win10(GetForce GTX 1650 Ti)+cuda11.0.228+cudnn-x64-v8.0.2.39+Tensorflow-gpu2.4.1+Pytorch1.8.1(五)
本文讲在cuda11.0.228+cudnn-x64-v8.0.2.39环境下,利用anaconda安装pytorch。
pytorch相较于tf要简单很多。
首先,按照之前的教程
create一个pytorch_env环境,然后选择python3.8。在jupter lab上启动这个环境,然后准备安装pytorch.
接着,找到Pytorch的下载官网:https://pytorch.org/get-started/locally/
在这里选择,你的版本:

这里有一个问题在于:pytorch在这里面没有cuda11.0对应的版本,当时查了很多资料,说pytorch不支持cuda11.0,只能卸载11.0换成10.0,这无疑是麻烦的,后来看一些评论,说pytorch已经支持cuda11.0还有一些官网截图,然鹅,我并没有在torch的官网中找到下载地址==。然后我就本着下低不下高的原则,尝试安装了如图中的cuda10.2版本的Pytorch,神奇的是成功了。
也就是,复制下面的command命令:
pip install torch==1.8.1+cu102 torchvision==0.9.1+cu102 torchaudio===0.8.1 -f https://download.pytorch.org/whl/torch_stable.html
然后在刚才创建的环境下进行安装,很顺利就安装完毕了。
测试1
# Summary:PyTorch的Tensor基础知识
# Author: Amusi
# Date: 2018-12-20
# github: https://github.com/amusi/PyTorch-From-Zero-To-One
# Reference: http://pytorch.org/tutorials/beginner/pytorch_with_examples.html#pytorch-tensors
import torch
dtype = torch.FloatTensor
# dtype = torch.cuda.FloatTensor # Uncomment this to run on GPU
# N is batch size; D_in is input dimension;
# H is hidden dimension; D_out is output dimension.
N, D_in, H, D_out = 64, 1000, 100, 10
# Create random input and output data
x = torch.randn(N, D_in).type(dtype)
y = torch.randn(N, D_out).type(dtype)
# Randomly initialize weights
w1 = torch.randn(D_in, H).type(dtype)
w2 = torch.randn(H, D_out).type(dtype)
learning_rate = 1e-6
for t in range(500):
# Forward pass: compute predicted y
h = x.mm(w1)
h_relu = h.clamp(min=0)
y_pred = h_relu.mm(w2)
# Compute and print loss
loss = (y_pred - y).pow(2).sum()
print(t, loss)
# Backprop to compute gradients of w1 and w2 with respect to loss
grad_y_pred = 2.0 * (y_pred - y)
grad_w2 = h_relu.t().mm(grad_y_pred)
grad_h_relu = grad_y_pred.mm(w2.t())
grad_h = grad_h_relu.clone()
grad_h[h < 0] = 0
grad_w1 = x.t().mm(grad_h)
# Update weights using gradient descent
w1 -= learning_rate * grad_w1
w2 -= learning_rate * grad_w2
输出:
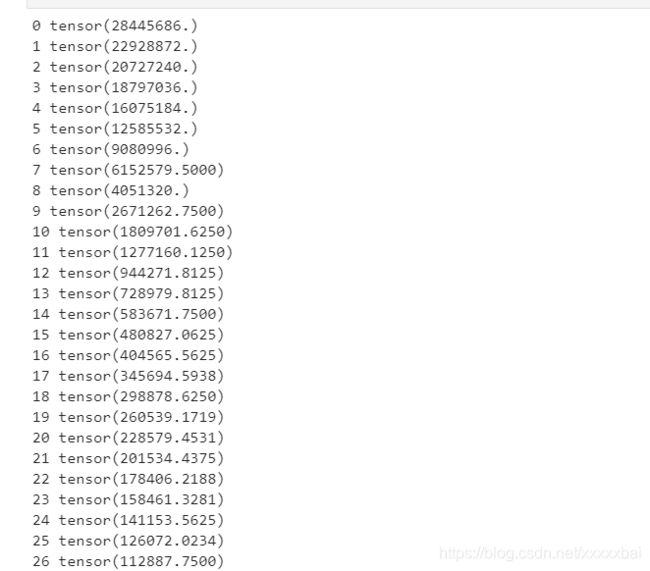
测试2:
import torch
from torch.autograd import Variable
import numpy as np
from torch import nn, optim
import matplotlib.pyplot as plt
x_train = np.array([[3.3], [4.4], [5.5], [6.71], [6.93], [4.168],
[9.779], [6.182], [7.59], [2.167], [7.042],
[10.791], [5.313], [7.997], [3.1]], dtype=np.float32)
y_train = np.array([[1.7], [2.76], [2.09], [3.19], [1.694], [1.573],
[3.366], [2.596], [2.53], [1.221], [2.827],
[3.465], [1.65], [2.904], [1.3]], dtype=np.float32)
plt.plot(x_train,y_train,"ro") #show for test
plt.show()
x_train = torch.from_numpy(x_train) #cover the numpy array to tensor
y_train = torch.from_numpy(y_train)
class LinearRegression(nn.Module): #define a LinearRegression module
def __init__(self):
super(LinearRegression, self).__init__()
self.linear = nn.Linear(1, 1) # input and output is 1 dimension
def forward(self, x):
out = self.linear(x)
return out
model = LinearRegression() #setting the modle to system
criterion = nn.MSELoss() #setting loss function
optimizer = optim.SGD(model.parameters(), lr=1e-4) #choic an optimizer
num_epochs = 1000
for epoch in range(num_epochs):
inputs = Variable(x_train)
target = Variable(y_train)
# forward
out = model(inputs) # 前向传播
loss = criterion(out, target) # 计算loss
# backward
optimizer.zero_grad() # 梯度归零
loss.backward() # 反向传播
optimizer.step() # 更新参数
if (epoch ) % 20 == 0:
print('Epoch[{}/{}], loss: {:.2f}'.format(epoch , num_epochs, loss.item()))
【这里可能需要先:pip install matplotlib】
输出:
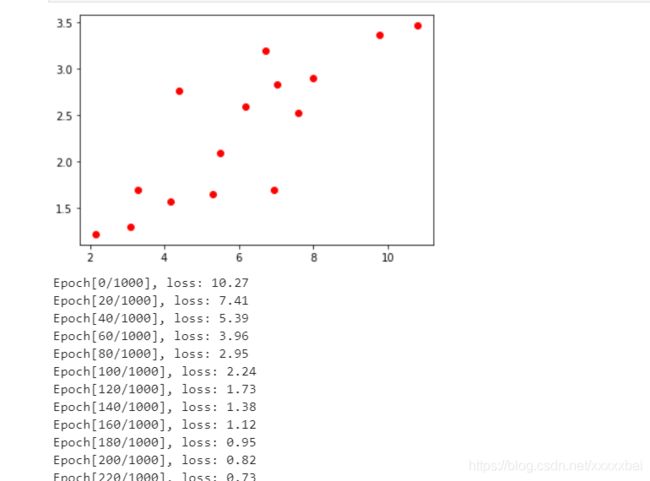
测试3:
# Summary: 使用PyTorch玩转MNIST
# Author: Amusi
# Date: 2018-12-20
# github: https://github.com/amusi/PyTorch-From-Zero-To-One
# Reference: https://blog.csdn.net/victoriaw/article/details/72354307
from __future__ import print_function
import argparse
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.autograd import Variable
# Training settings
parser = argparse.ArgumentParser(description='PyTorch MNIST Example')
parser.add_argument('--batch-size', type=int, default=64, metavar='N',
help='input batch size for training (default: 64)')
parser.add_argument('--test-batch-size', type=int, default=1000, metavar='N',
help='input batch size for testing (default: 1000)')
parser.add_argument('--epochs', type=int, default=10, metavar='N',
help='number of epochs to train (default: 10)')
parser.add_argument('--lr', type=float, default=0.01, metavar='LR',
help='learning rate (default: 0.01)')
parser.add_argument('--momentum', type=float, default=0.5, metavar='M',
help='SGD momentum (default: 0.5)')
parser.add_argument('--no-cuda', action='store_true', default=False,
help='disables CUDA training')
parser.add_argument('--seed', type=int, default=1, metavar='S',
help='random seed (default: 1)')
parser.add_argument('--log-interval', type=int, default=10, metavar='N',
help='how many batches to wait before logging training status')
args = parser.parse_args(args=[])
args.cuda = not args.no_cuda and torch.cuda.is_available()
torch.manual_seed(args.seed) #为CPU设置种子用于生成随机数,以使得结果是确定的
if args.cuda:
torch.cuda.manual_seed(args.seed)#为当前GPU设置随机种子;如果使用多个GPU,应该使用torch.cuda.manual_seed_all()为所有的GPU设置种子。
kwargs = {'num_workers': 1, 'pin_memory': True} if args.cuda else {}
"""加载数据。组合数据集和采样器,提供数据上的单或多进程迭代器
参数:
dataset:Dataset类型,从其中加载数据
batch_size:int,可选。每个batch加载多少样本
shuffle:bool,可选。为True时表示每个epoch都对数据进行洗牌
sampler:Sampler,可选。从数据集中采样样本的方法。
num_workers:int,可选。加载数据时使用多少子进程。默认值为0,表示在主进程中加载数据。
collate_fn:callable,可选。
pin_memory:bool,可选
drop_last:bool,可选。True表示如果最后剩下不完全的batch,丢弃。False表示不丢弃。
"""
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=args.batch_size, shuffle=True, **kwargs)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=args.batch_size, shuffle=True, **kwargs)
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)#输入和输出通道数分别为1和10
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)#输入和输出通道数分别为10和20
self.conv2_drop = nn.Dropout2d()#随机选择输入的信道,将其设为0
self.fc1 = nn.Linear(320, 50)#输入的向量大小和输出的大小分别为320和50
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))#conv->max_pool->relu
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))#conv->dropout->max_pool->relu
x = x.view(-1, 320)
x = F.relu(self.fc1(x))#fc->relu
x = F.dropout(x, training=self.training)#dropout
x = self.fc2(x)
return F.log_softmax(x)
model = Net()
if args.cuda:
model.cuda()#将所有的模型参数移动到GPU上
optimizer = optim.SGD(model.parameters(), lr=args.lr, momentum=args.momentum)
def train(epoch):
model.train()#把module设成training模式,对Dropout和BatchNorm有影响
for batch_idx, (data, target) in enumerate(train_loader):
if args.cuda:
data, target = data.cuda(), target.cuda()
data, target = Variable(data), Variable(target)#Variable类对Tensor对象进行封装,会保存该张量对应的梯度,以及对生成该张量的函数grad_fn的一个引用。如果该张量是用户创建的,grad_fn是None,称这样的Variable为叶子Variable。
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)#负log似然损失
loss.backward()
optimizer.step()
if batch_idx % args.log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
def test(epoch):
model.eval()#把module设置为评估模式,只对Dropout和BatchNorm模块有影响
test_loss = 0
correct = 0
for data, target in test_loader:
if args.cuda:
data, target = data.cuda(), target.cuda()
data, target = Variable(data, volatile=True), Variable(target)
output = model(data)
test_loss += F.nll_loss(output, target).item()#Variable.data
pred = output.data.max(1)[1] # get the index of the max log-probability
correct += pred.eq(target.data).cpu().sum()
test_loss = test_loss
test_loss /= len(test_loader) # loss function already averages over batch size
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
if __name__ == '__main__':
for epoch in range(1, args.epochs + 1):
train(epoch)
test(epoch)
这个MNIST当时测试,出了很多问题:
1.An exception has occurred, use %tb to see the full traceback.SystemExit:2
原有代码里:
args = parser.parse_args()
需要改正为:
args = parser.parse_args(args=[])
(上面代码里是改过的)
2…/data一直下载失败:PermissionError: [WinError 5] 拒绝访问。: ‘…/data’
方法:https://blog.csdn.net/weixin_43870646/article/details/90020874
感觉这个问题也有可能是网络的原因,而非权限,因为当时安装这个教程改动后仍然不行,后来就是按照上篇把cudnn配件加进去之后,这个问题也莫名就解决了。
这也有自己下载数据集的方法:https://blog.csdn.net/qq_41528502/article/details/105948284
这里写个题外话,就是之前我们配置了很多环境变量,一定记住配置之后,cmd窗口是需要重新进入的,不然新配置的是不会自动应用在原来的cmd上。
‘测试3运行完之后:
中间写红了点,应该是连接的问题。

测试4:
# Summary: 检测当前Pytorch和设备是否支持CUDA和cudnn
# Author: Amusi
# Date: 2018-12-20
# github: https://github.com/amusi/PyTorch-From-Zero-To-One
import torch
if __name__ == '__main__':
print("Support CUDA ?: ", torch.cuda.is_available())
x = torch.Tensor([1.0])
xx = x.cuda()
print(xx)
y = torch.randn(2, 3)
yy = y.cuda()
print(yy)
zz = xx + yy
print(zz)
# CUDNN TEST
from torch.backends import cudnn
print("Support cudnn ?: ",cudnn.is_acceptable(xx))
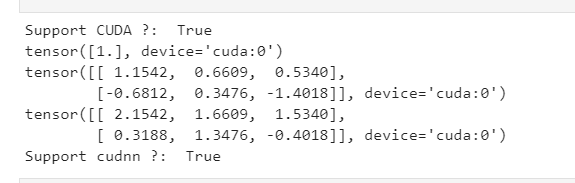
测试5:是否使用Gpu(也可以通过gpu指令里查看process)
#检测pytorch是否使用gpu
import torch
flag = torch.cuda.is_available()
print(flag)
ngpu= 1
# Decide which device we want to run on
device = torch.device("cuda:0" if (torch.cuda.is_available() and ngpu > 0) else "cpu")
print(device)
print(torch.cuda.get_device_name(0))
print(torch.rand(3,3).cuda())
其实到这里pytorch就安装成功啦~~
-------手动分割线---------
后来,我还有一点error在于,我也忘记我为啥要在pytorch环境下,运行mxnet案例,代码如下:
from mxnet import autograd, gluon, np, npx
from d2l import mxnet as d2l
npx.set_np()
true_w = np.array([2, -3.4])
true_b = 4.2
features, labels = d2l.synthetic_data(true_w, true_b, 1000)
发现一直出错,先是安装Mxnet发现,在启动Numpy时出错,说我的numpy库版本需要升级,然后升级之后,仍然启动不起来。按照教程:
pip install --ignore-installed numpy --user
(也有说,pip install mxnet的时候需要先卸载numpy)
后来慢慢明白为啥一直出错了,应该是因为pytorch里也依赖numpy库,而他的版本和Mxnet依赖的Numpy版本冲突,所以一直失败,推测如果再create一个新环境去装mxnet就可以了把,但是这个我还没用过,只是推断。
(安装Numpy的时候其实也是有坑的,建议搜索一下教程再安装)