机器学习实战 - 第4章 基于概率论的分类方法:朴素贝叶斯
一、基于贝叶斯决策理论的分类方法
朴素贝叶斯的优点:在数据较少的情况下仍然有效,可以处理多类别问题。
缺点:对于输入数据的准备方式较为敏感。
使用数据类型:标称型数据(一般在有限的数据中取,而且只存在是和否两种不同的结果)。
朴素贝叶斯是贝叶斯决策理论的一部分。贝叶斯决策理论:假设有一个数据集,它由两类数据组成,在判断具体数据属于哪个类别时,会选择高概率对应的类别。这就是贝叶斯决策理论的核心思想,即选择具有最高概率的决策。
贝叶斯使用先验知识和逻辑推理来处理不确定性命题。频数概率:它只从数据本身获得结论,并不考虑逻辑推理及先验知识。
二、条件概率
条件概率:P(A|B) = P(A and B) / P(B)
贝叶斯准则计算条件概率:贝叶斯准则告诉如何交换条件概率中的条件与结果。
P(c|x) = P(x|c)P© / P(x)
三、使用条件概率来分类
具体到(x, y)点属于c1还是c2,计算公式是:P(ci|(x,y)) = P((x,y)|ci)P(ci) / P((x,y))
四、使用朴素贝叶斯进行文档分类
朴素贝叶斯分类器的两个假设:1. 每个特征同等重要;2.特征之间相互独立。
五、使用python进行文本分类
- 准备数据:从文本中构建词向量
把文本看成单词向量或者词条向量,也就是讲句子转换为向量。先将文档切分成单词;再将所有文档中出现的单词形成不重复的词汇表;最后将某文档通过词汇表转化为文档向量。
- 训练算法:从词向量计算类别概率
用w表示文档向量
P(c|w) = P (w|c)P© / P(w)
对每个类计算概率值,然后比较概率值的大小。

- 测试算法:根据现实情况修改分类器
问题一:
概率为0的问题。利用贝叶斯分类器对文档进行分类时,要计算多个概率的乘积以获得文档属于某个类别的概率,即计算p(w0|1)p(w1|1)p(w2|1)。如果其中一个概率值为0,那么最后的乘积也为0。为降低这种影响,可以将所有词的出现数初始化为1,并将分母初始化为2。
问题二:
下溢出的问题。这是由于太多很小的数相乘造成的。计算p(w0|ci)p(w1|ci)……p(wn|ci)时,由于大部分因子非常小,所以程序会下溢出或者得到不正确的答案(许多很小的数相乘,结果会得到0)。
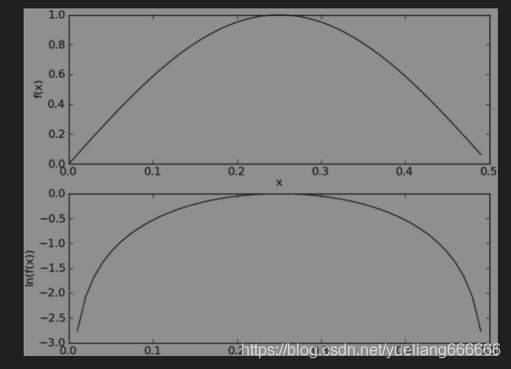
解决方法一:对乘积取自然对数。ln(a*b) = ln(a) + ln(b)
下图中f(x)与ln(f(x))的曲线,在相同区域内同时增加或者减少,并且在相同点上取到极值。取值虽然不同,但不影响最终结果。
- 准备数据:文档词袋模型
将每个词的出现与否作为一个特征,可以被描述为词集模型。
如果一个词在文档中出现不止一次,这可能意味着包含该词是否出现在文档中所不能表达的某种信息,这种方法被称为词袋模型。
在词袋中每个单词可以出现多次,而在词集中,每个词只能出现一次。为适应词袋模型,将setOfWords2Vec()方法改为bagOfWords2Vec()。
bagOfWords2Vec相较于setOfWords2Vec的改变是,当遇到一个单词时,会增加词向量中的对应值,而不只是将对应的数值设为1。
六、示例:使用朴素贝叶斯过滤垃圾邮件
-
收集数据:提供文本文件
-
准备数据:将文本文件解析成词条向量
-
分析数据:检查词条确保解析的正确性
-
训练算法:使用之前建立的trainNB0函数
-
测试算法:使用classifyNB(),并且构建一个新的测试函数来计算文档集的错误率
-
使用算法:构建一个完整的程序对一组文档进行分类,将错分的文档输出在屏幕上
七、本章小节
可以通过特征之间的条件独立性假设,降低对数据量的需求。独立性假设是指一个词的出现概率并不依赖于文档中的其他词。这个假设过于简单,这也就被称为朴素贝叶斯的原因。
还需要考虑实际的一些问题。比如下溢出,他可以通过对概率取对数来解决。词袋模型在解决文档分类问题上比词集模型有所提高。还有其他方面的改进,比如说移除停用词,当然也可以话大量时间对切分器进行优化。
八、附加:python的一些使用方法
正则切分:
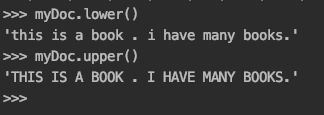
myDoc = ‘This is a book . I have many books.’
import re
regEx = re.compile("\W* ")
res = regEx.split(myDoc)

python中的内嵌方法,将字符串全部转化成小写(.lower())或者大写(.upper())