exists()) {
file.createNewFile();
}
FileWriter fileWriter = new FileWriter(file.getAbsoluteFile(), true);
BufferedWriter bw = new BufferedWriter(fileWriter);
bw.write("\r\n" + content);
bw.close();
System.out.println("finish");
} catch (IOException e) {
e.printStackTrace();
}
}
public static String getErrorLog(String currentTimeMillis, String clientTimeStamp, int count, String printMsg) {
String errorLog = "";
errorLog = currentTimeMillis + FileWrite.rex + clientTimeStamp + FileWrite.rex + count + FileWrite.rex + printMsg;
return errorLog;
}
// 错误日志写入cpw_log_error数据表,暂无clientTimeStamp的日志
public static String getErrorLogNoclientTimeStamp(String currentTimeMillis, int count, String printMsg, int errorLevel) {
String errorLogNoclientTimeStamp = "";
// errorLogNoclientTimeStamp = currentTimeMillis + FileWrite.rex + clientTimeStamp + FileWrite.rex + count + FileWrite.rex +printMsg;
errorLogNoclientTimeStamp = currentTimeMillis + FileWrite.rex + "暂无clientTimeStamp" + FileWrite.rex + count + FileWrite.rex + printMsg + FileWrite.rex + errorLevel;
return errorLogNoclientTimeStamp;
}
// 错误日志写入cpw_log_error数据表,有clientTimeStamp的日志
public static String getErrorLogHasclientTimeStamp(String currentTimeMillis, String clientTimeStamp, int count, String printMsg, int errorLevel) {
String getErrorLogHasclientTimeStamp = "";
// errorLogNoclientTimeStamp = currentTimeMillis + FileWrite.rex + clientTimeStamp + FileWrite.rex + count + FileWrite.rex +printMsg;
getErrorLogHasclientTimeStamp = currentTimeMillis + FileWrite.rex + clientTimeStamp + FileWrite.rex + count + FileWrite.rex + printMsg + FileWrite.rex + errorLevel;
return getErrorLogHasclientTimeStamp;
}
// 删除原始origin_log.txt和error_log.txt,防止日志重复写入
public static void deleteAllLogFile() {
try {
// File.separator代表系统目录中的间隔符,说白了就是斜线 '\',不过有时候需要双线,有时候是单线,用这个静态变量就解决兼容问题了。
// 删除原始keyword日志
File fileKeyword = new File(pathAll + File.separator + "keyword_log.txt");
if (fileKeyword.exists()) {
fileKeyword.delete();
}
System.out.println("原始keyword日志已删除。delete keyword_log.txt file success");
// 删除纠错词qc错误日志
File fileQc = new File(pathAll + File.separator + "qc_log.txt");
if (fileQc.exists()) {
fileQc.delete();
}
System.out.println("纠错词日志已删除。delete qc_log.txt file success");
// 删除原始keyword日志
File fileVideoTitle = new File(pathAll + File.separator + "videoTitle_log.txt");
if (fileVideoTitle.exists()) {
fileVideoTitle.delete();
}
System.out.println("第一个卡片主标题日志已删除。delete videoTitle_log.txt file success");
} catch (Exception e) {
e.printStackTrace();
}
}
// 删除原始origin_log.txt,防止接口重复请求导致日志重复写入
public static void deleteOriginLogFirstRunFile() {
try {
// File.separator代表系统目录中的间隔符,说白了就是斜线 '\',不过有时候需要双线,有时候是单线,用这个静态变量就解决兼容问题了。
// 删除原始日志
File fileOrigin = new File(pathAll + File.separator + "origin_log.txt");
if (fileOrigin.exists()) {
fileOrigin.delete();
}
System.out.println("原始日志已删除。delete origin_log.txt file success");
} catch (Exception e) {
e.printStackTrace();
}
}
// 删除原始error_log.txt,防止接口重复请求导致日志重复写入
public static void deleteErrorLogFirstRunFile() {
try {
// File.separator代表系统目录中的间隔符,说白了就是斜线 '\',不过有时候需要双线,有时候是单线,用这个静态变量就解决兼容问题了。
// 删除错误日志
File fileError = new File(pathAll + File.separator + "error_log.txt");
if (fileError.exists()) {
fileError.delete();
}
System.out.println("错误参数断言日志已删除。delete error_log.txt file success");
} catch (Exception e) {
e.printStackTrace();
}
}
// 删除副本origin_log_copy.txt和error_log_copy.txt
public static void deleteAllLogCopyFile() {
try {
// 删除原始日志副本
// File.separator代表系统目录中的间隔符,说白了就是斜线 '\',不过有时候需要双线,有时候是单线,用这个静态变量就解决兼容问题了。
File fileOrigin = new File(pathAll + File.separator + "origin_log_copy.txt");
if (fileOrigin.exists()) {
fileOrigin.delete();
}
System.out.println("原始日志副本已删除。delete origin_log_copy.txt file ");
// 删除错误日志副本
File fileError = new File(pathAll + File.separator + "error_log_copy.txt");
if (fileError.exists()) {
fileError.delete();
}
System.out.println("错误参数断言日志副本已删除。delete error_log_copy file ");
} catch (Exception e) {
e.printStackTrace();
}
}
}
再将txt文件的日志(需求所要的列复制粘贴到Excel)
待续