基于双重注意的递归神经网络在短期自行车共享使用需求预测中的应用
1.文章信息
《A Dual Attention-Based Recurrent Neural Network for Short-Term Bike Sharing Usage Demand Prediction》是2022年9月发表在期刊IEEE TRANSACTIONS ON INTELLIGENT TRANSPORTATION SYSTEMS上的一篇文章。
2.摘要
改进的网络技术和数据的开放性产生了大量基于轨迹的数据,基于轨迹的知识图有助于为智能运输系统(ITS)提供持续有效的开发和优化。自行车共享系统在交通规划、管理和智能交通系统的部署中变得越来越重要。因此,确定如何最好地利用轨迹数据来准确预测短期自行车共享使用需求至关重要。该研究提出了一种基于双注意机制的递归神经网络(RNN)模型来提取时空特征。注意机制能够确定和加权时间序列中数据的所有位置特征,以学习相互的相关性。文章中应用的方法可以有效地对轨迹数据的局部和全局特征依赖性进行自适应组合,以便有效地预测短期自行车共享使用需求的趋势。此外,该研究在时间序列数据的预处理中采用了随机行走机制来维护自行车站点之间的局部关系,这使得它更能适应不同站点的局部位置变化。最后,实验结果表明,该研究中的模型结构结合了注意力和随机行走机制,以实现更好的预测性能。
3.介绍
这项研究的主要贡献如下:
(1)该研究提出了一种基于双重注意的RNN来有效预测短期自行车共享使用需求的趋势。
(2)这项研究引入了随机行走机制来维持自行车站点之间的一些局部关系,从而为不同站点位置的局部变化提供了更好的适应性,并增强了模型的预测能力。
(3)该研究比较了一些典型算法,如ARIMA、SVR、MLP、RNN、LSTM和GRU,实验结果表明,提出的架构具有显著的效果。
(4)该研究针对注意机制、随机行走机制和不同预测时间的输入长度进行了消融实验。
4.自行车共享使用需求预测的模型
A. 问题定义
该研究结合台湾台北市 YouBike 公共自行车数据与天气资讯,预测短期共享单车使用需求 趋势。共享单车使用需求预测的问题可以表述如下。设oti表示第i个位置在第t个时间点的观测数据,oti ∈ RN×1。数据大小是自行车站数据和天气信息的组合,维度为 N。Oti = [ot−D+1i , ot−D+2i , . . . , oti ],其中Oti ∈ RN×D, 表示时间D内第i个观测位置的时间序列观测数据, D为时间序列的长度。为了有效利用数据的空间、时间和周期特征,将所有位置的观测值构造为时空输入数据,形式为 Xt = [Ot1, Ot2, . . . OtP] ∈ RP×D×N ,其中P代表观测站数。该研究旨在建立预测模型,给出时间点 t 过去时间长度 D 内所有观测位置的数据,以进行下一个时间点的共享单车使用需求预测。预测函数 f : X t → Y t+1。, f ([Ot1, Ot2, . . . OtP ]) → Y t+1, 其中 Yt+1 = [Y t+11 , Y t+12 , . . . Y t+1P ] ∈ RP×F , F 表示预测值的维度。Yti = [yt−D+1 i , yt−D+2 i , . . . , yti], yti ∈ RF×1, yti 表示第 i 个自行车站点在第 t 个时间点的共享单车使用需求。
B. 模型概述
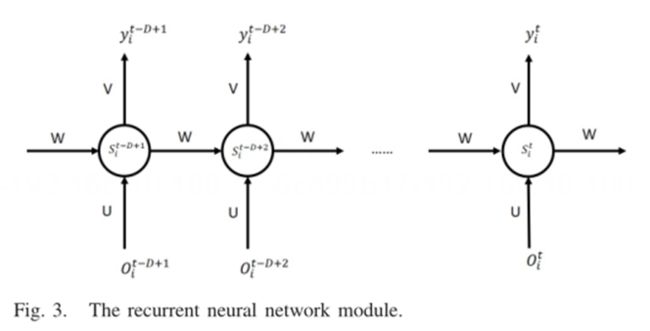
该研究提出了一种新的深度学习模型,用于短期自行车共享使用需求的趋势预测。提出的模型包括一个随机行走模块、三个RNN模块和一个注意机制模块。图2示出了该模型的整体架构。如图3所示,输入数据Xt通过随机行走机制被重新编码,然后进入RNN模块,以基于时间序列特征进行预测学习。U表示从输入层到隐藏层的权重, W是作为下一个权重的前一个隐藏层的值。Sti = U*Oti+W*St-1i . V表示从隐藏层到输出层的权重。然后,第一个RNN模块的输出值被输入到注意机制模块,用于空间特征提取和预测学习。最后,时间和空间信息被整合,最终预测由两个RNN模块完成。下面的小节详细描述注意机制模块和随机行走模块。
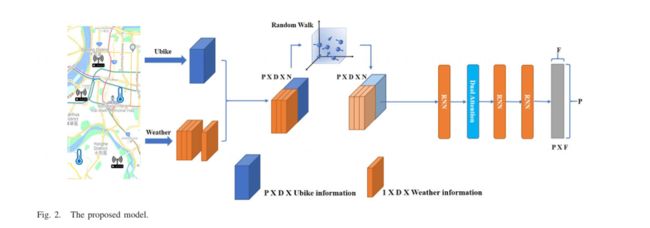
C. 双重注意机制
Fu等人提出了双注意网络(DANet)来提高场景分割的性能。DANet主要将图像信息分为空间位置 (Position)和图像通道(channel),空间特征可以通过权重和位置的整合来学习。频道上的特征可以通过考虑所有频道的特征映射来学习特征的相关性,并且最后,集成双重注意机制来改善特征性能。该工作还表明,尽管LSTM对时间序列的全局捕获具有有利的相关性,但它取决于长期记忆学习性能(长期依赖)。受DANet的启发,该研究将注意机制模块连接到RNN模块的输出值,如图4所示。每个站的预测值在图4的上部给出,并且生成三个特征向量Query(Q),Key(K),Value(V ),这些向量被转置和相乘以获得站之间的信息(空间)。类似地,在图4的下部中生成三个特征图Q、K、V,它们被转置和相乘以获得数据值之间的信息(周期性)。如图4中所示,两个输出向量分别代表不同特征之间的相互依赖关系,最终,这两个特征向量被整合为下一个RNN模块的输入。此外,在空间通道中捕获两个位置之间的空间依赖性(P × P特征图)。对于特定的特征,它被加权并由所有特征更新,并且权重是对应的两个位置之间的相似特征。因此,具有特征相似性的任何两个位置可以有助于相互促进,而不受距离的限制。在N × N特征映射中,每个高级通道映射可以被视为特定的数据响应,从而不同的数据响应相互关联,并且它们之间的相互依赖可以计算,以改进特定时间的特征表示。此外,提出的架构受Graph2Seq的启发。在数据被RNN网络模型计算之后,接着是注意模块,两者的组合可以被视为编码器。尽管注意机制可以加强站点之间的相关性,但是它忽略了较少使用的站点的信息。这种现象会导致低使用率站点的需求预测的准确性降低。因此,在提出的体系结构中,RNN模块被添加在注意模块之后。该RNN可以被视为解码器,其目的是检索被忽略的信息。

D. 随机行走机制
随机行走描述了数学空间中的一系列随机步骤(路径)。近年来,它在各个学科中越来越受欢迎,如数学和计算机科学,典型的例子包括链接预测、推荐、计算机视觉半监督学习和网络嵌入。在真实的生活中,股票价格的波动是一种众所周知的随机游走形式。在数学空间中,简单的随机行走是在规则格子上的随机行走,其中一个点可以按照一定的概率分布在另一个位置。当应用于特定空间时,节点之间的转移概率与它们之间的关联强度成正比。因此,本研究采用了随机行走的概念对数据进行编码,如算法1所示,以更好地适应不同站点位置的局部变化,从而在预测问题中保持自行车站点之间的一些局部关系。虽然这个概念可以简单地描述为输入数据的值根据给定的随机行走时间进行随机和轻微的调整,但是这种方法在实践中具有显著的效果,这可以从消融实验的结果中看出。

5.实验
A. 数据集和实验配置设置
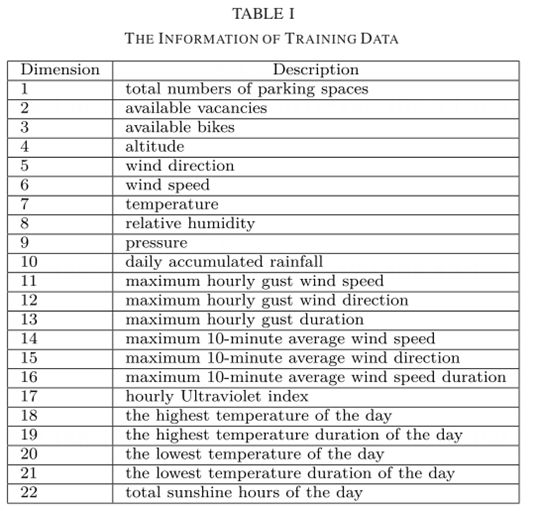
在资料集方面,文章采用了台北市优拜单车资料和气象资料。自行车共享系统提供了台北市总共389个自行车站点的信息,包括当前的停车位总数、可用空位和每个站点的可用自行车,这些信息是从Data Taipei获得的。本研究从2021年10月30日19:00到2021年11月14日19:00收集了大约15天的数据,台北气象站的实时更新数据从Opendata API每10分钟获取。本文中的天气信息包括高度(m)、风向 (度)、风速(m/s)、温度(摄氏度)、相对湿度(%)、站压(hPa)、日累计雨量(mm)、最大小时阵风风速(m/s)、最大- μm小时阵风风向(度)、最大小时阵风持续时间(hhmm)、该小时最大10分钟平均风速(m/s)、该小时最大10分钟平均风向、一天中的最高温度(摄氏度)、一天中的最高温度持续时间(hhmm)、一天中的最低温度(摄氏度)、一天中的最低温度(hhmm)以及一天中的总日照时间(小时)。每个气象站的气象信息主要基于最近的气象站的数据,而时间数据主要由更新的气象信息的频率处理。因此,为了合并天气数据,该研究采用了15天的总数据时间,并将Y ouBike的数据从每分钟重新组织为每10分钟。数据由389个站形成,每个站具有2160条数据(15天× 24小时* (60/10)),其中每条数据是22维的,如表I所示,并且根据每个站的使用率(每个站的可用空位/总停车位的数量)来计算预测。
该研究的实验设备规格为CPU X86 _ 64 Intel(R)Core(TM)i5-10400 f CPU @ 409 2.90 GHz,GPU GTX3080 12G。在RNN、LSTM、GRU、410和本研究中的其他模型中,采用sigmoid函数作为激活函数。批量大小为413×1024。夏等人提到在随机游走中用小值做变化,可以突出一些重要值,掩盖不必要的值。本实验中输入数据值的精度为1e-2。因此,在随机行走的机制设置中,迭代被设置为418×1000,编码值为0.01。训练集和测试集的数据比为9:1。
Attention
欢迎关注微信公众号《当交通遇上机器学习》!如果你和我一样是轨道交通、道路交通、城市规划相关领域的,也可以加微信:Dr_JinleiZhang,备注“进群”,加入交通大数据交流群!希望我们共同进步!