Elasticsearch写入原理剖析
Elasticsearch写入原理剖析
- Elasticsearch 集群与路由
-
- 节点(Node):
- 分片(Shard):
- 分片的类型
- 副本(Replica):
- Elasticsearch 文件合并与刷新
- Elasticsearch 数据存储可靠性
- 总结
Elasticsearch 集群与路由
在介绍数据如何写入到 ES(下文用 ES,统称 Elasticsearch)之前需要了解 ES 的集群架构,也就是说了解数据如何存放在 ES 的集群节点中的。
这里需要引入几个关键词,帮助大家理解一些 ES 中的基本概念:
节点(Node):
用来运行的 ES 实例,是以进程的方式存在,节点是运行在物理服务器上的。
索引文件(Index):是需要写入到 ES 节点中的数据,其数据模型信息 Mapping(数据结构)以及数据文件(数据内容)。索引文件可以分布在一个节点,也可以分布在多个不同的节点。
分片(Shard):
用来存放索引文件或者索引文件的一部分信息。如果一个索引包含海量文档,同时单个节点所在的物理服务器硬件能力有限,会导致存储索引文件的容量有限。
这个“大”的索引文件就不能存放在一个节点中,所以 ES 提供分片机制,可以让一个索引文件存放在不同节点的不同分片中。
索引文件可以按某个维度分成多个部分,每个部分就是一个分片,分片被节点(Node)管理。
一个节点(Node)会管理多个分片,分片可能是属于同一个索引,也有可能属于不同索引,为了可靠性和可用性,同一个索引的分片尽量会分布在不同节点(Node)上。
分片的类型
分片是承载索引(数据)的基本单位,它可以分为两种类型:主分片和副本分片。
主分片会被尽可能平均地分配在不同的节点上,副本分片顾名思义是主分片的一个副本,用于提供数据的冗余副本。
一般而言副本分片和主分片不会出现在同一个节点上,原因是当单一节点出现故障的时候,只会影响这个节点上的分片,而在其他节点的分片还可以正常工作。
需要注意的是,这里只有主分片才能处理索引写入请求,副本分片只是用来存储数据。
副本(Replica):
同一个分片(Shard)的备份数据,一个分片可能会有 0 个或多个副本,这些副本中的数据保证强一致或最终一致。
前面介绍完 ES 的基本概念之后,我们对 ES 的数据存放有大致的了解。索引会根据规则进行分片,分片又分为主分片和副本分片。
主分片用来处理索引写入的请求,副本分片用来存储索引数据。分片会运行在节点上,而节点运行在物理服务器上。
由于 ES 分布式的数据存储模式,导致索引数据会保存在不同的节点和分片上面,因此在写入索引的时候需要遵循一定规则,也就是接下来要介绍的路由规则。
ES 的路由规则是在一个多分片的索引中写入数据时,通过路由来确定具体写入哪一个分片中,这确定的过程会通过如下这个公式实现:
shard = hash(routing) % number_of_primary_shards
routing 是一个可变值,默认是文档的 _id,也可以设置成一个自定义的值。
routing 通过 hash 函数生成一个数字,然后这个数字再除以 number_of_primary_shards(主分片的数量)后得到余数 。
这个在 0 到 number_of_primary_shards 之间的余数,就是所寻求的文档所在分片的位置。
这解释了为什么要在创建索引的时候就确定好主分片的数量并且永远不会改变这个数量:因为如果数量变化了,那么所有之前路由的值都会无效,文档也再也找不到了。
索引中的每个文档属于一个单独的主分片,所以主分片的数量决定了索引最多能存储多少数据(实际的数量取决于数据、硬件和应用场景)。
这里举个例子帮助大家理解上面的路由公式。ES 集群中每个节点通过路由都知道集群中的文档的存放位置,所以每个节点都有处理读写请求的能力。
这种节点被称为协调节点,协调节点会根据路由公式计算出需要写到哪个分片上,再将请求转发到该分片的主分片节点上。需要注意的是,虽然协调节点是将处理写请求按照路由规则转发给主分片。
如图 1 所示,这里有 ES1、2、3 三个节点,每个节点中包含若干个分片,其中 S0、1、2、3 为主分片,其他“R”开头的为副本分片。
图 1:ES 写入数据的路由过程
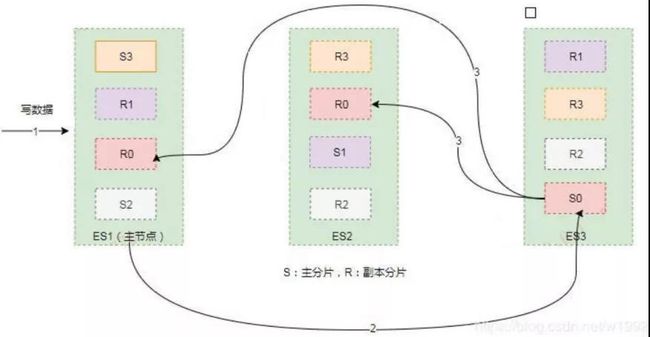
这里路由规则为 shard = hash(routing) % 4 = 0,这里的 4 是主分片的数量,假设结果为“0”,也就是将数据写入到 S0 主分片上。
路由过程大致如下:
客户端向 ES1 节点(协调节点)发送写请求,通过路由计算公式得到值为 0,则当前数据应被写到主分片 S0 上。
ES1 节点将请求转发到 S0 主分片所在的节点 ES3,ES3 接受请求并写入到磁盘。
并发将数据复制到两个副本分片 R0 上,其中通过乐观并发控制数据的冲突。一旦所有的副本分片都报告成功,则节点 ES3 将向协调节点报告成功,协调节点向客户端报告成功。
上面的写入流程中涉及到了协调节点,主分片和副本分片的数据写入,这里对这三块的写入进行进一步的分析。
协调(coordinating)节点
ES 中接收并转发请求的节点称为协调节点,ES 中所有节点都可以接受并转发请求。
当一个节点接受到写入或更新请求后,会执行如下操作:
①ingest pipeline:是一个请求预处理的管道,会根据规则对请求进行预处理工作。
它会查看请求是否符合某个 ingest pipeline 的 pattern, 如果符合则执行 pipeline 中的逻辑,一般是对文档进行各种预处理,如格式调整,增加字段等。
②自动创建索引:判断索引是否存在,如果开启了自动创建则自动创建,否则报错。
③设置 routing:获取请求 URL 或 mapping 中的 _routing,如果没有则使用 _id,如果没有指定 _id 则 ES 会自动生成一个全局唯一 ID。该 _routing 字段用于决定文档分配在索引的哪个 shard 上。
④构建 BulkShardRequest:创建多操作请求,假设 Bulk Request 中包含多种(Index/Update/Delete)请求,同时这些请求需要在不同分片上执行。
需要通过这个步骤将请求按照分片进行区分,同一个分片上的请求聚合到一起,从而构建 BulkShardRequest。
⑤将请求发送给 primary shard:用户请求如果是写操作,会将请求路由到主分片所在的节点,并且等待主分片写入结果的返回信息。
主分片
主分片请求的入口是 PrimaryOperationTransportHandler 的 MessageReceived。
当接收到请求时,执行如下步骤:
①判断操作类型:如果是 Bulk Request 会遍历请求中的子操作,根据不同的操作类型跳转到不同的处理逻辑。
②操作转换:将 Update 操作转换为 Index 和 Delete 操作。
③解析文档(Parse Doc):解析文档的各字段。
④更新 Mapping:如果请求中有新增字段,会根据 dynamic mapping 或 dynamic template 生成对应的 mapping,如果 mapping 中有 dynamic mapping 相关设置则按设置处理。
⑤获取 sequence Id 和 Version:从 SequenceNumberService 获取一个 SequenceID 和 Version。
SequenceID 用于初始化 LocalCheckPoint,version 是根据当前 versoin+1 用于防止并发写导致数据不一致。
⑥写入 Lucene:对索引文档 uid 加锁,然后判断 uid 对应的 version v2 和之前 update 转换时的 version v1 是否一致,不一致则返回第二步重新执行。
在 version 一致的情况下根据id的情况执行添加或者更新操作。如果同 id 的 doc 已经存在,则调用 updateDocument 接口。
⑦写入 translog:写入 Lucene 的 Segment 后,会以 key value 的形式写 Translog, Key 是 Id,Value 是索引文档的内容。
当查询的时候,如果请求的是 GetDocById 则可以直接根据 _id 从 translog 中获取。写入 translog 的操作会在下面的章节中详细讲解。
⑧重构 bulk request:已经多个操作中的 update 操作转换为 index、delete 操作,最终都以 index 或 delete 操作的方式组成 bulk request 请求。
⑨落盘 Translog:默认情况下,translog 要在此处落盘完成,如果对可靠性要求不高,可以设置 translog 异步落盘,同时存在数据有丢失的风险。
⑩发送请求给副本分片:将构造好的 bulk request 发送给各个副本分片,并且等待副本分片返回,然后再响应协调节点。如果某个分片执行失败,主分片会给主节点发请求移除该分片。
等待 replica 响应:当所有的副本分片返回请求时,更新主分片的 LocalCheckPoint。
副本分片
副本分片请求的入口是在 ReplicaOperationTransportHandler 的 messageReceived,其大致过程于主分片相似,相同的步骤这里就不赘述了。
将其列出供大家参考:
判断操作类型:写入请求在主分片上已经转换为 add 或 delete 操作了,因此这里只需要根据操作类型执行即可。
解析文档(Parse Doc):同主分片。
更新 Mapping:同主分片。
获取 sequenceId 和 Version:使用主分片发送过来的内容即可。
写入 Lucene:同主分片。
写入 Translog:同主分片。
落盘 translog:同主分片。
Elasticsearch 文件合并与刷新
前面介绍了 ES 索引写入的流程,当索引保存到 ES 集群中时,会通过路由规则找到对应的分片写入数据,主分片在接受到数据以后也会同步到副本分片上完成整个写入。
在了解了文件写入流程以后,再来近距离观察一下写入的细节,看看索引是如何通过内存最终写入磁盘的。
如图 2 所示,这里列出了索引写入的步骤,分别在内存和磁盘中完成写入操作。
图 2:ES 写入流程
如图 2 所示,将每一步写入操作进行拆解如下:
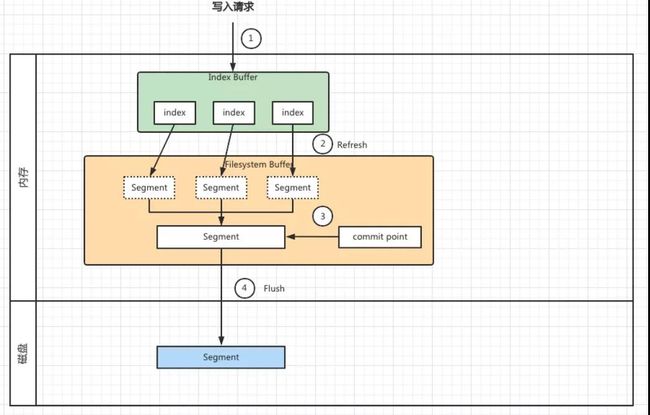
①写入请求会将索引(Index)存放到内存区域,叫做 Index Buffer。此时的索引文件暂时是不能被ES搜索到的。
②默认情况下 ES 每秒执行一次 Refresh 操作,将 Index Buffer 中的 index 写入到 Filesystem 中,这个也是一片内存区域。
把 Index Buffer 中的 index 转化为 Segment,此时的数据就可以被 ES 搜索到了。
这也是 ES 的近实时搜索,当索引保存到 Index Buffer 的时候是无法被搜索到的,直到被 Refresh 成 Segment 之后才能被搜索到。
需要说明的是,Refresh 触发的条件有两种,其中一种是按照时间频率触发,默认情况是每 1 秒触发 1 次 Refresh,可通过 index.refresh_interval 设置。
这也是为什么人们称 Elasticsearch 为近实时搜索的原因了。
还有一种触发方式是当 Index Buffer 被占满的时候,会触发 Refresh,Index Buffer 的大小默认值是 JVM 所占内存容量的 10%。
当 Refresh 之后 Index Buffer 的数据会写入到 Segment 中,此时 Index Buffer 的数据会被清空。
③ES 每次 refresh 都会生成一个 Segment 文件,这样下来 Segment 文件会越来越多。
由于每个 Segment 都会占用文件句柄、内存、CPU 资源,假设每次搜索请求都会访问对应 Segment 获取数据,这就意味着 Segment 越多会加大搜索请求的负担,导致请求变慢。
为了提高搜索性能 ES 会定期对 Segment 进行合并(Merge)操作,也就是将多个小 Segment 合并成一个 Segment。那么搜索请求就直接访问合并之后的 Segment,从而提高搜索性能。
④上面 3 个步骤都是在内存中完成的,此时数据还没有写到磁盘中。随着 Segment 的增大内存空间是有限的,因此需要将数据写入到磁盘中。
因此在合并完成后,会将新的 Segment 文件 Flush 写入磁盘。此时 ES 会创建一个 Commit Point 文件,该文件用来标识被 Flush 到磁盘上的 Segment。
由于 Segment 从内存提交到了磁盘上就需要这个 Commit Point 文件进行记录,它记录了 Segment 的去向,旧的 Segment 以及合并之前的小 Segment 会被从中移除。
为此 Commit Point 会创建一个 .del 的文件用来存放移除的 Segment 信息。
需要注意的是 Flush 的目的是为了持久化,毕竟 Segment 是存放在内存中的,始终是要保存到磁盘上的。
在执行 Flush 的时候会依次执行下面操作:
Index Buffer 被清空
记录 Commit Point
Filesystem Buffer 内的 Segment 被 fsync 刷新到磁盘
translog 被删除(后面会详细介绍 translog)
Flush 触发的条件是,每 30 分钟或当 translog 达到一定大小(由 index.translog.flush_threshold_size 控制,默认 512mb),也就是说在满足以上条件是 ES 会触发 Flush。
Elasticsearch 数据存储可靠性
前面讲解了 ES 的文件合并和刷新,分四个步骤详细介绍了索引写入的过程。
索引文档最开始是存放在内存的 Index Buffer 中,当执行了 Refresh 操作会将其保存为 Segment,此时就可以供用户查询了。
但是 Segment 在 Flush 之前仍然存在于内存中,如果此时服务器宕机,而 ES 还没有 Flush 操作保存在内存中的 Segment 数据将会丢失。
为了提高 ES 的数据存储可靠性,引入了 Translog。在每次用户请求 Index Buffer 进行操作的时候都会写一份操作记录到 Translog 中,Translog 使用特有的机制保存到磁盘中。
ES 默认每个请求都会将 Translog 同步到磁盘,即配置 index.translog.durability 为 request。
但是这样会 ES 的性能有所影响,因此可以针对一些能够容忍丢失数据的场景设置异步落盘的操作。
可以将 index.translog.durability 配置为 async 来提升写入 Translog 的性能,该配置会异步写入 translog 到磁盘。写入磁盘的频率通过 index.translog.sync_interval 来控制。
另外,Translog 随着请求数量在不断扩张,和 Segment 合并文件一样的道理,需要将其整体保存到磁盘上。
这也是上一节提到的 Flush 操作,当 Flush 操作将 Segment 进行落盘的时候也会将 Translog 进行落盘。
每一次 Flush 后,由于 Translog 完成落盘,因此原有的 Translog 将被移除,在内存中会重新创建一个新的 Translog。
由于 Translog 是追加写入,性能方面还是比较优越的。当机器宕机的时候,启动 ES 服务时会读取 Translog 的信息,并且将中间的操作命令进行回放从而起到回复数据的目的。
延续上一节的例子,在原有的基础上加入 Translog 的部分。如图 3 所示,在整个 ES 写入流程中加入 Translog,目的是为了提高 ES 的数据存储可靠性。

图 3:引入 Translog
图中 Translog 存在于内存和磁盘中,分别有两个线将其相连,表示了 Translog 同步的两种方式:
在 ES 处理用户请求时追加 Translog,追加的内容就是对ES的请求操作。此时会根据配置同步或者异步的方式将操作记录追加信息保存到磁盘中。
另一种 Translog 从内存到磁盘的操作是在 Flush 发生的时候,上节中介绍过,Flush 操作会把 Segment 保存到磁盘同时还会将 Translog 的文件进行落盘。落盘以后存在与内存中的 Translog 就会被移除。
总结
总结,本文的重点放在 ES 的写入过程,首先介绍了 ES 的基本定义,然后从一个写入请求切入引出了 ES 集群和路由实现。
ES 会根据路由讲写入请求通过协调节点发送到主分片上,主分片再同步数据到副本分片上。
接着又介绍了在协调节点、主分片以及副本分片上发上的写入的操作。从宏观上了解 ES 写入流程之后,再从微观的角度描述索引文档如何经过内存写入磁盘的过程。
索引文档在写入到 Index Buffer 以后,会通过 Refresh 操作将其保存到 Filesystem 的内存缓冲区内,此时写入的索引文档会转化成 Segment 并且可以被用户搜索到了。
同时,随着 Segment 数量的增多,ES 提供了合并机制,将多个小的 Segment 合并成大的 Segment,从而提高搜索的效率。
为了提供 ES 数据存储的可靠性,会使用 Translog 机制追加 ES 请求命令,并且通过 Flush 机制将内存中的 Segment 以及 Translog 进行落盘操作。