第四章 分类器集合,K折交叉验证以及置信区间计算
文章目录
- 前言
- 一、什么是交叉验证?(corss-validation,简称CV)
- 二、使用步骤
-
- 1.引入库
- 2.读入数据
- 3.分类器
-
- K近邻
- 感知机
- 贝叶斯
- 4.K折交叉验证
- 5.置信区间
- 总结
前言
学习数据挖掘,用于记录练习和回顾
一、什么是交叉验证?(corss-validation,简称CV)
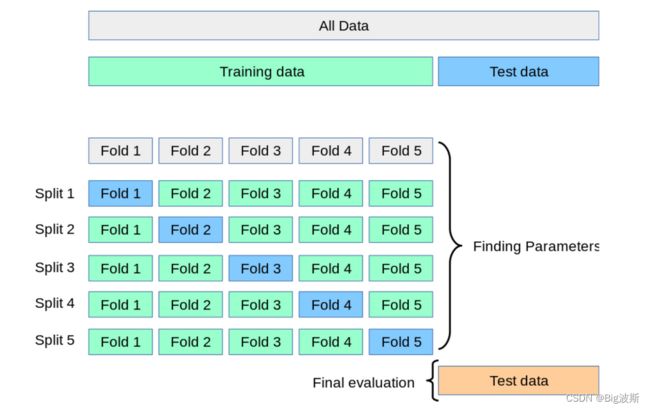
当评估器对不同的模型参数(“超参数”)进行评估时,如参数C是支持向量机的一个超参数,在模型未调整前,仍有过拟合的风险,因为参数的选择决定模型的最佳表现。然而,通过这种方式,测试集中的信息仍有可能会“泄露”到模型中,导致评估指标不能概括模型的评估能力。通过将已知数据集划分一部分为“验证集”可以解决上述问题:在训练数据上对模型进行训练,利用验证集对模型进行评估。当“实验”得到一个较好的成绩时,在测试集上完成模型的最终评估。
解决上述问题的一个方法是交叉验证。当应用交叉验证的方法时,不再需要划分验证集,而测试集始终应用于模型的最终评估。最基本的交叉验证方法是K折交叉验证(k-fold CV),它是指将训练集划分为k个最小的子集。如下的过程应用k“折叠”中的一个:
- 将k-1个子集用于模型训练;
- 用剩余数据验证上一步中建立的模型(类似于利用测试集计算模型的准确率)。
二、使用步骤
1.引入库
import pandas as pd
import numpy as np
from sklearn.linear_model import Perceptron
from sklearn.metrics import classification_report, plot_roc_curve
from sklearn.model_selection import train_test_split, cross_val_score, LeaveOneOut
from sklearn.naive_bayes import BernoulliNB, CategoricalNB, GaussianNB
from sklearn.neighbors import KNeighborsClassifier
from scipy import stats
2.读入数据
wine_data = pd.read_csv("./UCI/wine/wine.data", header="infer")
X, Y = wine_data.iloc[:, 1:], wine_data.iloc[:, 0] # 把分类属性与常规属性分开
# 75%训练集,25%测试集,75%训练标签,25%测试标签
x_train, x_test, y_train, y_test = train_test_split(X, Y, test_size=0.25, random_state=0)
3.分类器
K近邻
clf = KNeighborsClassifier(n_neighbors=3)
clf.fit(x_train, y_train)
predictions = clf.predict(x_test)
print("K近邻:\n" + classification_report(y_test, predictions))
感知机
clf = Perceptron(tol=1e-3, random_state=0)
clf.fit(x_train, y_train)
predictions = clf.predict(x_test)
print("感知机:\n" + classification_report(y_test, predictions))
贝叶斯
clf = BernoulliNB() # GaussianNB()高斯朴素贝叶斯 MultinomialNB()多项式朴素贝叶斯 BernoulliNB()伯努利朴素贝叶斯
clf.fit(x_train, y_train)
predictions = clf.predict(x_test)
print("伯努利朴素贝叶斯:\n" + classification_report(y_test, predictions))
4.K折交叉验证
注意这里是训练集做交叉验证,而不是测试集
accuracy = cross_val_score(clf, x_train, y_train, cv=10) #10折交叉验证
print("k折准确率:{}".format(accuracy))
print("k折平均准确率:{} (+/- {})".format(accuracy.mean(), accuracy.std() ** 2))
5.置信区间
"""
置信度: 0.95或0.97之类的常用的置信度,自己设置
自由度:数组的长度-1
均值:数据的均值
标准误:通过数据的标准差计算得到,等于-----std/√n 其中n是数组长度。
"""
interval = stats.t.interval(0.95, accuracy.shape[0] - 1, accuracy.mean(), accuracy.std() / np.sqrt(accuracy.shape[0]))
print("置信区间:{}".format(interval))
总结
support指相应类中有多少个样本分类正确

