ACCV2020细粒度比赛记录-数据处理和Baseline结果分享
比赛链接:
- accv官网:https://sites.google.com/view/webfg2020
- 比赛网站:https://www.cvmart.net/race/9917/base
数据下载:
- Baidu / 百度云盘:
链接: https://pan.baidu.com/s/1P0rpg0J34IUL5bvuA5f-pg
提取码: cg9z- Google / 谷歌云盘
https://drive.google.com/drive/folders/1ruvJow2Srp3wuqG1sYd_unG1EHBxYvI-?usp=sharing
Linux下合并解压:cat train.tar.gz.* | tar -zxv
1.数据清洗
训练集:5000类,557,169张图片
测试集:5000类,100,000张图片
由于数据来源于网络,可以视为直接从网站上爬虫下来且后缀全部改成了jpg格式,而从实际情况来看图片原本包含的格式有jpg、png、gif、tiff等,这就会导致使用代码读取的时候报错(Error)或者警告(Warning),因此需要先对数据进行清洗。Warning由于不会对程序运行造成影响,需要转换成可报错的Error,代码如下。
import warnings
warnings.filterwarnings('error')
根据实际情况清理出的报错主要有以下几种
-
corrupt EXIF和Possibly corrupt EXIF,这种是EXIF信息缺失导致的,筛选出来再去掉其EXIF头就可以了# Refer: https://blog.csdn.net/a19990412/article/details/105940446 # pip install piexif -i https://pypi.tuna.tsinghua.edu.cn/simple/ import piexif piexif.remove(img_path) -
Palette images with Transparency是在PIL调用convert('RGB')的时候抛出的,大概是说alpha通道的转换问题,暂时没有解决,先把非RGB(通道数不为3)的图筛选出来,因为后来发现不止4通道图,还有单通道和双通道的图,再单独对这部分数据筛选报错的,发现数量较少,直接从数据集中剔除处理。 -
image file could not be identified because WEBP,这是由于有的数据原本是webp格式,PIL读取有问题,而且好像是conda环境下才存在,解决方案有几种:- 升级PIL库,6.x,7.x是没有问题但是会抛出新的问题,为了避免麻烦,就用的5.4.1版本
pip install Pillow==5.4.1- 安装webp库,更新PIL解决了就没有实测
-
未知错误,在一开始排查没有查出来,所幸用了screen保存历史log,未知错误也只有几张,直接筛选出来了,错误信息如下:
Image size (117762898 pixels) exceeds limit of 89478485 pixels Metadata Warning, tag 296 had too many entries Image appears to be a malformed MPO file
完整代码:
step1: 遍历所有图片,筛选有问题的
import os
from PIL import Image
import cv2
import warnings
warnings.filterwarnings('error')
root = './train'
f1 = open('pExifError.txt', 'w')
f2 = open('rgbaError.txt', 'w')
f3 = open('ExifError.txt', 'w')
f4 = open('4chImg.txt', 'w')
f5 = open('WebpError.txt', 'w')
f6 = open('UnknownError.txt', 'w')
idx = 0
for r, d, files in os.walk(root):
if files != []:
for i in files:
fp = os.path.join(r, i)
try:
img = Image.open(fp)
if(len(img.split()) != 3):
# print('4CH:', fp)
f4.write('{}\n'.format(fp))
except Exception as e:
print('Error:', str(e))
print(fp)
if 'Possibly corrupt EXIF data' in str(e):
print('Exif error')
f1.write('{}\n'.format(fp))
elif 'Palette images with Transparency' in str(e):
print('rgba error')
f2.write('{}\n'.format(fp))
elif 'Corrupt EXIF data' in str(e):
print('pExif error')
f3.write('{}\n'.format(fp))
elif 'image file could not be identified because WEBP' in str(e):
print('Webp error')
f5.write('{}\n'.format(fp))
else:
print('Unknown error')
f6.write('{}\n'.format(fp))
if idx % 5000 == 0:
print('='*20, idx)
idx += 1
f1.close()
f2.close()
f3.close()
f4.close()
f5.close()
f6.close()
step2: 筛选不可转换的图片
import warnings
from PIL import Image
warnings.filterwarnings('error')
f1 = open('rgbaError.txt', 'w')
f2 = open('rgbaOK.txt', 'w')
with open('4chImg.txt', 'r')as f:
for i in f.readlines():
i = i.strip()
try:
img = Image.open(i).convert('RGB')
f2.write('{}\n'.format(i))
except Exception as e:
print('Error:', str(e))
print(i)
f1.write('{}\n'.format(i))
f1.close()
f2.close()
step3: 修改和再测试
import os
import piexif
import warnings
from PIL import Image
warnings.filterwarnings('error')
files = ['ExifError.txt', 'pExifError.txt']
for file in files:
with open(file, 'r')as f:
for i in f.readlines():
i = i.strip()
print(i.strip())
piexif.remove(i.strip())
# try:
# img = Image.open(i)
# except Exception as e:
# print('Error:', str(e))
# print(i)
2.划分数据集
个人习惯把路径存到txt再在dataset加载。
from sklearn.model_selection import train_test_split
import os
if __name__ == '__main__':
root = './train'
fpath = []
labels = []
for d in os.listdir(root):
fd = os.path.join(root, d)
label = int(d)
for i in os.listdir(fd):
fp = os.path.join(fd, i)
fpath.append(fp)
labels.append(label)
print(len(fpath), len(labels))
x_train, x_val, y_train, y_val = train_test_split(fpath, labels, random_state=999, test_size=0.2)
print(len(x_train), len(x_val))
with open('train.txt', 'w')as f:
for fn, l in zip(x_train, y_train):
f.write('{},{}\n'.format(fn, l))
with open('val.txt', 'w')as f:
for fn, l in zip(x_val, y_val):
f.write('{},{}\n'.format(fn, l))
3.预处理
原数据由于尺寸不一,多数是高清图片,训练时resize会很耗时,因此先resize到一个小尺寸保存起来。Image.thumbnail()可以起到过滤的作用,如果hw在范围内就不会resize,超过就会按比例放缩。图像质量和JPG压缩问题参考博客1,博客2。
import os
from PIL import Image
import cv2
import shutil
root = './train'
save_path = './thumbnail'
for r, d, files in os.walk(root):
if files != []:
for i in files:
fp = os.path.join(r, i)
label = i.split('_')[0]
dst = os.path.join(save_path, label)
if not os.path.exists(dst):
os.makedirs(dst)
img = Image.open(fp).convert('RGB')
w, h = img.size
if max(w, h) > 1080:
img.thumbnail((1080, 1080), Image.ANTIALIAS)
img.save(os.path.join(dst, i), quality=95, subsampling=0)
else:
shutil.copy(fp, os.path.join(dst, i))
处理前数据集大小为114G,处理后为86G。
在 Tesla V100 32GB*2 硬件环境下,训练Baseline,处理前训练时间一个epoch约为2400s(40min),处理后一个epoch约1400s(23min),极大缩小了训练时间,精度应该没有什么影响,调小判别尺寸应该还能更快,毕竟训练数据尺寸是224x224。
4.Baseline
# ls: labelsmooth
# cat: cat(gmp, gap)
{
model: resnet50,
pool: cat,
init_lr: 0.01,
schedule: cos(warm: 5),
epochs: <60,
loss: ls 0.2,
result: 41.497
}
{
model: resnext50,
pool: cat,
init_lr: 0.01,
shcedule: step(step: 8, gamma: 0.5),
epochs: 60,
loss: ls 0.2,
result: 42.748
}
关于数据增强,这里补充一下训练集的transform,图像size是224:
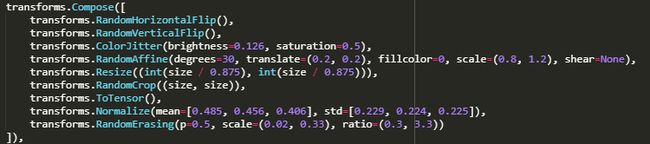
验证集只有resize和centercrop,测试时没有随机擦除,采用了5次TTA。
_(:з」∠)_佛系参赛,等大佬们分享高分solution。