Elasticsearch集群及数据读写原理
文章目录
-
-
-
- 集群节点
- 搭建集群
-
- 部署文件
- 修改配置
- 服务启动
- 状态查询
- 分片和副本
- 故障转移
-
-
- 将data节点停止
- 将master节点停止
-
- 分布式文档读写
-
- 路由
- 文档写操作
- 文档搜索操作
- 全文搜索
-
-
集群节点
ELasticsearch的集群是由多个节点组成的,通过cluster.name设置集群名称,并用于区分其它的集群,每个节点通过node.name指定节点的名称。在Elasticsearch中,节点的类型主要有4种:
master节点
配置文件中node.master属性为true(默认为true),就有资格被选为master节点。master节点用于控制整个集群的操作。比如创建或删除索引,管理其它非master节点等。
data节点
配置文件中node.data属性为true(默认为true),就有资格被设置成data节点。data节点主要用于执行数据相关的操作。比如文档的CRUD。
客户端节点
配置文件中node.master属性和node.data属性均为false。
该节点不能作为master节点,也不能作为data节点。可以作为客户端节点,用于响应用户的请求,把请求转发到其他节点
部落节点
当一个节点配置tribe.*的时候,它是一个特殊的客户端,它可以连接多个集群,在所有连接的集群上执行搜索和其他操作
搭建集群
部署文件
将部署有单体es服务的虚拟及进行克隆,并修改ip 分别为 :
192.168.12.10 (node01) 192.168.12.11 (node02) 192.168.12.12(node03)
或者在三台虚拟机 中 部署 ES 及 IK分词插件 ,安装步骤见之前笔记
修改配置
分别修改 三台服务器的 es配置文件 elasticsearch.yml 内容如下:
node01:
cluster.name: es-cluster
node.name: node01
node.master: true
node.data: true
network.host: 0.0.0.0
http.port: 9200
discovery.zen.ping.unicast.hosts: ["192.168.12.10","192.168.12.11","192.168.12.12"]
discovery.zen.minimum_master_nodes: 2
http.cors.enabled: true
http.cors.allow-origin: "*"
node02
cluster.name: es-cluster
node.name: node02
node.master: true
node.data: true
network.host: 0.0.0.0
http.port: 9200
discovery.zen.ping.unicast.hosts: ["192.168.12.10","192.168.12.11","192.168.12.12"]
discovery.zen.minimum_master_nodes: 2
http.cors.enabled: true
http.cors.allow-origin: "*"
cluster.name: es-cluster
node.name: node03
node.master: true
node.data: true
network.host: 0.0.0.0
http.port: 9200
discovery.zen.ping.unicast.hosts: ["192.168.12.10","192.168.12.11","192.168.12.12"]
discovery.zen.minimum_master_nodes: 2
http.cors.enabled: true
http.cors.allow-origin: "*"
服务启动
如果是直接将安装好的es目录复制到其他节点(或者虚拟机克隆)需要删除 es目录下的 data 目录,否则启动会报错
bin/elasticsearch
正常启动后 通过elasticsearch-head 看到 node02是主节点,同时可以看到 各个索引分片(及备份分片)在各个节点的分布

状态查询
查询集群状态接口 http://192.168.12.10:9200/_cluster/health
{
"cluster_name": "es-cluster",
"status": "green",
"timed_out": false,
"number_of_nodes": 3,
"number_of_data_nodes": 3,
"active_primary_shards": 9,
"active_shards": 14,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 0,
"delayed_unassigned_shards": 0,
"number_of_pending_tasks": 0,
"number_of_in_flight_fetch": 0,
"task_max_waiting_in_queue_millis": 0,
"active_shards_percent_as_number": 100
}
集群状态有三种颜色:
green 所有主要分片和复制分片都可用
yellow 所有主要分片可用,但不是所有复制分片都可用
red 不是所有的主要分片都可用
分片和副本
为了将数据添加到Elasticsearch,我们需要建立索引(index)——一个存储关联数据的地方。实际上,索引只是一个用来指向一个或多个分片(shards)的“逻辑命名空间(logical namespace)”.
一个分片(shard)是一个最小级别“工作单元(worker unit)”,它只是保存了索引中所有数据的一部分。一个分片就是一个Lucene实例,并且它本身就是一个完整的搜索引擎。应用程序不会和它直接通信。
分片可以是主分片(primary shard)或者是复制分片(replica shard)。
索引中的每个文档属于一个单独的主分片,所以主分片的数量决定了索引最多能存储多少数据。
复制分片只是主分片的一个副本,它可以防止硬件故障导致的数据丢失,同时可以提供读请求,比如搜索或者从别的shard取回文档。
当索引创建完成的时候,主分片的数量就固定了,但是复制分片的数量可以随时调整。
故障转移
三个节点都正常时分片在各个节点的分布情况如下
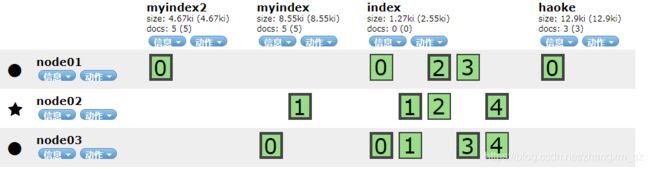
将data节点停止

由于myindex没有备份分片 且主分片在node03 上因此 node 03 关闭后,myindex 的分片不可用,显示红色。删除myindex索引后集群回复绿色,其他索引的分片重新分布。如下:

重新启动node03 后 node03 再次加入集群,且各个索引的分片信息重新分布
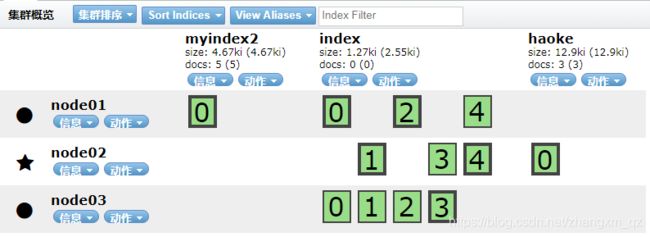
如果没有复制分片,容错性较差 万一出现宕机则索引数据不可用。
我们这里只保留index索引,其他索引删除
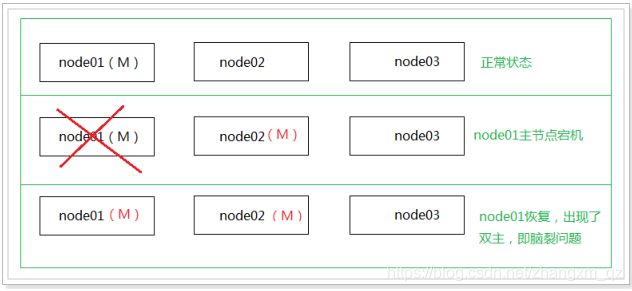
将master节点停止
master节点 node02 停止后,发现es集群重新选举了node01作为主节点,且集群状态显示为黄色:

一段时间后集群中剔除了node02节点,且集群状态恢复了绿色,同时索引分片在各个节点重新分布
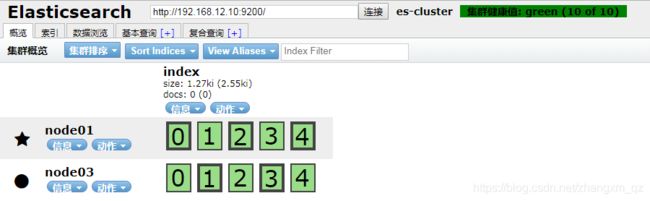
重启node02节点后,,发现node02可以正常加入到集群中,集群状态依然为绿色

特别说明:
如果在配置文件中discovery.zen.minimum_master_nodes设置的不是N/2+1时,会出现脑裂问题,之前宕机的主节点恢复后可能不会加入到集群
分布式文档读写
路由
当一个集群保存某个文档时,文档该存储到哪个节点呢? 是随机吗? 是轮询吗?
实际上,在ELasticsearch中,会采用计算的方式来确定存储到哪个节点,计算公式如下:
shard = hash(routing) % number_of_primary_shards
说明:
routing值是一个任意字符串,它默认是_id但也可以自定义。这个routing字符串通过哈希函数生成一个数字,然后除以主切片的数量得到一个余数(remainder),余数的范围永远是0到number_of_primary_shards - 1,这个数字就是特定文档所在的分片。这就是为什么创建了主分片后,不能修改的原因。
文档写操作
新建、索引和删除请求都是写(write)操作,它们必须在主分片上成功完成才能复制到相关的复制分片上
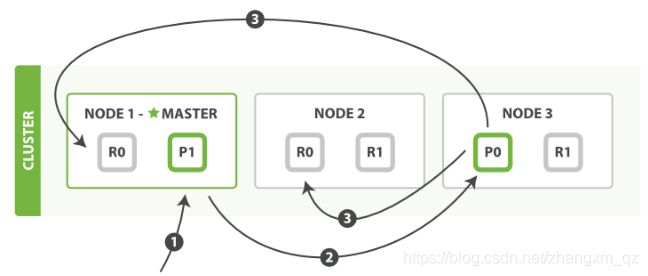
步骤说明:
- 客户端给 Node 1 发送新建、索引或删除请求。
- 节点使用文档的 _id 确定文档属于分片 0 。它转发请求到 Node 3 ,分片 0 位于这个节点上。
- Node 3 在主分片上执行请求,如果成功,它转发请求到相应的位于 Node 1 和 Node 2 的复制节点。当所有的复制节点报告成功, Node 3 报告成功到请求的节点,请求的节点再报告给客户端。
客户端接收到成功响应的时候,文档的修改已经被应用于主分片和所有的复制分片,修改就生效了。
文档搜索操作
文档能够从主分片或任意一个复制分片被检索。
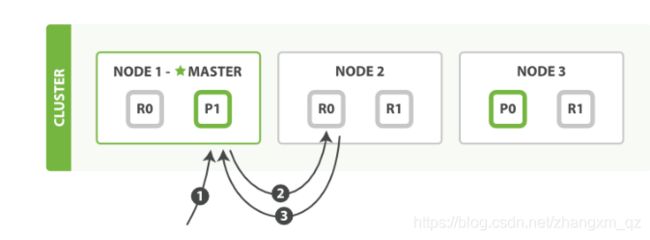
步骤说明:
- 客户端给 Node 1 发送get请求。
- 节点使用文档的 _id 确定文档属于分片 0 。分片 0 对应的复制分片在三个节点上都有。此时,它转发请求到Node 2 。
- Node 2 返回文档(document)给 Node 1 然后返回给客户端。
对于读请求,为了平衡负载,请求节点会为每个请求选择不同的分片——它会循环所有分片副本。
可能的情况是,一个被索引的文档已经存在于主分片上却还没来得及同步到复制分片上。这时复制分片会报告文档未找到,主分片会成功返回文档。一旦索引请求成功返回给用户,文档则在主分片和复制分片都是可用的。
全文搜索
对于全文搜索而言,文档可能分散在各个节点上,那么在分布式的情况下,如何搜索文档呢?
搜索分为2个阶段,搜索(query)+取回(fetch)。
搜索

主要包含以下三步:
- 客户端发送一个 search(搜索) 请求给 Node 3 , Node 3 创建了一个长度为 from+size 的空优先级队
- Node 3 转发这个搜索请求到索引中每个分片的原本或副本。每个分片在本地执行这个查询并且结果将结果到一个大小为 from+size 的有序本地优先队列里去。
- 每个分片返回document的ID和它优先队列里的所有document的排序值给协调节点 Node 3 。 Node 3 把这些值合并到自己的优先队列里产生全局排序结果
取回
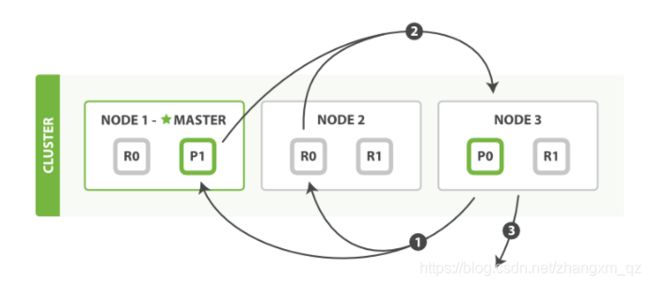
取回阶段由以下步骤构成:
- 协调节点辨别出哪个document需要取回,并且向相关分片发出 GET 请求。
- 每个分片加载document并且根据需要丰富(enrich)它们,然后再将document返回协调节点。
- 一旦所有的document都被取回,协调节点会将结果返回给客户端。