极智AI | T4 上商汤 OpenPPL vs TensorRT7 vs TensorRT8 测评
本文对商汤 OpenPPL 和 英伟达 TensorRT7、TensorRT8 在 T4 平台上对一些经典网络进行了性能测试对比。
文章目录
-
- 1、小试牛刀
- 2、测评姿势
- 3、数据分析
商汤 OpenPPL 传送:点击到达OpenPPL
英伟达 TensorRT 传送:点击到达TensorRT
我的测试环境:NVIDIA TESLA T4、CUDA11.3、Cudnn8.2.1
关于 ppl.nn 的量化说几句,查阅 github 上沟通得到信息:ppl.nn 输入 onnx model 精度为 fp32,执行前会自动进行精度转换,目前在 CUDA 上仅支持 fp16(也只是针对 conv 和 gemm),所以意思是我们在执行 ./pplnn 传参时不需要传精度相关的配置。不过这里有一点比较迷,看 pplnn.cc 源码中对于 ./pplnn 的传参保留有 --quantization,猜测可能用于Int8量化,传送类似 TRT int8 校准表的东西吧。
![]()
1、小试牛刀
拿官方 ppl.nn中的示例 demo 试试(商汤开放了两个框架:ppl.nn 和 ppl.cv,我看了一下 nn 主要用于深度学习模型推理,cv 主要图像预处理)。
demo 在 ppl.nn/tests/testdata/conv.onnx,这是只有一个卷积算子的model,如下:

可以看到 input_data Layout 是(1, 3, 4, 4),用 ppl.nn 对如上的 conv 算子进行一波测试:
./pplnn-build/tools/pplnn --onnx-model ./tests/testdata/conv.onnx --in-shapes 1_3_4_4 --dims 1_3_4_4 --warmuptimes 100 --runningtimes 100
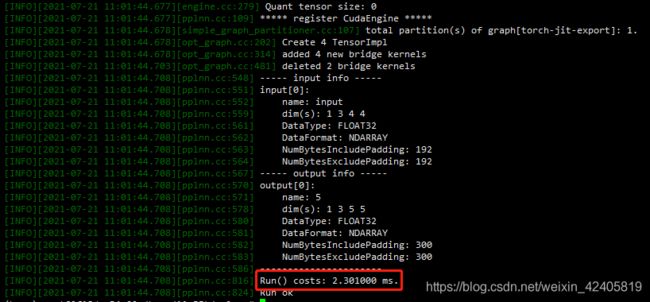
如上测得 ppl.nn 的推理耗时为:0.0230100 ms
接下来我们测试一波 TRT7.2:
# 将 conv.onnx 转换为 tensorrt engine
trtexec --onnx=./tests/testdata/conv.onnx --fp16 --saveEngine=trtEngine/conv.engine
![]()
开测:
trtexec --loadEngine=trtEngine/conv.engine
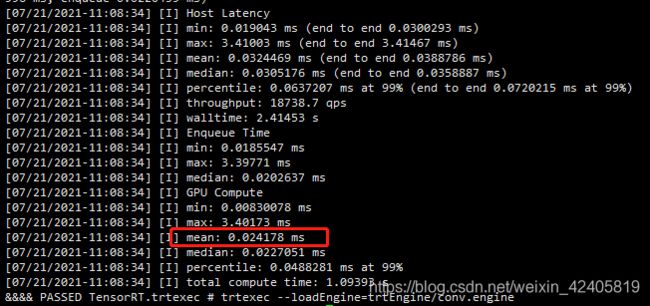
看下 TRT 的推理时间:0.024178 ms (看样子 ppl.nn 还可以啊)
接下来看看一些经典网络的 PK。
2、测评姿势
以下所有测评的网络均来自 pytorch model zoo,ppl.nn 和 tensorrt 的测试方法如1中介绍。
我转换 onnx 的姿势是:torchvision 加载 pytorch model zoo 中的模型,利用 torch.onnx.export 导出 onnx,这个时候需要注意指定 opset 版本,我测试了 opset 为 11 或12 都可以,不然你在用 ppl.nn 推理的时候可能会遇到下面的报错:

我的 ppl 的执行姿势是:
pplnn-build/tools/pplnn --onnx-model ./xxx.onnx -–in-shapes 1_3_224_224 --dims 1_3_224_224 --warmuptimes 400 --enable-profiling
TRT7 的执行姿势是:
TensorRT-7.2.1.6/bin/trtexec --loadEngine=./xxx_TRT7.engine
TRT8 的执行姿势是:
TensorRT-8.0.1.6/bin/trtexec --loadEngine=./xxx_TRT8.engine
3、数据分析
下面给出我测评的具体数据:
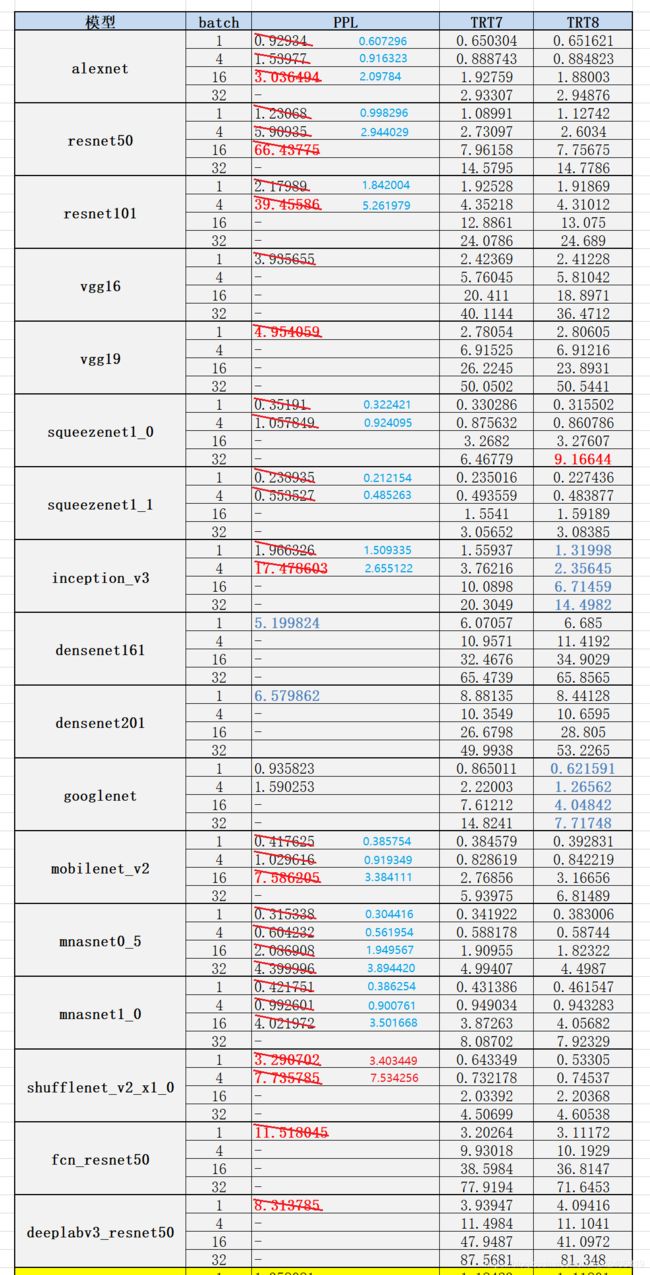
个人分析:
(1)从测试数据可以看出,TRT8 应该对 inception 结构的推理进行了优化,对于googlenet 和 inception_v3 的推理性能,TRT8 比 TRT7 提升一倍;
(2)TRT8 相对于 TRT7,测试的网络中,除 inception 结构网络外,其他网络算子应该没做更多优化,性能相当;
(3)OpenPPL 对于密集连接网络 densenet 进行了更好的优化,densenet的推理性能相比TRT都要更好;
以上只是我个人的测试数据及分析,若有不妥的地方欢迎指正~
扫描下方二维码即可关注我的微信公众号【极智视界】,获取更多AI经验分享,让我们用极致+极客的心态来迎接AI !
