机器学习-生成对抗网络WGAN-GP实战(四-2)
这里就涉及到WGAN-GP的训练代码,这一部分相对比较繁琐,和传统的GAN相比,关键就是损失函数的计算和梯度的计算。还是建议大家先读机器学习-生成对抗网络变种(三),有个基础概念。涉及到公式的地方我会着重说明。
Part2WGAN-GP训练过程:
主函数(主要部分):
for epoch in range(epochs):
for _ in range(5):
batch_z = tf.random.normal([batch_size, z_dim])##从正态分布中采集隐藏向量
batch_x = next(db_iter)# 从数据集采样真实图片
# train D
with tf.GradientTape() as tape:
d_loss, gp = d_loss_fn(generator, discriminator, batch_z, batch_x, is_training)
grads = tape.gradient(d_loss, discriminator.trainable_variables)
d_optimizer.apply_gradients(zip(grads, discriminator.trainable_variables))
batch_z = tf.random.normal([batch_size, z_dim])
with tf.GradientTape() as tape:
g_loss = g_loss_fn(generator, discriminator, batch_z, is_training)
grads = tape.gradient(g_loss, generator.trainable_variables)
g_optimizer.apply_gradients(zip(grads, generator.trainable_variables))如果大家仔细看,会发现训练过程和DCGAN是没有差别的,实际上WGAN-GP的本质就是引入了梯度惩罚项(Gradient Penalty)。这一点在计算损失函数时会体现出来。
咱们接着看代码,采样和之前的没区别,训练过程也没区别第一步就先训练判别器。
判别器的训练:
要相对网络进行训练,损失函数是必不可少的。
def d_loss_fn(generator, discriminator, batch_z, batch_x, is_training):
# 1. treat real image as real
# 2. treat generated image as fake
fake_image = generator(batch_z, is_training)
d_fake_logits = discriminator(fake_image, is_training)
d_real_logits = discriminator(batch_x, is_training)
d_loss_real = celoss_ones(d_real_logits)
d_loss_fake = celoss_zeros(d_fake_logits)
gp = gradient_penalty(discriminator, batch_x, fake_image)
loss = d_loss_real + d_loss_fake + 10. * gp
return loss, gp先利用生成器生成一个图片,送入判别器得到一个结果,把真实图片送入判别器也得到一个结果。接着计算真假图片对于预期1/0的损失。下面要计算梯度惩罚项(Gradient Penalty)GP,也是本方法区别于其他方法的核心所在,大家需要掌握。
求GP的具体原理过程大家跟着代码看会有一个清晰的了解。推导过程比较繁琐,大家只需要知道怎么做,并且这一步是怎么得到的就可以。
def gradient_penalty(discriminator, batch_x, fake_image):
batchsz = batch_x.shape[0]#实际上就是分批数量
# [b, h, w, c] t是从标准正态分布中随机取样的
t = tf.random.uniform([batchsz, 1, 1, 1])
# 扩展[b, 1, 1, 1] => [b, h, w, c]
t = tf.broadcast_to(t, batch_x.shape)#对矩阵进行扩展
# 在真假图片之间做线性差值 t是0~1之间的数
interplate = t * batch_x + (1 - t) * fake_image
with tf.GradientTape() as tape:
tape.watch([interplate])
#计算经过判别器的输出
d_interplote_logits = discriminator(interplate, training=True)
#求interplate的梯度
grads = tape.gradient(d_interplote_logits, interplate)
# grads:[b, h, w, c] => [b, -1]
grads = tf.reshape(grads, [grads.shape[0], -1])
gp = tf.norm(grads, axis=1) #[b] 求范数
gp = tf.reduce_mean( (gp-1)**2 )#求完范数根据公式求gp
return gp首先我们要得到一个经过改良的,综合了真实图片和生产图片的新输入 ,需要一个随机的t来对真实图片和生产图片做线性差值。大家看代码,t是利用random.uniform得到介于0~1之间的数值,可以近似看作对二者取值的比例。接着对t进行矩阵扩展为和真实输入形状一样。根据公式就得到了新输入。
,需要一个随机的t来对真实图片和生产图片做线性差值。大家看代码,t是利用random.uniform得到介于0~1之间的数值,可以近似看作对二者取值的比例。接着对t进行矩阵扩展为和真实输入形状一样。根据公式就得到了新输入。
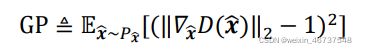
根据gp的公式我们可以知道,我们需要对经过判别器的结果求梯度。大家看代码,我们先得到经过判别器的输出,接着求了梯度存放在grads中。根据公式使用tf.norm得到梯度的范数,范数-1求平方就得到了所求的gp。
得到的损失函数就是真实图片的损失和生成图片的损失以及gp*参数的和,我们最终希望损失函数尽可能小,因为损失函数越小则表明预测的越准确。
生成器的训练:
def g_loss_fn(generator, discriminator, batch_z, is_training):
fake_image = generator(batch_z, is_training)
d_fake_logits = discriminator(fake_image, is_training)
loss = celoss_ones(d_fake_logits)
return loss针对生成图片做训练,即将随机取样的噪声传入生成器,再将结果送入判别器,注意,损失函数是生成图片经过判别器的结果与真的差距。最后利用梯度下降法,使得损失函数越来越小,达到可以欺骗判别器的目的。
最后再唠叨几句:这个梯度惩罚项GP是仅再判别器的训练中使用的,生成器的训练和普通的GAN一样,大家可以进行对比学习,这样会有更好的效果。
代码来自于《TensorFlow深度学习》-龙龙老师
