机器学习及人工智能弹药库(更新中)
机器学习及人工智能弹药库(更新中)
祈福代码
# _ooOoo_
# o8888888o
# 88" . "88
# (| -_- |)
# O\ = /O
# ____/`---'\____
# .' \\| |// `.
# / \\||| : |||// \
# / _||||| -:- |||||- \
# | | \\\ - /// | |
# | \_| ''\---/'' | |
# \ .-\__ `-` ___/-. /
# ___`. .' /--.--\ `. . __
# ."" '< `.___\_<|>_/___.' >'"".
# | | : `- \`.;`\ _ /`;.`/ - ` : | |
# \ \ `-. \_ __\ /__ _/ .-` / /
# ======`-.____`-.___\_____/___.-`____.-'======
# `=---='
# ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
# Buddha Bless, No Bug !
一、导包
#忽略警告
import warnings
warnings.filterwarnings("ignore")
#导包
######################数据处理##########################
import numpy as np #数值计算
import pandas as pd #读取数据及分析
from sklearn.utils import shuffle #混洗数据
from sklearn.model_selection import KFold, cross_val_score as CVS, train_test_split as TTS #m
from tensorflow.keras.layers.experimental import preprocessing #tensorflow数据处理
import matplotlib.pyplot as plt #画图
import seaborn as sns #画图
########################模型##########################
from sklearn.ensemble import RandomForestClassifier as RFC #随机森林分类
from sklearn.svm import SVC #支持向量机分类
from sklearn.neighbors import KNeighborsClassifier as KNC #KNN分类
from xgboost import XGBClassifier as XGBC #XGBoost分类
import tensorflow as tf #tensorflow总
import tensorflow.keras as keras #keras模型
二、EDA(探索性数据分析)
1、数据描述
#数值型数据描述
train_data.describe().transpose()
#类别特征数据描述
"""
count:非空值数
unique:唯一值个数
top:频数最高
freq:最高频数
"""
def category_desc(dataframe):
cate_col = []
for col in dataframe.columns:
if dataframe[col].dtype == 'object':
cate_col.append(col)
print(col+"特征的唯一值有:")
print(dataframe[col].unique())
return dataframe[cate_col].describe()
category_desc(train_stores_oil_holiday_events_transactions)

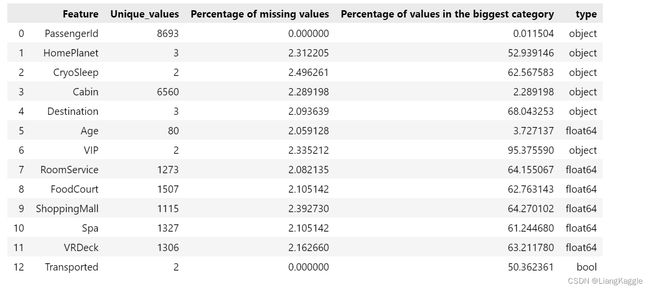
2、缺失值分析
#缺失值分析
def AnaNull(train_data):
stats = []
for col in train_data.columns:
stats.append((col,train_data[col].nunique(),
train_data[col].isnull().sum()*100/train_data.shape[0],
train_data[col].value_counts(normalize=True,
dropna=False).values[0]*100,
train_data[col].dtype))
stats_df = pd.DataFrame(stats,columns=['Feature','Unique_values',
'Percentage of missing values',
'Percentage of values in the biggest category','type'])
stats_df.sort_values('Percentage of missing values',ascending=False)[:10]
return stats_df
AnaNull(train_data)
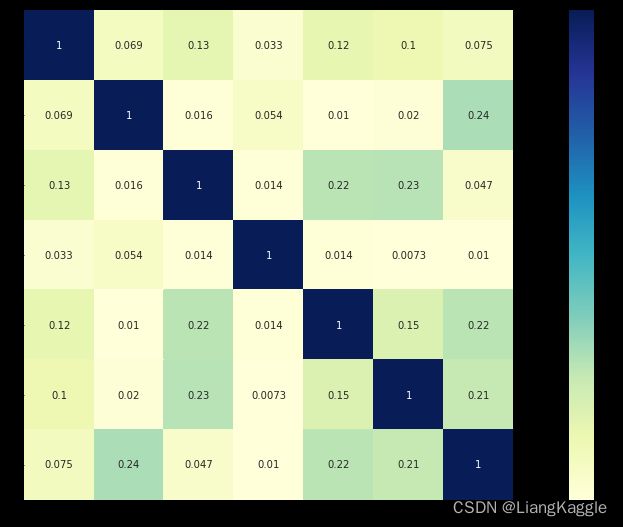
3、相关性分析
#观察相关性
corrmat = train_data.corr()
corrmat = abs(corrmat)
f,ax=plt.subplots(figsize=(20,9))
sns.heatmap(corrmat,vmax=0.8,square=True,cmap="YlGnBu",annot=True)
4、数值型变量分析
#查看数值型变量分布(直方图)
train_data.hist(bins=50,figsize=(20,15))
plt.show()
#查看数值型变量分布(数数图)
plt.figure(figsize=(20,4))
sns.countplot(data=train_data, x='xxx', hue='xxx')
plt.title('XXX')
#查看数值型变量分布(箱型图)
sns.set_theme(style="whitegrid")
expenditure_columns = ['RoomService','FoodCourt','ShoppingMall','Spa','VRDeck']
sns.boxplot(data=train_data[expenditure_columns], orient="h", palette="Set2")
二 、特征工程
1、数据预处理
① 缺失值处理
#处理缺失值
def dealNull(train_data):
for col in train_data.columns:
if (train_data[col].dtype == 'object'):
#类别特征填充众数
train_data[col].fillna(train_data[col].mode()[0],inplace=True)
else:
#数值及其他填充众数
train_data[col].fillna(train_data[col].mode()[0],inplace=True)
dealNull(train_data)
② 异常值处理
#1、寻找异常值(箱型图)
fig,ax=plt.subplots(3,2,figsize=(20,20))
ax[0,0].boxplot(train_data[["Age"]])
ax[0,1].boxplot(train_data[["RoomService"]])
ax[1,0].boxplot(train_data[["FoodCourt"]])
ax[1,1].boxplot(train_data[["ShoppingMall"]])
ax[2,0].boxplot(train_data[["Spa"]])
ax[2,1].boxplot(train_data[["VRDeck"]])
2、特征变换
① 独热编码
enc = OneHotEncoder(categories='auto')
#toarray必须要
train_data_encoder = enc.fit_transform(train_data[['HomePlanet','Destination','Cabin1','Cabin2','Cabin3']]).toarray()
x1 = pd.DataFrame(train_data_encoder,columns=enc.get_feature_names_out())
#拼接数据
xtrain_data = pd.concat([x1,train_data[["Age","RoomService","FoodCourt","ShoppingMall","Spa","VRDeck","CryoSleep",'VIP'
,"Transported"]]],axis=1)
xtrain_data
② 自然数编码
def LabelEnco(data):
for f in ['Cabin1','Cabin2','Cabin3']:
data[f] = data[f].fillna(-999)
data[f] = data[f].map(dict(zip(data[f].unique(),range(0,data[f].nunique()))))
OneLabelEncod(train_data)
③ 特征离散化
#特征分箱(等宽分箱)
bins=[0,10,20,30,40,50,60,70,80,90,100]
train_data['Age'] = pd.cut(train_data['Age'], bins, labels=['A','B','C','D','E','F','G','H','I','J'])
train_data['Age']
3、特征提取
① 特征组合
#特征组合
from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures(2,interaction_only=True)
new_feature = poly.fit_transform(xtrain_data[['HomePlanet_Earth', 'HomePlanet_Europa', 'HomePlanet_Mars',
'Destination_55 Cancri e', 'Destination_PSO J318.5-22',
'Destination_TRAPPIST-1e',
'Cabin1', 'Cabin2', 'Cabin3']])
poly.get_feature_names_out()
4、特征选择
① 皮尔逊相关系数计算筛选特征
"""
train:训练数据
features:特征名列表
label:标签名
fea_num:返回的特征个数
"""
def feature_select_person(train,features,label,fea_num):
featureSelect = features[:]
corr = []
for feat in featureSelect:
corr.append(abs(train[[feat,label]].fillna(0).corr().values[0][1]))
se = pd.Series(corr,index=featureSelect).sort_values(ascending=False)
feature_select = se[:fea_num].index.tolist()
#返回特征选择后的训练集
return train[feature_select]
#函数调用
xtrain = feature_select_person(xtrain_data,xtrain_data.columns,'Transported',20)
三、模型构建
1、scikit-learn
① 实例化
#以KNN为例
knc = KNC()
knc.fit(Xtrain,Ytrain)
knc.score(Xtest,Ytest)
2、XGBoost
sklearn接口实现
① 实例化
#XGBoost分类
xgbc = XGBC(max_depth=4,n_estimators=14)
xgbc.fit(Xtrain,Ytrain)
score = xgbc.score(Xtest,Ytest)
XGBoost本身接口实现
① 实例化
params = {'eta':0.01,'max_depth':5,'objective':'binary:logistic','eval_metric':['logloss','auc']}
num_round = 200000
dtrain = xgb.DMatrix(data=Xtrain,label=Ytrain)
dtest = xgb.DMatrix(data=Xtest,label=Ytest)
evallist = [(dtest,'eval'),(dtrain,'train')]
model=xgb.train(params, dtrain, num_round, evallist,early_stopping_rounds=10)
3、CatBoost
#catboost
from catboost import CatBoostClassifier
params={'learning_rate':0.02,'depth':13,'random_seed':42}
model = CatBoostClassifier(iterations=20,eval_metric='Logloss',**params)
model.fit(Xtrain,Ytrain,cat_features=['HomePlanet','Destination','Destination','Cabin1','Cabin3'],use_best_model=True,verbose=False)
print("Accuracy Score: ",accuracy_score(Ytest, model.predict(Xtest).astype(bool)))
4、LightGBM
#lgb分类
#data
train_data = lgb.Dataset(Xtrain, label=Ytrain)
validation_data = lgb.Dataset(Xtest, label=Ytest)
#parameters
param = {'num_leaves': 31, 'objective': 'binary','metric':['auc', 'binary_logloss','cross_entropy']}
num_round = 10
bst = lgb.train(param, train_data, num_round, valid_sets=[validation_data])
y = bst.predict(Xtest)
y = y>0.5
print("Accuracy Score: ",accuracy_score(Ytest, y))
5、DeepLearning
① 归一化
#归一化
def deal_Scaler(data):
scaler = prep.MinMaxScaler()
scaler = scaler.fit(data) # 本质生成 max(x) 和 min(x)
result = scaler.transform(data)
return result
② tensorboard准备
#tensorboard准备
import os
root_logdir = os.path.join(os.curdir,"my_logs")
def get_run_logdir():
import time
run_id = time.strftime("run_%Y_%m_%d-%H_%M_%S")
return os.path.join(root_logdir,run_id)
打开TensorBoard
1、进入到my_logs文件夹的上级文件夹。
2、输入如下命令(windows)
tensorboard --logdir=./my_logs --port=6006
③ 模型构建(函数式模型)
#构建模型
input_ = keras.layers.Input(shape=Xtrain.shape[1:])
hidden1 = keras.layers.Dense(100,activation="relu")(input_)
hidden1 = tf.keras.layers.Dropout(0.5)(hidden1)
hidden2 = keras.layers.Dense(50,activation="relu")(hidden1)
output = keras.layers.Dense(2,activation="sigmoid")(hidden2)
model = keras.Model(inputs=[input_],outputs=[output])
model.compile(loss="binary_crossentropy",optimizer="sgd",metrics=["accuracy"])
run_logdir = get_run_logdir()
tensorboard_cb = keras.callbacks.TensorBoard(run_logdir)
model.summary()
# rankdir='LR' is used to make the graph horizontal.
tf.keras.utils.plot_model(model, show_shapes=True)
④ 模型拟合评估
history = model.fit(Xtrain,Ytrain,epochs=30,
validation_data=(Xvali,Yvali),
callbacks=[tensorboard_cb])
mse_test = model.evaluate(Xtest,Ytest)
print(mse_test)
6、CNN(卷积神经网络)
① LeNet-5
#LeNet-5
model = keras.models.Sequential([
keras.layers.Input(shape=[28,28,1]),
keras.layers.Conv2D(6,5,activation="relu",padding="same"),
keras.layers.MaxPool2D(2,strides=2),
keras.layers.Conv2D(16,5,activation="relu",padding="valid"),
keras.layers.MaxPool2D(2,strides=2),
keras.layers.Conv2D(120,5,activation="relu",padding="valid"),
keras.layers.Flatten(),
keras.layers.Dense(80,activation="relu"),
keras.layers.Dense(10,activation="softmax")
])
model.compile(optimizer='adam',
loss='categorical_crossentropy',metrics=["accuracy"])
run_logdir = get_run_logdir()
tensorboard_cb = keras.callbacks.TensorBoard(run_logdir)
model.summary()
# rankdir='LR' is used to make the graph horizontal.
tf.keras.utils.plot_model(model, show_shapes=True)
② ResNet-34(未验证)
#ResNet-34
import tensorflow.keras as keras
class ResidualUnit(keras.layers.Layer):
def _init_(self,filters,strides=1,activation="relu",**kwargs):
super()._init_(**kwargs)
self.activation = keras.activations.get(activation)
self.main_layers = [
keras.layers.Conv2D(filters,3,strides=strides,
padding="same",use_bias=False),
keras.layers.BatchNormalization(),
self.activation,
keras.layers.Conv2D(filters,3,strides=1,
padding="same",use_bias=False),
keras.layers.BatchNormalization()]
self.skip_layers = []
if strides > 1:
self.skip_layers = [
keras.layers.Conv2D(filters,1,strides=strides,
padding="same",use_bias=Fase),
keras.layers.BatchNormalizaion()]
def call(self,inputs):
Z = inputs
for layer in self.main_layers:
Z = layer(Z)
skip_Z = inputs
for layer in self.skip_layers:
skip_Z = layer(skip_Z)
return self.activation(Z+skip_Z)
6、YOLO
此段借助
1、博客文章:http://t.csdn.cn/d7Sp6博客文章(部分代码修改)
2、YOLO参考网站:https://pjreddie.com/darknet/yolov2/
3、吴恩达车辆识别编程作业(部分代码修改)。
4、问题解决:https://www.cnblogs.com/pengzhi12345/p/11900994.html、http://t.csdn.cn/Ko5AV
相关包导入
import argparse
import os
import matplotlib.pyplot as plt
from matplotlib.pyplot import imshow
import scipy.io
import scipy.misc
import numpy as np
import pandas as pd
import PIL
import tensorflow as tf
from keras import backend as K
from keras.layers import Input, Lambda, Conv2D
from keras.models import load_model, Model
from yolo_utils import read_classes, read_anchors, generate_colors, preprocess_image, draw_boxes, scale_boxes
from yad2k.models.keras_yolo import yolo_head, yolo_boxes_to_corners, preprocess_true_boxes, yolo_loss, yolo_body
import yolo_utils
import imageio
%matplotlib inline
tf.compat.v1.disable_eager_execution()
① 构建分类阈值过滤函数
def yolo_filter_boxes(box_confidence , boxes, box_class_probs, threshold = 0.6):
"""
通过阈值来过滤对象和分类的置信度。
参数:
box_confidence - tensor类型,维度为(19,19,5,1),包含19x19单元格中每个单元格预测的5个锚框中的所有的锚框的pc (一些对象的置信概率)。
boxes - tensor类型,维度为(19,19,5,4),包含了所有的锚框的(px,py,ph,pw )。
box_class_probs - tensor类型,维度为(19,19,5,80),包含了所有单元格中所有锚框的所有对象( c1,c2,c3,···,c80 )检测的概率。
threshold - 实数,阈值,如果分类预测的概率高于它,那么这个分类预测的概率就会被保留。
返回:
scores - tensor 类型,维度为(None,),包含了保留了的锚框的分类概率。
boxes - tensor 类型,维度为(None,4),包含了保留了的锚框的(b_x, b_y, b_h, b_w)
classess - tensor 类型,维度为(None,),包含了保留了的锚框的索引
注意:"None"是因为你不知道所选框的确切数量,因为它取决于阈值。
比如:如果有10个锚框,scores的实际输出大小将是(10,)
"""
#第一步:计算锚框的得分
box_scores = box_confidence * box_class_probs
#第二步:找到最大值的锚框的索引以及对应的最大值的锚框的分数
box_classes = K.argmax(box_scores, axis=-1)
box_class_scores = K.max(box_scores, axis=-1)
#第三步:根据阈值创建掩码
filtering_mask = (box_class_scores >= threshold)
#对scores, boxes 以及 classes使用掩码
scores = tf.boolean_mask(box_class_scores,filtering_mask)
boxes = tf.boolean_mask(boxes,filtering_mask)
classes = tf.boolean_mask(box_classes,filtering_mask)
return scores , boxes , classes
② 构建IOU计算函数
def iou(box1, box2):
"""
实现两个锚框的交并比的计算
参数:
box1 - 第一个锚框,元组类型,(x1, y1, x2, y2)
box2 - 第二个锚框,元组类型,(x1, y1, x2, y2)
返回:
iou - 实数,交并比。
"""
#计算相交的区域的面积
xi1 = np.maximum(box1[0], box2[0])
yi1 = np.maximum(box1[1], box2[1])
xi2 = np.minimum(box1[2], box2[2])
yi2 = np.minimum(box1[3], box2[3])
inter_area = (xi1-xi2)*(yi1-yi2)
#计算并集,公式为:Union(A,B) = A + B - Inter(A,B)
box1_area = (box1[2]-box1[0])*(box1[3]-box1[1])
box2_area = (box2[2]-box2[0])*(box2[3]-box2[1])
union_area = box1_area + box2_area - inter_area
#计算交并比
iou = inter_area / union_area
return iou
③ 实现非最大值抑制函数
def yolo_non_max_suppression(scores, boxes, classes, max_boxes=10, iou_threshold=0.5):
"""
为锚框实现非最大值抑制( Non-max suppression (NMS))
参数:
scores - tensor类型,维度为(None,),yolo_filter_boxes()的输出
boxes - tensor类型,维度为(None,4),yolo_filter_boxes()的输出,已缩放到图像大小(见下文)
classes - tensor类型,维度为(None,),yolo_filter_boxes()的输出
max_boxes - 整数,预测的锚框数量的最大值
iou_threshold - 实数,交并比阈值。
返回:
scores - tensor类型,维度为(,None),每个锚框的预测的可能值
boxes - tensor类型,维度为(4,None),预测的锚框的坐标
classes - tensor类型,维度为(,None),每个锚框的预测的分类
注意:"None"是明显小于max_boxes的,这个函数也会改变scores、boxes、classes的维度,这会为下一步操作提供方便。
"""
max_boxes_tensor = K.variable(max_boxes,dtype="int32") #用于tf.image.non_max_suppression()
K.get_session().run(tf.compat.v1.variables_initializer([max_boxes_tensor])) #初始化变量max_boxes_tensor
#使用使用tf.image.non_max_suppression()来获取与我们保留的框相对应的索引列表
nms_indices = tf.image.non_max_suppression(boxes, scores,max_boxes,iou_threshold)
#使用K.gather()来选择保留的锚框
scores = K.gather(scores, nms_indices)
boxes = K.gather(boxes, nms_indices)
classes = K.gather(classes, nms_indices)
return scores, boxes, classes
④ 对所有框进行过滤
def yolo_eval(yolo_outputs, image_shape=(720.,1280.),
max_boxes=10, score_threshold=0.6,iou_threshold=0.5):
"""
将YOLO编码的输出(很多锚框)转换为预测框以及它们的分数,框坐标和类。
参数:
yolo_outputs - 编码模型的输出(对于维度为(608,608,3)的图片),包含4个tensors类型的变量:
box_confidence : tensor类型,维度为(None, 19, 19, 5, 1)
box_xy : tensor类型,维度为(None, 19, 19, 5, 2)
box_wh : tensor类型,维度为(None, 19, 19, 5, 2)
box_class_probs: tensor类型,维度为(None, 19, 19, 5, 80)
image_shape - tensor类型,维度为(2,),包含了输入的图像的维度,这里是(608.,608.)
max_boxes - 整数,预测的锚框数量的最大值
score_threshold - 实数,可能性阈值。
iou_threshold - 实数,交并比阈值。
返回:
scores - tensor类型,维度为(,None),每个锚框的预测的可能值
boxes - tensor类型,维度为(4,None),预测的锚框的坐标
classes - tensor类型,维度为(,None),每个锚框的预测的分类
"""
#获取YOLO模型的输出
box_confidence, box_xy, box_wh, box_class_probs = yolo_outputs
#中心点转换为边角
boxes = yolo_boxes_to_corners(box_xy,box_wh)
#可信度分值过滤
scores, boxes, classes = yolo_filter_boxes(box_confidence, boxes, box_class_probs, score_threshold)
#缩放锚框,以适应原始图像
boxes = yolo_utils.scale_boxes(boxes, image_shape)
#使用非最大值抑制
scores, boxes, classes = yolo_non_max_suppression(scores, boxes, classes, max_boxes, iou_threshold)
return scores, boxes, classes
⑤ 测试已经训练好的YOLO
#1、启动计算图
sess = K.get_session()
#2、定义分类、锚框和图像维度
class_names = yolo_utils.read_classes("model_data/coco_classes.txt")
anchors = yolo_utils.read_anchors("model_data/yolo_anchors.txt")
image_shape = (720.,1280.)
#3、加载已经训练好的模型
yolo_model = load_model("model_data/yolov2.h5")
#4、将模型的输出转换为边界框
yolo_outputs = yolo_head(yolo_model,output, anchors, len(class_names))
#5、过滤锚框
scores, boxes, classes = yolo_eval(yolo_outputs, image_shape)
#6、在实际图像中运行计算图(在整体流程中可舍弃)
image, image_data = yolo_utils.preprocess_image("images/" + image_file, model_image_size = (608, 608))
⑥ 构建预测函数
def predict(sess, image_file, is_show_info=True, is_plot=True):
"""
运行存储在sess的计算图以预测image_file的边界框,打印出预测的图与信息。
参数:
sess - 包含了YOLO计算图的TensorFlow/Keras的会话。
image_file - 存储在images文件夹下的图片名称
返回:
out_scores - tensor类型,维度为(None,),锚框的预测的可能值。
out_boxes - tensor类型,维度为(None,4),包含了锚框位置信息。
out_classes - tensor类型,维度为(None,),锚框的预测的分类索引。
"""
#图像预处理
image, image_data = yolo_utils.preprocess_image("images/" + image_file, model_image_size = (608, 608))
#运行会话并在feed_dict中选择正确的占位符.
out_scores, out_boxes, out_classes = sess.run([scores, boxes, classes], feed_dict = {yolo_model.input:image_data, K.learning_phase(): 0})
#打印预测信息
if is_show_info:
print("在" + str(image_file) + "中找到了" + str(len(out_boxes)) + "个锚框。")
#指定要绘制的边界框的颜色
colors = yolo_utils.generate_colors(class_names)
#在图中绘制边界框
yolo_utils.draw_boxes(image, out_scores, out_boxes, out_classes, class_names, colors)
#保存已经绘制了边界框的图
image.save(os.path.join("out", image_file), quality=100)
#打印出已经绘制了边界框的图
if is_plot:
output_image = imageio.imread(os.path.join("out", image_file))
plt.imshow(output_image)
return out_scores, out_boxes, out_classes
⑦ 实际预测
out_scores, out_boxes, out_classes = predict(sess, "test.jpg")

四、模型评估
1、回归
① 混淆矩阵
from sklearn.metrics import confusion_matrix
confusion_matrix(y_train, y_train_pred)
② 召回率,查准率,F1-score,查全率
from sklearn.metrics import precision_score, recall_score,f1_score,accuracy_score
print("Precision Score: ",precision_score(y_train, y_train_pred))
print("Recall Score: ",recall_score(y_train, y_train_pred))
print("F1 Score: ",f1_score(y_train, y_train_pred))
print("Accuracy Score: ",accuracy_score(y_train, y_train_pred))