【Python数据分析】数据预处理3——数据规约(含主成分分析详解、Python主要预处理函数)
数据规约产生更小且保持完整性的新数据集,在规约后的数据集上进行分析和挖掘将提高效率
一、属性规约
属性规约通过属性合并创建新属性维数,或者通过直接删除不相关的属性来减少数据维数,从而提高数据挖掘的效率,降低计算成本。属性规约常见的方式如下表所示:
| 属性规约方法 | 方法描述 |
| 合并属性 | 将一些旧属性合并为新属性 |
| 逐步向前选择 | 从一个空属性集开始,每次从原来属性集合中选择一个当前最优的属性添加到当前属性子集中,直到无法选出最优属性或满足一定阈值约束为止 |
| 逐步向后删除 | 从全属性集开始,每次从当前属性子集中选择一个当前最差属性并将其从当前属性子集中消去,与上面相反 |
| 决策树归纳 | 利用决策树的归纳方法对初始数据进行分类归纳学习,获得一个初始决策树,所有没有出现在决策树上的属性均可认为是无关属性,因此可以将这些属性删除 |
| 主成分分析 | 用较少的变量去解释原数据中的大部分变量,将许多相关性很高的变量转化成彼此相互独立或不相关变量 |
以下几篇文章讲了主成分分析的原理和推导过程,可以借鉴:
如何通俗易懂地讲解什么是 PCA(主成分分析)? - 知乎
PCA:详细解释主成分分析_lanyuelvyun的博客-CSDN博客_主成分分析
PCA(主成分分析)-------原理,推导,步骤、实例、代码_xxty1122的博客-CSDN博客_主成分分析代码
这篇文章详细的讲了PCA的代码实现
Python机器学习笔记:主成分分析(PCA)算法 - 战争热诚 - 博客园
我们就用Python中自带的scikit-learn库中的主成分分析来实现降维:
class sklearn.decomposition.PCA(n_components=None, copy=True, whiten=False)
参数说明:
n_components:
意义:PCA算法中所要保留的主成分个数n,也即保留下来的特征个数n
类型:int 或者 string,缺省时默认为None,所有成分被保留。
赋值为int,比如n_components=1,将把原始数据降到一个维度。
赋值为string,比如n_components='mle',将自动选取特征个数n,使得满足所要求的方差百分比。
copy:
类型:bool,True或者False,缺省时默认为True。意义:表示是否在运行算法时,将原始训练数据复制一份。
若为True,则运行PCA算法后,原始训练数据的值不会有任何改变,因为是在原始数据的副本上进行运算;
若为False,则运行PCA算法后,原始训练数据的值会改,因为是在原始数据上进行降维计算。
whiten:
类型:bool,缺省时默认为False
意义:白化,使得每个特征具有相同的方差。
import pandas as pd
# 参数初始化
inputfile = './Python数据分析与挖掘实战(第2版)/chapter3/demo/data/principal_component.xls'
outputfile = './Python数据分析与挖掘实战(第2版)/chapter3/demo/data/dimention_reducted.xls' # 降维后的数据
data = pd.read_excel(inputfile, header = None) # 读入数据
from sklearn.decomposition import PCA
pca = PCA()
pca.fit(data)
print(pca.components_) # 返回模型的各个特征向量
print(pca.explained_variance_ratio_) # 返回各个成分各自的方差百分比得到结果如下:
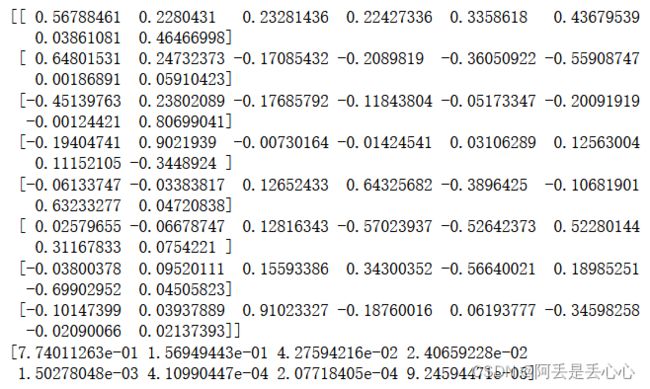
可以发现,当选取前4个主成分时,累计贡献率已经达到了97.37%,说明选取前三个主成分进行分析时已经很不错了,因此可以重新建立PCA模型,设置n_components = 3,如下:
pca = PCA(3)
pca.fit(data)
low_d = pca.transform(data) # 用它来降低维度
pca.inverse_transform(low_d) # 必要时可以用inverse_transform()函数来复原数据
low_d二、数值规约
1.直方图(之前文章已经详细讲过)
2.聚类(之前文章也讲过)
使用数据的簇替换实际数据
3.抽样
(1)无放回简单抽样
(2)有放回简单抽样
(3)聚类抽样
(4)分层抽样
4.参数回归
将所有数据规约成线性(或对数线性)函数,线上对应的点可以近似看做已知点
三、Python主要预处理函数
1.interpolate
scipy的一个子库,下面包含了大量的插值函数,如拉格朗日插值、样条插值等,使用之前用
from scipy.interpolate impoort * 引入相应的插值函数 (具体使用,之前的文章有讲过)
2.unique
去除数据中的重复元素,得到单值元素列表,是numpy中的一个函数,也是series对象的一个方法
import pandas as pd
import numpy as np
D = pd.Series([1,1,2,3,5])
D.unique()
np.unique(D)3.isnull/notnull
判断每个元素是否为空值
4.random
import numpy as np
np.random.rand(k,m,n) #生成一个k*m*n的随机矩阵,其元素均匀的分布在区间(0,1)上
np.random.randn(k,m,n) #生成一个k*m*n的随机矩阵,其元素服从标准正态分布