1、聚类算法的目的是采集数据,然后从中找出不同的群组。
2、Universal Feed Parser
可以方便地解析RSS订阅源,即从RSS或Atom订阅源中得到标题、链接和文章的内容。
3、皮尔逊相关度其实判断的是两组数据与某条直线的拟合程度,当两者完全匹配时,计算结果为1.0,当两者毫无关系时,计算结果为0.0.
4、分级聚类
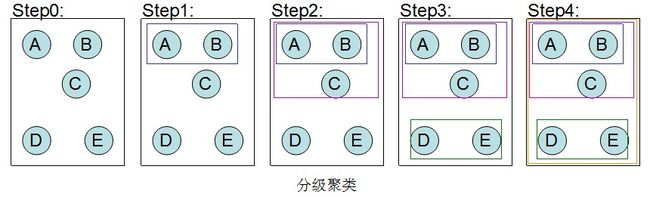
分级聚类的结果会产生一棵树:
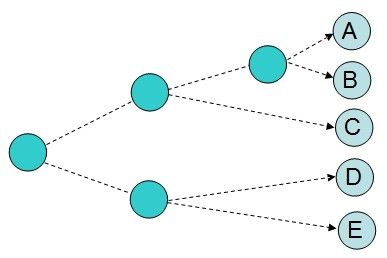
分级聚类虽然会返回一棵形象直观的树,但这种方法有两个缺点。在没有额外指定的情况下,树形视图不会真正将数据拆分成不同的组,而且该算法的计算量惊人。因为我们必须计算每两个数据项之间的关系,并且在合并项之后这些关系还得再计算,所以在处理大规模的数据集时,该算法的运行速度会非常缓慢。
5、K-均值聚类
(会预先告诉算法希望聚成几类)
K-均值聚类算法首先会随机确定k个中心位置,然后将各个数据项分配给最临近的中心点。待分配完成后,聚类中心会移动到分配给该聚类的所有节点的平均位置处,然后整个分配过程重新开始。这一过程会一直重复下去,知道分配过程不再产生变化为止。
例如5个数据项的2个聚类:
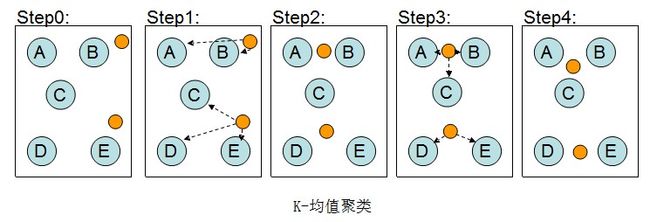
K-均值聚类的计算效率会比分级聚类快一些,但是k值的选取会影响聚类的效果。
6、Beautiful Soup
是一个解析网页和构造结构化数据表达形式的优秀函数库。它允许我们利用类型(type)、id或者任何属性来访问网页的任何元素。它可以很好的处理包含不规范HTML标记的web页面,当我们根据站点的内容来构造数据集时,这一点非常有用。
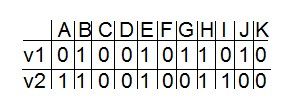
7、Tanimoto系数
Tanimoto coefficient,它代表的是交集(两个集合中均出现的项)与并集(两个集合中只要有一次出现即可)的比率。
这个系数很容易计算:
def tanimoto(v1,v2) c1,c2,shr = 0,0,0 for i in range(len(v1)) if v1[i] != 0 : c1 += 1; #出现在v1中 if v2[i] != 0 : c2 += 1; #出现在v2中 if v1[i] != 0 and v2[i] != 0 : shr += 1; #在v1和v2中都出现了 return 1.0 - (float(shr)/(c1+c2-shr))
数据格式为:
8、多维缩放(multidimentional scaling)技术
其目标是尝试绘制出一幅图来,图中各数据项之间的距离远近对应于它们彼此之间的差异程度。为了做到这一点,算法首先需要计算出所有项之间的目标距离。
step1:距离信息矩阵(目标距离)
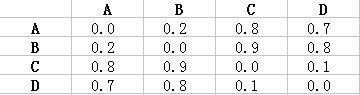
step2:将所有数据项随机放置在二维图上
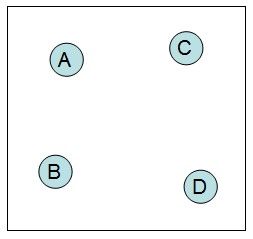
step3:计算各项数据之间的实际距离(当前距离)
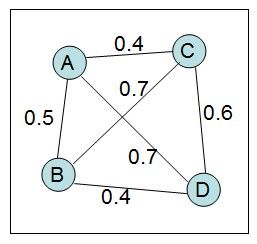
step4:对数据项施力,将它推向目标距离
如A,它与B之间的目标距离为0.2,而实际距离为0.4,因此应该将A推向B。同理,应将A远离C和D
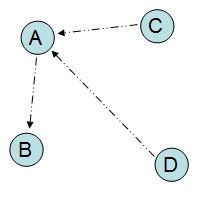
每一个节点的移动,都是所有其他节点施加在该节点上的推或拉的综合效应。节点每移动一次,其当前距离和目标距离之间的差距就会减小一些。这一过程会不断的重复多次,直到我们无法再通过移动节点来减少总体的误差为止。