来自同济子豪兄的无私分享-YOLOv1论文的学习(二)
https://www.bilibili.com/video/BV15w411Z7LG?p=10&spm_id_from=pageDriverhttps://www.bilibili.com/video/BV15w411Z7LG?p=10&spm_id_from=pageDriver https://www.bilibili.com/video/BV15w411Z7LG?p=10&spm_id_from=pageDriver
https://www.bilibili.com/video/BV15w411Z7LG?p=10&spm_id_from=pageDriver
感谢子豪兄的无私分享
感谢豪哥的开源精神

这张图是目标检测算法多年来在精确度上的发展变化
YOLO和RCNN的相爱相杀:

为什么YOLO可以看到全图的信息?
因为YOLO是将整张图片送进网络,隐式地编码全图中各个物体的关系。RCNN是将各个检测框送进网络
论文中就是这么讲的

像fast-RCNN就容易发生背景误判的情况,because it can't see the larger context
YOLO不是要分98个bbox吗,这98个bbox是怎么产生联系以至于YOLO可以分析全图的信息??
RCNN和YOLO的优势互补

VOC2012数据集下各个模型对各个类别的识别率比较

YOLO的泛化能力(在自然图像上训练,在艺术作品上测试)

每个grid cell只能同时预测一个类别
论文精读
原文对于YOLO的总体描述:

YOLO对于背景和物体的区分做的好:

RCNN:
用region proposal提取2000多个预测框,然后对每个预测框使用卷积神经网络(分类器)逐一做分类和回归。所以才说,RCNN涉及到分类器的重复使用。

而卷积神经网络这种分类器就是线性分类器级联的结构
猜想:
我还不熟悉RCNN,但基于现有的知识,提出一个关于RCNN分类器猜想
为什么RCNN对背景的误判问题更加严重?是否是因为丢失了图像中目标之间的某些关系
这种问题在学习CNN的时候讲过,如果把图像直接送进深度神经网络,会丢失图像当中的空间关系,由此才提出CNN。
另外,RCNN将图像拆分成了2000多个单独的小图像,并对他们进行分别处理。
那么,在分割的过程中,空间关系或许就丢失了。即便使用卷积,也只能保留各个预测框中的空间关系,更高层次的空间关系,即原图的空间关系在region proposal阶段就已经丢失。虽然YOLO也要对图像进行分割,之所以它能够保留原图的空间关系,是否是因为他将预测框排列好了之后整体送进全卷积神经网络。但是,YOLO的结构图又说,他是把原图送进网络

怎么理解YOLO一次前向推断就得到bbox coordinates and class probability?
YOLO的输入是整张图像,隐去进入全卷积网络之前得到98个bbox的步骤,经过全卷积网络的处理得到一个7*7*30的tensor,再做NMS的相关处理,最终就得到了bbox coordinates and class probability.
由此,怎么理解RCNN无法通过一次前向推断就得到上述结果呢?
QUESTIONMARK:
YOLO一直说她的输入是整张图,但他又说卷积网络是同时处理98个bbox,他隐去了处理bbox的细节,导致理解上断裂了

核心问题:这98个bbox是怎么送进网络进行训练的??
这句讲用来自全图的特征去预测每一个bbox。怎么利用呢?

training stage
1.ground truth(标注)的中心落到那个grid cell里,就由哪个grid cell负责生成bbox来拟合这个标注
2.每个grid cell除了生成bbox coordinates之外,还要生成confidence score.就是该bbox包含物体的概率。这个设计我是没想到的,不只是原创,还是继承

并且,confidence score的形式被定义为
![]()
这个值会被可视化bbox的线条粗细。这个P(object)要么为0,要么为1。对confidence score的值可以进一步讨论

3.bbox的定位方式,以所属的grid cell的左上角坐标为基点。bbox的长宽以整幅图的长宽为基点。这是基于归一化的要求。咱们之前也写过bbox原始定位和尺寸与归一化之后的结果的反解函数
4.每个grid cell 只预测一组conditional class probability,所属的每个bbox 共享这一组概率
其实,上一篇在讲测试阶段的预测后处理的时候,我们计算了98个向量,将这些代表bbox的98个向量做横向和纵向处理。计算98个向量就基于共享这个设定
5.全类别概率的计算公式:

如果严格按照条件概率的定义,这个公式肯定不符合。所以这个类别概率服从于一个扩展定义。这个值既反映了类别的精度,也放映了回归定位的精度。

由此,又产生一个问题:P(object)、P(class|object)的值怎么确定??

network design
网络的主体结构和CNN是一样的,卷积层+FC层。24层卷积+2层FC。
这里提到了1*1的filter,其作用在于降维、升维、跨通道信息传递。1*1卷积之后跟3*3卷积

 可以看到,中间部分就是1*1卷积和3*3卷积的交替使用,前者的数量比较少,后者比较多
可以看到,中间部分就是1*1卷积和3*3卷积的交替使用,前者的数量比较少,后者比较多
![]() 可以看到,YOLO1使用imagenet的分类任务来做的预训练,输入的图像宽、高都要小一半。
可以看到,YOLO1使用imagenet的分类任务来做的预训练,输入的图像宽、高都要小一半。
仍然不清楚是怎么处理这98个bbox???
how to train the net
这是神经网络的pipeline

提到了YOLO的优化思路,研究表明,同时增加卷积层和FC层去预训练模型可以优化

任少卿,resnet, fast-RCNN
相比之预训练,实际训练为什么需要增加图片的分辨率?目标检测需要细粒度的视觉信息

激活函数分为两种,最后一层用线性激活,其他层全部都是leaky relu

损失函数选择的是平方和误差,这是回归问题常用的损失函数。这个函数好优化,但是还有缺点
YOLO1里边的bbox分为三类,一类负责预测物体,一类不预测物体,一类是其所属的grid cell不预测物体,毫无疑问,最后一类肯定是占多数,他们在损失函数的比重就会特别大

这一条后果没太理解,导致发散??
 权重调节,给预测物体的bbox加高权重
权重调节,给预测物体的bbox加高权重

对于大框小框问题,采用宽、高的根来计算

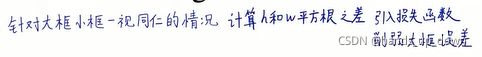

我们的误差度量应该反映出,大盒子里的小偏差比小盒子里的小偏差更重要。
谁来预测,谁来拟合

由此产生的统计结果是

检测框的形状随着训练的加深越来越朝着其所检测物体的形状发展
怎么感觉这是句废话??
因此,到了YOLO2引入anchor机制 ,固化了几种bbox的尺寸
这里我想插一句,目前我仍然没有想清楚到底是怎么处理这98个bbox,但我经过思考,又有了一个猜想:
1.感觉还是容易陷入硬编码的思维。回顾神经网络的思想,我们想要的结果其实都是从我们提供的特征当中学到的,无论这个结果是什么,有多奇怪,和这个特征在直觉上多么不符。必须牢牢这个思想。
2.神经网络从结构上说只能输出向量,那么将YOLO1的7*7*30的输出变形成1470维的向量。这样一来就可以把它放到神经网络中。这个向量当中就包含98个bbox的坐标信息
3.我们模拟对第一个样本的训练。一直到FC的输出层,我认为跟CNN的分类任务是一模一样的。这个时候就容易陷入硬编码的思维,就会想既然是跟图像识别一样的步骤,那怎么可能算出bbox的坐标呢。而且YOLO1规定了bbox的中心坐标要落到所属的grid cell当中,很明显通过上述方式,不可能让bbox的中心坐标落到grid cell当中。就是这一点我迟迟没想通
4.既然如此,在图像分类任务当中,请问对第一个样本的输出能达到你说的哪个要求吗?这正是神经网络的本质所在啊。
5.猜想的重点来了,算出的这1470维的向量,尤其是里面的bbox的坐标肯定是有问题的。我们是通过loss的设计来使模型朝着我们希望的方向发展。回看图像分类任务中的loss设计,其核心就是提取标注中的相关信息与输出相关信息的差异。比如常用的交叉熵,多类支撑向量机损失,相对于直接提取差异,结构上更复杂
6.所以基于这个猜想,是否可以做出这样一个结论:LOSS的设计就决定了神经网络最终可以从特征中学到的内容
YOLO1中loss function的结构:
1.
2.
3.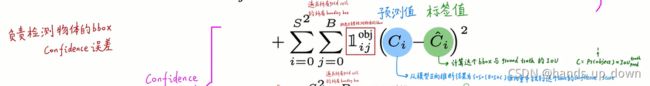
我们可以看到,预测值来自于FC的输出中的某一维,标签值由输出当中的某个bbox与ground truth计算而来,当然这个时期的bbox的位置可能非常离谱,也就是说这个IoU可能为0
4.
5.
做了上面的猜想之后,看待这个loss的结构似乎就更加清晰了。
现在的问题变成了为什么要计算confidence误差??如果是我来设计,我很可能会忽略这个误差,只计算定位和分类误差
首先confidence在YOLO1的结构中是有输出的,根据图像分类任务的经验,有输出的都是要做迭代的。至少从这个意义上,必须计算他的误差
你看哈,在上述的loss结构的第三项佐证了我的这种猜想
![]()
yolo1中的49个grid cell,98个bbox, 这些设置最终都体现在loss function的参数上
基于loss决定输出的这一猜想,尝试解释两个问题:
1.怎么确定从属于grid cell的两个bbox的中心落在grid cell中??
bbox的中心最开始并不在grid cell中,我们是给每个grid cell分配了两个bbox,最开始bbox的中心可能很离谱,需要通过中心定位误差来迭代。
2.怎么确定grid cell是否包含物体?
利用标注的信息。标注框所包含的就是物体。我们可以在最开始做一个矩阵,利用标注信息给矩阵赋值
训练的规模:

learning rate的设定:

处理过拟合:


NMS(non-maximal suppression)

YOLO1的limitations:
1.
怎么理解每个grid cell只能有1个类别??
以推理阶段为例,假设图片中有两个物体,他们是部分重叠的,那么就有两个bbox,根据yolo的规则,这两个bbox一定从属于不同的grid cell,那么这两个grid cell一定是不同的类别
2.小目标和密集目标的识别比较差,等到YOLO3才能解决
3.对于不寻常尺寸物体以及环境的泛化能力就比较差
4.粗粒度特征,因为有大量的池化操作,丢失了空间信息

5.定位误差大。YOLO对大框和小框是一视同仁的,虽然在loss当中做了加权以弱化这一点

与其他目标检测框架的比较
通常的做法:
1. 提取健壮的特征


2.用分类器或者回归器识别图像中的目标
3.识别的方法要么是滑窗,要么是在区域子集上分类
DPM(deformable parts models)可变部分模型:偏硬编码,泛化能力差

该模型使用静态特征,就是说这种特征是人为规定的,符合某种分布。HOG,方向梯度直方图
RCNN(rigion convolution NN)
用选择搜索算法提取2000多个候选框,再分别对每一个候选框提取卷积特征,然后使用SVM进行分类,线性模型进行预测框的调整,NMS去除冗余。这就很有硬编码的味道。YOLO1将以上这些放在LOSS里面

fast-RCNN
先对全图提取卷积特征,在提取检测框,检测框共享卷积特征
faster-RCNN
用rpn代替了RCNN的选择搜索算法
虽然上述两者有提升,但仍然达不到real time 的效果。智能售货机的商品识别不需要实时
加速DPM的方案,有点像智能售货机的那个方案

deep multibox
使用神经网络来预测盒子(rigions of interest = RoI),代替RCNN中的选择搜索算法
通用目标检测:泛化能力很强
OverFeat:


YOLO1和R-CNN的错误分析


