LogisticRegression算法之分类实操
python Logistic算法之分类实操
基本概念
先简单介绍一下机器学习里面的两个概念
1.损失函数
损失函数是机器学习里最基础也是最为关键的一个要素,它的作用就是衡量模型预测的好坏。
我们举个简单地例子来说明这个函数:
假设我们对一家公司的销售情况进行建模,分别得出了实际模型和预测模型,这两者之间的差距就是损失函数,可以用绝对损失函数来表示:
L(Y-f(X))=|Y-f(X)|——公式Y-实际Y的绝对值
对于不同的模型,损失函数也不尽相同,比如使用平方损失函数代替绝对损失函数:
L(Y-f(X))=(Y-f(X))^2——公式Y-实际Y的平方
损失函数是很好的反映模型与实际数据差距的工具,理解损失函数能够更好得对后续优化工具(梯度下降等)进行分析与理解。很多时候遇到复杂的问题,最难的一关就是如何写出损失函数。
2.正则化
正则化是指对模型做显式约束,以避免过拟合。正则化的具体原理就不在这里多叙述了,感兴趣的朋友可以看一下这篇文章:机器学习中正则化项L1和L2的直观理解。
算法简介
LogisticRegression
该模型的预测公式如下:
y=w[0]*x[0]+w[1]x[1]+w[2]x[2]+…+w[p]x[p]+b>0
这个公式看起来和线性回归的公式非常相似。虽然LogisticRegression的名字中含有回归(Regression),但它是一种分类算法,并不是回归算法,不要与LinearRegression混淆。在这个公式中我们并没有返回特征的加权求和,而是为预测设置了阈值(0)。如果函数值小于0,我们就预测类别为-1,如果函数值大于0,我们就预测类别+1。对于所有用于分类的线性模型,这个预测规则都是通用的。
数据来源
胎儿健康分类:https://www.kaggle.com/andrewmvd/fetal-health-classification
该数据包含胎儿心电图,胎动,子宫收缩等特征值,而我们所需要做的就是通过这些特征值来对胎儿的健康状况(fetal_health)进行分类。

数据集包含从心电图检查中提取的2126条特征记录,然后由三名产科专家将其分为3类,并用数字来代表:1-普通的,2-疑似病理,3-确定病理。
数据挖掘
1.导入第三方库
import pandas as pd
import numpy as np
import winreg
from sklearn.model_selection import train_test_split#划分数据集与测试集
from sklearn.linear_model import LogisticRegression#导入算法模块
from sklearn.metrics import accuracy_score#导入评分模块
老规矩,上来先依次导入建模需要的各个模块。
2.读取文件
import winreg
real_address = winreg.OpenKey(winreg.HKEY_CURRENT_USER,r'Software\Microsoft\Windows\CurrentVersion\Explorer\Shell Folders',)
file_address=winreg.QueryValueEx(real_address, "Desktop")[0]
file_address+='\\'
file_origin=file_address+"\\源数据-分析\\avocado.csv"#设立源数据文件的桌面绝对路径
glass=pd.read_csv(file_origin)#https://www.kaggle.com/andrewmvd/fetal-health-classification
因为之前每次下载数据之后都要将文件转移到python根目录里面,或者到下载文件夹里面去读取,很麻烦。所以我通过winreg库,来设立绝对桌面路径,这样只要把数据下载到桌面上,或者粘到桌面上的特定文件夹里面去读取就好了,不会跟其它数据搞混。
其实到这一步都是在走流程,基本上每个数据挖掘都要来一遍,没什么好说的。
3.清洗数据
查找缺失值:
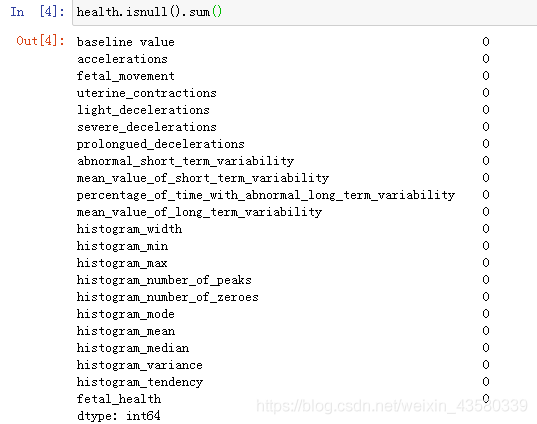
从上面的结果来看,数据中没有缺失值。
4.建模
train=health.drop(["fetal_health"],axis=1)
X_train,X_test,y_train,y_test=train_test_split(train,health["fetal_health"],random_state=1)
###考虑到接下来可能需要进行其它的操作,所以定了一个随机种子,保证接下来的train和test是同一组数
划分列索引为特征值和预测值,并将数据划分成训练集和测试集。
logistic=LogisticRegression(penalty='l2',C=1,solver='lbfgs',max_iter=1000)
logistic.fit(X_train,y_train)
print("Logistic训练模型评分:"+str(accuracy_score(y_train,logistic.predict(X_train))))
print("Logistic待测模型评分:"+str(accuracy_score(y_test,logistic.predict(X_test))))
引入LogisticRegression算法,并将算法中的参数依次设立好,进行建模后,对测试集进行精度评分,得到的结果如下:
![]()
可以看到,该模型的精度为88%左右。
5.参数讲解
在这里我们只讲解几个重要的参数,对于其它的参数,朋友们可以自行探究。
LogisticRegression(penalty=‘l2’, dual=False, tol=0.0001, C=1.0,fit_intercept=True, intercept_scaling=1, class_weight=None,random_state=None, solver=‘liblinear’, max_iter=100,multi_class=‘ovr’, verbose=0, warm_start=False, n_jobs=1)
1.penalty:正则化项的选择。正则化主要有两种:L1和L2,默认选择L2正则化。(相较于ridge和lasso这两个默认正则化的线性算法来说,自由选择正则化是这个算法的一大优点。)
2.C :正则化强度(正则化系数λ)的倒数; 必须是大于0的浮点数。 与支持向量机一样,较小的值指定更强的正则化,通常默认为1。
3.solver :‘newton-cg’,‘lbfgs’,‘liblinear’,‘sag’,‘saga’。默认参数:liblinear
liblinear:使用了开源的liblinear库实现,内部使用了坐标轴下降法来迭代优化损失函数。
lbfgs:拟牛顿法的一种,利用损失函数二阶导数矩阵即海森矩阵来迭代优化损失函数。
newton-cg:也是牛顿法家族的一种,利用损失函数二阶导数矩阵即海森矩阵来迭代优化损失函数。
sag:即随机平均梯度下降,是梯度下降法的变种,和普通梯度下降法的区别是每次迭代仅仅用一部分的样本来计算梯度,适合于样本数据多的时候。
saga:线性收敛的随机优化算法。
4.max_iter:求解器收敛的最大迭代次数。(通常来说越大越好)
6.调参

1.在用这个算法进行分类的时候,偶尔会出现这样的警告,大概的意思就是最大迭代次数无法满足solver参数的收敛,这个时候我们除了选择另外一个参数之外,还可以通过增加最大迭代次数来解决这个问题。

从上图可以看到除了警告消失了,相较于之前的运行结果,模型的精度有所上升。当然增加最大迭代次数并不会无限提高模型精度。当提高到某个程度,满足了solver的参数的收敛之后,模型精度便不再提升。
2.参数C代表的是正则化的强度,数值越小,正则化越强。

3.solver参数
我觉得solver参数最大的优点,就是用一个参数很好的区分了二分类与多分类的问题,并且进行了优化。
简单解释一下这两类问题:判断某个女生是否喜欢你,它只会回答你喜欢或者不喜欢。这就是二分类问题。当然这对我们来说,显得太粗鲁了,要不希望,要不绝望,都不利于身心健康。那如果它可以告诉我,她很喜欢、有一点喜欢、不怎么喜欢或者一点都不喜欢,这就是多分类问题。而且相较于上一个问题来说,也许就会有不同的解决办法。
下面对二分类问题进行建模:
health=health[health["fetal_health"]!=3]#去掉3,只保留1,2,将之前的多分类问题变成二分类问题
train=health.drop(["fetal_health"],axis=1)
X_train,X_test,y_train,y_test=train_test_split(train,health["fetal_health"],random_state=1)
logistic=LogisticRegression(penalty='l1',C=1,solver='liblinear')
logistic.fit(X_train,y_train)
print("Logistic训练模型评分:"+str(accuracy_score(y_train,logistic.predict(X_train))))
print("Logistic待测模型评分:"+str(accuracy_score(y_test,logistic.predict(X_test))))
得到结果:

下面是我对solver参数适用范围的一个汇总,大家看一下:

这里要说明的一件事就是用于处理多分类的参数也同样可以用来处理二分类,只是效果不会很理想:

跟上一个参数所建立的模型相比,可以看出模型精度有所下降。
小结
目前为止,我们已经用过几个线性算法了(lasso,ridge,最小二乘),这些算法的区别在于以下两点:
1.系数(w)和截距(b)的特定组合对训练数据拟合好坏的度量方法(损失函数)
2.是否使用正则化,以及使用哪种正则化方法。
不同的算法使用不同的方法来度量“对训练拟合的好坏”。由于数学上的技术原因,不可能调节w和b使得算法产生的误分类数量最少。所以对于我们的目的,以及对于许多应用而言,上面第一点的选择有时并不重要。
所以线性模型的主要参数是正则化参数,在回归模型中叫做alpha,在LogisticRegression中叫做C。alpha值较大或C较小,说明模型简单。特别是对于回归模型来说,调节这些参数非常重要。通常你还需要确定用L1正则化还是L2正则化。如果假定只有几个特征值是真正重要的,那么应该用L1正则化,否则默认使用L2正则化。如果模型的可解释性很重要的话,使用L1也会有帮助,因为L1只用到几个特征,所以更容易解释哪些特征对模型是重要的,以及这些特征的作用。
线性模型的一个优点就是训练速度非常快,预测速度也很快。这种模型可以推广到非常大的数据集,对稀疏数据也很有效。如果你的数据包含数十万甚至上百万个样本,你可能需要研究如何使用LogisticRegression和Ridge模型的solver="sag"选项,在处理大型数据时,这一选项比默认值要更快。
线性模型的另一个优点在于,利用我们之前件过得用于分类和回归的公式,理解如何进行预测是相对比较容易的。不幸的是,往往并不完全清楚系数为什么是这样的。如果你的数据集中包含高度相关的特征,这一问题尤为突出。在这种情况下,可能很难对系数做出解释。
个人博客:https://www.yyb705.com/
欢迎大家来我的个人博客逛一逛,里面不仅有技术文,也有系列书籍的内化笔记。
有很多地方做的不是很好,欢迎网友来提出建议,也希望可以遇到些朋友来一起交流讨论。