Predicting Diabetes Disease Evolution Using Financial Records and Recurrent Neural Networks 全文翻译
纯手打,相互学习,如有问题还望指正。
部分英文术语属于最新提出,会直接贴出英文,抱歉。
深度学习,文本分析等问题可以加QQ交流,相互学习。QQ:1307629084
论文归类:迁移学习
简要说明:翻译这篇文章并不是因为这篇论文有多么厉害,甚至于说这篇论文都很难通顺的读下来,太多错字和语句问题,由于同样研究方向是糖尿病以及文本分析,从技术层面来看并没有太多的提升,但是这篇论文让我重新审视了巴西这个国家的科研和数据采集,说真的我们需要学习,虽然不知道国内当下数据采集是什么情况,但可以说这是一个非常值得学习的部分,甚至要超过绝大多数欧美国家。
原文链接:https://arxiv.org/pdf/1811.09350.pdf
论文作者:Rafael T. Sousa, Lucas A. Pereira, Anderson S. Soares
论文刊号:Machine Learning for Health (ML4H) Workshop at NeurIPS 2018.
发表时间:2018.11.23
论文题目:基于财务记录和递归神经网络的糖尿病病情演变预测
摘要
在许多国家,管理慢性病患者是一项重大和日益增长的卫生保健挑战。慢性疾病,如糖尿病,是一种持续很长时间,并且不会消失的疾病,常常导致患者的健康逐渐恶化。虽然最近的工作涉及来自医院的原始电子健康记录(EHR),但是这项工作仅使用来自健康计划提供者的财务记录来使用自关注递归神经网络预测糖尿病疾病的演变。使用财务数据是因为有可能成为国际标准的接口,因为记录标准编码医疗程序。主要目标是评估高危糖尿病患者,所以我们预测与糖尿病急性并发症有关的记录,如截肢和清创、再血管化和血液透析。我们的工作成功地预测了60-240天的并发症,ROC曲线下面积在0.81-0.94之间。在本文中,我们描述了在ROC曲线范围从0.81到0.83的健康计划提供者内开发的正在进行中的工作的前半部分。这项评估将给予医疗服务提供者早期干预和阻止住院的机会。我们的目标是向个别患者提供个性化预测和个性化建议,目的是改善结果并降低成本。
-
简介
世界卫生组织(WHO)上一份糖尿病报告[1]指出,糖尿病患者人数从1980年的1.08亿增加到2014年的4.22亿,导致18岁以上成年人中8.5%的全球患病率。糖尿病直接导致的死亡人数为2015人,占160万(2)。根据国际糖尿病联合会(International Diabetes Federation)的统计,巴西在糖尿病人数最多的国家中排名第四,在2017年约为1,240万[3,4,5]。
糖尿病人群的预防和管理是卫生公司的主要挑战之一。这些任务不仅可以改善患者的预后,而且可以大大平衡医疗开支。随着疾病的发展,它会损害心脏、血管、眼睛、肾脏和神经。它还增加了心脏病和中风的风险。血管损伤和神经系统的恶化可导致足部溃疡、感染和最终需要截肢。同样,这些损害也会使糖尿病成为肾衰竭的主要原因。
根据世界卫生组织的报告,有可能预防糖尿病的进展,然而,需要有效的工具来识别和评估高危人群[1]。通过这种方式,机器学习可以提出个性化的预测和建议,显著加强预防工作。我们想描述一种评估并发症风险的方法,作为糖尿病进展指数。
评估和评估患者的预后是一个复杂的问题,一些作者已经使用机器学习试图解决它[6,7,8,9]。他们的方法基于过去患者的电子健康记录(EHR)对疾病进展进行建模。我们可以着重介绍一些杰出的工作,如Choi’s Doctor AI[8],它利用递归神经网络(RNN)进行EHR的多标签预测。在一个大型真实数据集上的结果达到了79,58%,recall@30,并且报告该建模不仅模拟了人类医生的预测能力,而且提供了具有临床意义的诊断。另一项研究[9]提出了一种使用经典机器学习算法的糖尿病并发症预测技术,在预测视网膜病变、肾病和神经病变中ROC曲线下面积的平均值达到0.75。
引用的作品和其他[6,7]都依赖于关于患者的完整电子报告,如人口统计数据、体重指数、习惯、以及检查和实验室检测结果。根据大多数发展中国家的情况,在几家医疗保健公司中,电子病历和检查结果通常要么是数字格式不可用的,要么是过于异构而不能集成。在这项工作中,我们建议使用财务记录作为替代,因为它是可用的数据中,更可靠和易于收集。然而,财务记录处于不同的数据领域,具有更多的稀疏性和不相关的记录。为了解决这个问题,我们还提出一种基于自然语言过程最新进展的递归模型。
受巴西数据可用性和数据域差异的启发,我们提出了一种递归神经网络结构,通过健康计划提供者的财务记录来预测糖尿病并发症。我们将糖尿病并发症的风险作为糖尿病进展的指标。在下面的章节中,我们将详细阐述所使用的数据、获得的方法和结果、局限性、结论和未来的工作。 -
财务记录
在这项工作中,我们使用了来自巴西健康计划提供者的财务记录的数据集。过去五年的数据来自他们的客户。大约有7, 000,000个独特的个人,有3亿2700万个记录。
这些记录遵循巴西国家私人健康保险和计划管理局(ANS)的国家标准,该管理局被称为TUSS(UnificadaemSadeSuplementar-补充医疗保健统一术语)。TUSS术语是由巴西政府于2010年创建的,用于根据将要执行或已经执行的服务以及卫生计划提供者之间的信息交换来标准化向卫生保健公司的支付。该术语对于医疗程序、医院和诊所费率、材料、药物以及诸如矫形器和假肢等特殊材料有独特的编码。一些例子在表1中。
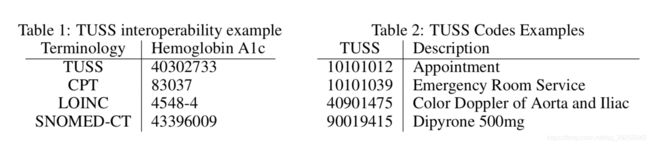
TUSS编码可以用作其他程序或医学标准的接口,如美国医疗保健通用程序编码系统或国际医学程序分类,提供国际互操作性。
当我们使用财务记录时,并发症是通过相关记录确定的。一些主要的糖尿病并发症是肾衰竭和心血管疾病,所以我们集中于三种记录:(一)截肢和清创;(二)血管重建和血管成形术;(三)血液透析。 -
模型
所提出的模型主要是由[10 ]提出的无监督学习语句嵌入启发的。使用无监督学习背后的原因是它选择最相关语句的能力。我们认为,这对于从长输入中选择相关记录和记录序列是有用的,其他可能无关的记录,如基本医院材料,如针和血清。
该模型具有一个嵌入层,该嵌入层与双向长短期存储器(LSTM)相连,具有自我注意机制,随后是两个完全连接的层。
使用从整个数据集中提取的Word2Vec跳图[11]对输入嵌入层进行预训练。由于每个代码作为单词是唯一的,所以我们希望创建一个向量表示来处理记录与自然语言共有的特性,比如:同义词,有来自相同药物但不同剂量的代码;反义词,一些药物具有相反的效果;单词组合,所以me协议具有标准的检查和药物序列,并且可以表示为不同代码的总和。这种输入预处理已经通过[8,12,13]等其他工作成功完成,作为从整个数据集中提取信息的一种方式,并且还处理大量不同的代码,在我们的例子中,有大约150,000种不同的代码。
其主要思想是利用网络来评估糖尿病人在一段时间间隔后出现并发症的可能性。
3.1 实验
为了评估预测能力,我们做了时间间隔为60、120、180和240天的测试,作为预测窗口。网络输入被限制到记录的最后12个月,由于LSTM的消失梯度问题和计算成本,最大限制为500条记录,最小限制为40条记录,以确保足够的数据作出决定并排除记录太少的个人。对于每个有并发症的糖尿病患者,我们在第一次记录并发症之前提取一个输入序列,而对于那些没有并发症的患者,我们随机抽取一个序列。
由于我们没有任何诊断来确认谁是糖尿病患者或者不是糖尿病患者,并且公司不要求医疗保健提供者告知诊断或者ICD(国际疾病分类)代码,因此我们定义一个基本过滤器来找到尽可能多的糖尿病患者。由于糖化血红蛋白被世卫组织定义为标准糖尿病诊断试验[14],因此在不到一年的时间内进行至少两次糖化血红蛋白试验的所有个体都被认为是可能的糖尿病。该过滤器使用与巴西的糖尿病统计数字相符的100,000个人(根据政府数据,占该国人口的8.9%),因为我们有大约200万个人,超过一年的数据,我们有5%认为是糖尿病。
并发症的低患病率使数据集不平衡。在可能的糖尿病患者中,我们发现了大约1900个并发症的样本。为了克服这样的问题,我们在每个实验的训练集中为每个复杂类过采样正值,以实现更好的平衡并避免过拟合。
对于每一个时间间隔,我们运行5倍交叉验证由于少量的正样本。所有模型的培训都是在PyTorch上实现的,使用Nvidia Tesla P100花费了大约24小时。
- 结果
作为基线,我们与无监督学习的LSTM网络进行比较,但是具有相同的预训练输入嵌入。表3用无监督学习模型(LSTM+SA)和标准LSTM报告了ROC曲线(AUC)下褶皱的平均面积。
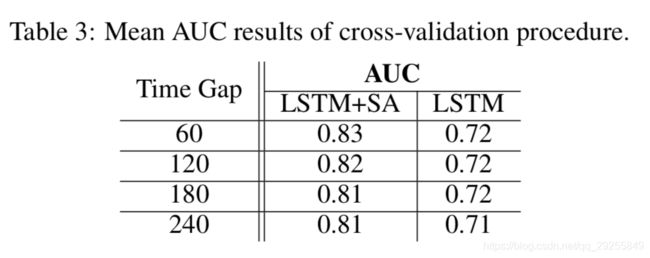
随着糖尿病病情日益严峻,专业测试和急诊就诊人数不断增加,预测窗口越大,诊断效果越差。长期预测似乎是一个更困难的问题,因为缺乏数据。
将自专注模型与标准LSTM进行比较,可以看出性能更好。这是由于有能力处理更长的输入与self-attention(SA)机制。图1显示了一个特定个体的神经网络注意映射分数的一部分。SA允许我们看到输入的哪部分参与预测糖尿病疾病的演变。
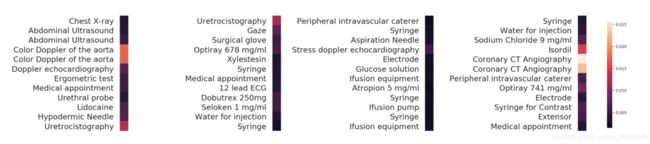
图1:self-attention分数的映射。记录描述被简化,最新的记录从左到右组织。三个月后进行血管成形术。
图2和图3中的折叠上的平均ROC和精确-回忆曲线报告了该模型表明在阳性和阴性病例之间有很好的平衡,并且还指出了设置阈值以确保低假阳性率的难度的限制。我们认为这可能与财务记录中缺乏考试结果有关。我们推断,有可能将模式检测为相关事件的高频率,但不可能理解其结果。

在一些假阴性和假阳性病例中观察数据,有些病例缺乏数据做预测。我们假设在这些病例中有些糖尿病患者病情进展缓慢或患者拒绝治疗。这些都表明了增加网络专用性的挑战。将此问题降到最低的一种方法是将这些个体包括在监测项目中,以便给予他们适当的治疗,然后评估那些具有真正高风险的人。
5. 结论
我们建议使用self-attention递归神经网络来使用财务记录预测糖尿病并发症。我们的结果显示了一种有前途的方法来预测并发症和评估高危糖尿病患者有效,平均AUC为0.82。尽管有假阳性,它仍然可以用作评估工具,将个人纳入中高风险监测计划。
与此同时,我们正在评估这些结果,并与卫生计划提供者研究预防或减少糖尿病并发症的有效性。
使用一种新的方法来嵌入日期,我们改进了模型性能的AUC为0.94。我们仍然在验证这个结果,并期望公布建议的方法与完整的论文报告。
References
[1] World Health Organization WHO et al. Global report on diabetes. World Health Organization, 2016.
[2] Colin D Mathers and Dejan Loncar. Projections of global mortality and burden of disease from 2002 to 2030. PLoS medicine, 3(11):e442, 2006.
[3] AndréaDBertoldi,PanosKanavos,GiovannyVAFrança,AndréCarraro,CesarAugustoOvieda Tejada, Pedro C Hallal, Alessandra Ferrario, and Maria Inês Schmidt. Epidemiology, man- agement, complications and costs associated with type 2 diabetes in brazil: a comprehensive literature review. Globalization and health, 9(1):62, 2013.
[4] Amine Farias Costa, Luísa Sorio Flor, Mônica Rodrigues Campos, Andreia Ferreira de Oliveira, Maria de Fátima dos Santos Costa, Raulino Sabino da Silva, Luiz Cláudio da Paixão Lobato, and Joyce Mendes de Andrade Schramm. Burden of type 2 diabetes mellitus in brazil. Cadernos de saude publica, 33(2), 2017.
[5] IDF et al. International diabetes federation diabetes atlas - 8th edition, 2017.
[6] Chandra Pandey, Zina Ibrahim, Honghan Wu, Ehtesham Iqbal, and Richard Dobson. Improving rnn with attention and embedding for adverse drug reactions. In Proceedings of the 2017 International Conference on Digital Health, DH ’17, pages 67–71, New York, NY, USA, 2017. ACM.
[7] B Jin, C Che, Z Liu, Shulong Zhang, Xiaomeng Yin, and XP Wei. Predicting the risk of heart failure with ehr sequential data modeling. IEEE Access, 2018.
[8] Edward Choi, Mohammad Taha Bahadori, Andy Schuetz, Walter F Stewart, and Jimeng Sun. Doctor ai: Predicting clinical events via recurrent neural networks. In Machine Learning for Healthcare Conference, pages 301–318, 2016.
[9] Arianna Dagliati, Simone Marini, Lucia Sacchi, Giulia Cogni, Marsida Teliti, Valentina Tibollo, Pasquale De Cata, Luca Chiovato, and Riccardo Bellazzi. Machine learning methods to predict diabetes complications. Journal of diabetes science and technology, page 1932296817706375, 2017.
[10] Zhouhan Lin, Minwei Feng, Cícero Nogueira dos Santos, Mo Yu, Bing Xiang, Bowen Zhou, and Yoshua Bengio. A structured self-attentive sentence embedding. CoRR, abs/1703.03130, 2017.
[11] Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S Corrado, and Jeff Dean. Distributed repre- sentations of words and phrases and their compositionality. In Advances in neural information processing systems, pages 3111–3119, 2013.
[12] Jacek M Bajor and Thomas A Lasko. Predicting medications from diagnostic codes with recurrent neural networks. ICLR Workshop 2017, 2016.
[13] Zachary C Lipton, David C Kale, Charles Elkan, and Randall Wetzel. Learning to diagnose with lstm recurrent neural networks. arXiv preprint arXiv:1511.03677, 2015.
[14] World Health Organization WHO. Use of Glycated Haemoglobin (HbA1c) in the Diagnosis of Diabetes Mellitus. World Health Organization, 2011.