【python文本分析】——基于股评文本的情绪分析
目录
- 一、文本处理
-
- 1、精确模式(默认)
- 2、全模式
- 3、搜索引擎模式
- 二、词云图
-
- 1、wordcloud模块导入
- 2、词云图实现
- 三、实例——利用股评进行情绪分析
-
- 1、数据来源及snownlp模块导入
- 2、代码实现
-
- 2.1、读取股评文件
- 2.2、处理数据
- 2.3、计算情绪指数
- 2.4、计算每日情绪均值
- 2.5、获取股票数据
- 2.6、计算股票涨跌幅
- 2.7、数据再处理
- 2.8、数据合并
- 2.9、数据可视化
- 3、结果分析
-
- 3.1、折线图
- 3.2、词云图
- 结语
一、文本处理
中文分词是中文文本处理的一个基础步骤。jieba分词工具是最常见的语言分词工具:
import jieba
import jieba.posseg as psg
from collections import Counter
jieba分词中有三种分词模式,不同的分词模式将直接影响分词的结果:
1、精确模式(默认)
试图将句子最准确的切开,适合文本分析:
text = '我现在在jupyter notebook上写文本分析的代码!'
cut = jieba.cut(text)
'/'.join(cut)
![]()
除此之外还可以给出各个词语的词性:
words = psg.cut(text)
for word,flag in words:
print(word,flag)

2、全模式
把句子中所有可以组成词的词语都扫描出来,速度快,但不能解决歧义:
'/'.join(jieba.cut(text,True))
![]()
很显然,它将所有可以组成词的词语都扫描出来,但出现了一些原意中不应该出现的词语,如“本分”
3、搜索引擎模式
在精确模式的基础上,对长词再次切分,提高召回率,是用于搜索引擎分词:
baogao = open('...\\政协报告.txt', encoding = 'UTF-8').read()
print('文本长度:',len(baogao))
baogao_words = [x for x in jieba.cut(baogao) if len(x)>=2]
c = Counter(baogao_words).most_common(20)
c

baogao_words1 = [x for x in jieba.cut_for_search(baogao) if len(x)>=2]
c1 = Counter(baogao_words1).most_common(20)
c1

从两张图的差异可以看出,精确模式中“人民政协”中的“政协”并没有算到“政协”出现的次数之中,需要利用搜索引擎模式才能把文中所有“政协”出现的次数算到一起
二、词云图
词云图是由词汇组成类似云的彩色图形,利用词云图可以过滤文章大量无关紧要的文本信息,使浏览者能够很直接客观地凭借视觉感官提取文本中的主题内容
1、wordcloud模块导入
import jieba.analyse
import matplotlib as mpl
import matplotlib.pyplot as plt
from wordcloud import WordCloud,STOPWORDS,ImageColorGenerator
词云图主要用到的是WordCloud词云包
2、词云图实现
content = open('...\\政协报告.txt', encoding = 'UTF-8').read()
tags = jieba.analyse.extract_tags(content,topK=200,withWeight=False)
text = ' '.join(tags)
wc = WordCloud(font_path='C:\\Windows\\Fonts\\华文行楷.ttf',
background_color='white',max_words=100,
max_font_size=120,min_font_size=10,
random_state=42,width=1200,height=900)
wc.generate(text)
plt.imshow(wc)
plt.axis('off')
plt.show()
读取相关文件后,用jieba分词,再筛选出出现频率较高的200个词语生成词云图

三、实例——利用股评进行情绪分析
1、数据来源及snownlp模块导入
相关股评来自新浪财经-股市及时雨标题信息
https://finance.sina.com.cn/roll/index.d.html?cid=56589&page=1
情绪分析利用SnowNLP进行打分,得分在0~1之间,0表示消极、1表示积极,0.5可用于区分积极与否
import pandas as pd
from snownlp import SnowNLP
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
sns.set_style('whitegrid',{'font.sans-serif':['simhei','Arial']})

股票数据的获取可参考我之前写的文章
Python量化交易策略及回测系统
2、代码实现
2.1、读取股评文件
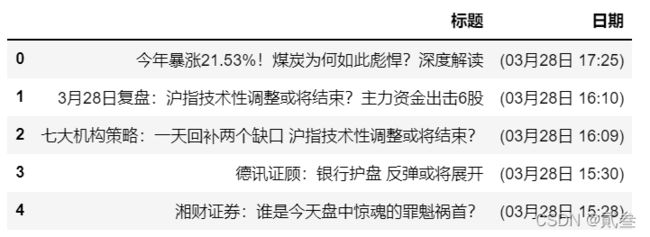
comments = pd.read_csv('...\\情绪.csv',index_col=0)
comments.head()
2.2、处理数据
i=0
while(i<lencom):
comments.iloc[i,1]=str(comments.iloc[i,1])[1:7]
i+=1
comments.head()
由于爬取的“日期”数据中出现了较多的其他信息,我们可以将这些数据处理一下:

2.3、计算情绪指数
comments['情绪'] = None
lencom = len(comments)
i=0
while(i<lencom):
s=SnowNLP(comments.iloc[i,0]).sentiments
comments.iloc[i,2]=s
i+=1
comments.head()
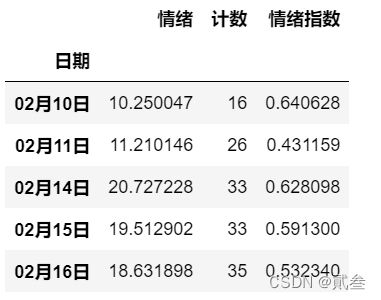
利用股评文本,计算相应情绪指数,并将这些数据增加到DataFrame数据中的“情绪”一列中:

2.4、计算每日情绪均值
numbyday = comments['情绪'].groupby(comments['日期']).count()
emobyday = comments['情绪'].groupby(comments['日期']).sum()
markbyday = pd.DataFrame()
markbyday['情绪']=emobyday
markbyday['计数']=numbyday
markbyday['情绪指数']=markbyday['情绪']/markbyday['计数']
markbyday.head()
2.5、获取股票数据
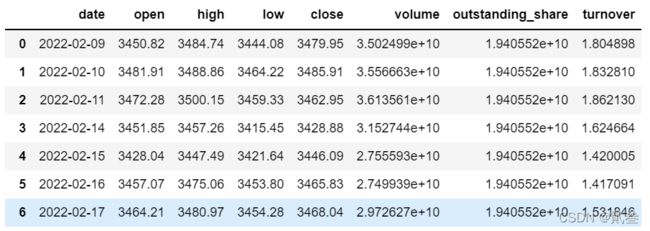
import akshare as ak
sh_df = ak.stock_zh_a_daily(symbol='sh000001', start_date='20220209', end_date='20220328')
sh_df
2.6、计算股票涨跌幅
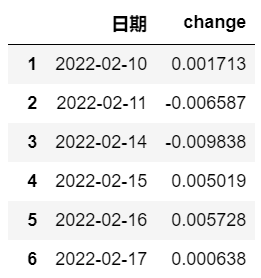
market = pd.DataFrame()
market['日期']=sh_df.iloc[1:,0]
market['change']=sh_df['close'].pct_change(periods=1)
market
2.7、数据再处理
i=0
lenmark=len(markbyday)
markbyday['order']=markbyday.index
markbyday['日期']=None
while(i<lenmark):
str1 = markbyday.iloc[i,3]
str2 = '2022-'+str1[0:2]+'-'+str1[3:5]
markbyday.iloc[i,4]=str2
i+=1
markbyday.head()
由于两个DataFrame数据合并需要它们的索引一致,因此在情绪指数数据中增加一列“日期”数据,使这些数据与股票涨跌幅数据中的“日期”数据类型一致,便于合并:
2.8、数据合并
markbyday.set_index('日期',inplace=True)
market.set_index('日期',inplace=True)
result = market.join(markbyday)
result
2.9、数据可视化
plt.figure(figsize=(10,8))
plt.plot(result['change'],label='上证波动')
plt.plot(result['情绪指数'],label='情绪波动')
plt.title('市场波动与情绪指数')
plt.xlabel('交易日期',fontsize=15)
plt.ylabel('波动率',fontsize=15)
plt.legend(loc='best')
plt.show()
最终,将股票涨跌幅数据和情绪指数数据展现出来
3、结果分析
3.1、折线图
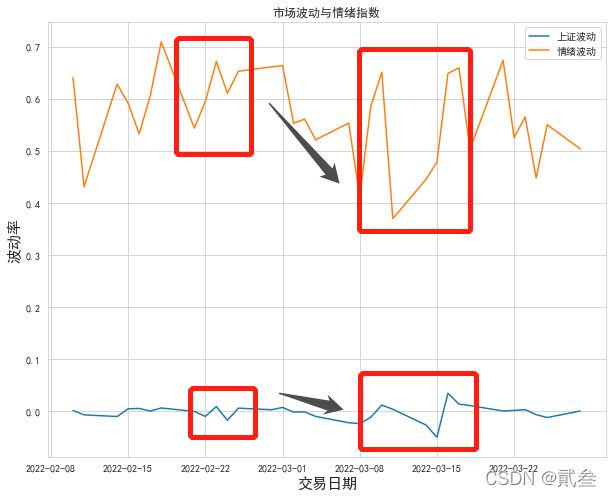
从图中可以看出,股票的上下波动与情绪的乐观与否是相对应地发生变化的,而且当股票收益率有向下趋势时,情绪也随之从较乐观(0.68)到较悲观(0.42)转变
3.2、词云图
lencom = len(comments)
i=0
text=''
while(i<lencom):
text = text + comments.iloc[i,0]
i+=1
tags1 = jieba.analyse.extract_tags(text,topK=100,withWeight=False)
text1 = ' '.join(tags1)
wc1 = WordCloud(font_path='C:\\Windows\\Fonts\\华文行楷.ttf',
background_color='white',max_words=100,
max_font_size=120,min_font_size=10,
random_state=42,width=1200,height=900)
wc1.generate(text1)
plt.imshow(wc1)
plt.axis('off')
plt.show()
除了情绪指数之外,我们也可以通过词云图观察,与情绪相关的、出现较多次的词语有:强势、回落、震荡、冲高、领涨、涨停、走弱……

结语
文本分析是数据分析当中的重要领域。利用分词、词频统计、词云图制作和语句情景分析等技术,可以从文本素材中发现很多有价值的数据和规律。在金融数据分析中,文本分析可用于财经舆情监测、股评情绪分析、会计报表分析等场景的实际案例之中。
大家如果觉得文章不错的话,记得收藏、点赞、关注三连~
如果需要相关数据可以私信找我