使用 PyTorch 框架复现 Two-Stream 网络过程中遇到的问题
复现论文:《Two-Stream Convolutional Networks for Action Recognition》
完整代码:https://github.com/BizhuWu/Two-Stream-Network-PyTorch
(这是小吴同学第一次在 Github 上整理代码,可以的话,麻烦大家在 Github 上给个小星星好不好嘛~【试图撒娇.jpg】)
导入数据部分:LoadUCF101Data.py
1、隔 10 张计算一次光流(2.5 fps)导致有些视频光流数目不够 20 张,导致不能丢入网络
-
解决方案1:本想排除掉图片数小于 20 的视频,但统计了一下共有(2249 / 486166)个这样的视频,图片数小于 20 的视频的分布,发现不均匀,可能会导致某个类训练不充分,数据不够多。重新计算光流,让save_interval = 2,即fps = 12.5。

图:统计每个类中图片数小于 20 的视频数目
- 解决方案2:以最后生成大约24张左右的光流图为间隔?

2、训练过程中,在导入数据部分的代码出现错误,报错如下:

参考:https://blog.csdn.net/zcgyq/article/details/83085028
报错原因:classInd.txt 里类别的下标是从 1 开始的,我就直接读入了,但丢入网络的时候类别下标默认是从 0-100。
解决方案:原来我是用字典保存的:键是类标,值是类名。但 classInd.txt 里的类别是按顺序的,所以我就直接按顺序读入存在列表中,列表的索引是从 0 开始的。

3、数据集里不同图片是按不同的video存放的,没有区分训练集和测试集,只给出了trainlist01.txt和testlist01.txt两份文档,文档内容如下。所以需要自己整理出训练集和测试集。
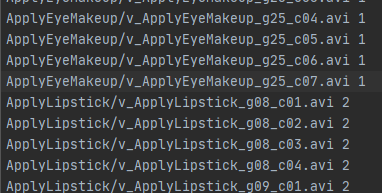
图:打印输出训练集 trainlist01.txt

图:打印输出测试集 testlist01.txt
解决方案:将训练集和测试集的视频名字读入各自的列表中。

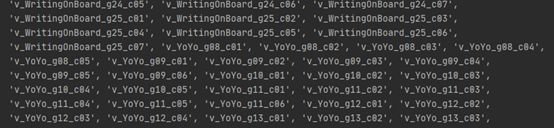
图:打印输出 TrainVideoNameList 的结果
在新建继承 dataset 的 UCF101Data 类的对象时,判断一下是否是训练集。然后再与当前读入某个类下的视频文件夹名列表做一个交集,只读入训练集/测试集所包含的视频名字对应的视频文件夹里的图片。

4、python两个 list 获取交集,并集,差集的方法
print list(set(a).intersection(set(b)))参考:https://www.cnblogs.com/jlf0103/p/8882896.html
5、如何stack多张光流图作为网络的输入?
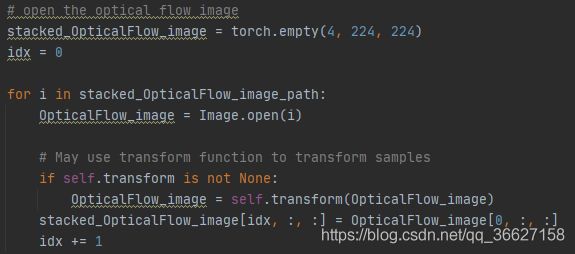
解决方案:首先,将随机下标的后连续 4 张(2 张 x 方向的光流图 和 2 张 y 方向的光流图)的文件名存入 stacked_OpticalFlow_image_path 的列表中。

再在__getitem__() 函数中,新建一个空的张量(tensor)stacked_OpticalFlow_image,tensor 的第一个维度就是打算 stack optical images 的图片张数。再打开 stacked_OpticalFlow_image_path 列表中的每一张图片,经过 transform 变化后,取每一张图片的第一个 channel 存入 stacked_OpticalFlow_image 中的某个 channel 里。
6、将两个 branch 的网络一起训练,就需要同时给出 RGB 和 optical flow 的图片作为输入。那如何将 RGB 和 optical flow 的图片同时喂入网络中呢?
解决方案:在 UCF101Data 类的 __init()__ 函数中,同时将 RGB 图片的路径和 stacked optical flow images 的路径列表 stacked_OpticalFlow_image_path 同时保存至 self.filenames 里

7、根据 glob 和 os.path 生成的所有图片路径是 Linux 格式的,在 Windows 下运行不了。
import glob
import os.path as osp
filenames = glob.glob(osp.join(root, str(i), '*.png'))os.path 连接的路径
![]()
是这样的:
![]()
解决方案:直接用加号连接字符串,用 os.listdir 列出当前目录下的所有文件

8、os.list() 的输出结果并不是按顺序的!!!
用这个函数的输出结果并不是按照某种特定顺序来的!!!
解决方案:
frame_list = os.listdir(single_OpticalFlow_video_path)
frame_list.sort(key=lambda x:int(x.split("_")[-2]))参考:https://www.cnblogs.com/jins-note/p/9550388.html
9、optical flow 图randomly crop的时候需要每张图都crop 相同的位置吗?
待解决
10、新建 tensor 的几种方法
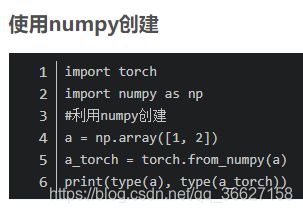

参考:https://blog.csdn.net/zjw18737392679/article/details/90723355
搭建网络模型部分:Two_Stream_Net.py
1、修改ResNet最后一层全连接的节点个数为类别数目:

2、光流图需要在输入的时候堆叠 4 张图片(2 张x方向的,2 张 y 方向的)。如何丢入原来输入通道仅为 3 的ResNet里?
![]()
参考:https://blog.csdn.net/qq_34419607/article/details/110325307
3、如何把两个 branch 连起来,一起更新 loss?
解决方案:原来是一个 RGBStreamNet,一个 OpticalFlowStreamNet。谢说可以 new 一个类 TwoStreamNet,实例化原来这两个类,包装起来。训练的时候只实例化 TwoStreamNet 这个类就好。

训练以及测试网络部分:trainTwoStreamNet.py
没有问题(棒!)
放至服务器上训练的部分:trainTwoStreamNet.sh
1、设置指定在哪一块GPU上训练:
参考:http://www.cocoachina.com/articles/34553