Dimensionality Reduction_ A Comparative Review
Dimensionality Reduction_ A Comparative Review
阅读提示:此文是一篇综述,详细讨论了文章发布之前的一些非线性降维算法,并将它们与PCA,LDA进行了比较,包括理论比较与实验结果比较,非常适合学习图像处理的人阅读了解经典的降维算法。以下内容大体为原文翻译,是笔者原为课堂论文汇报准备的材料内容,存在部分文字翻译错误请自行忽略,相关ppt也会上传,ppt较此文错误更少,图文整理方式更佳,更适合阅读,有需要可自行取用。
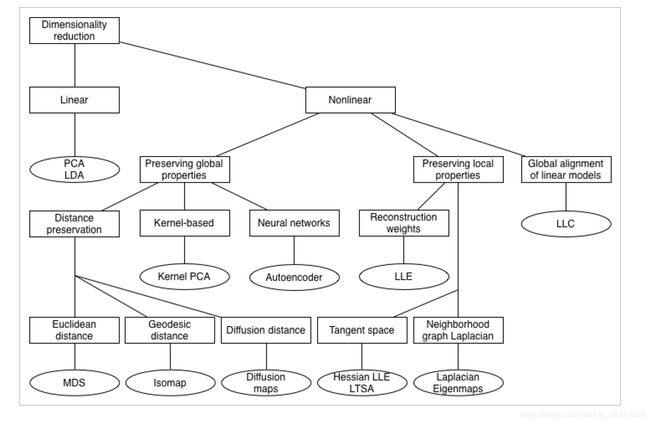
降维技术
- 摘要
- 一、引言
- 二、降维
- 三,减少尺寸的线性技术
-
- 1)PCA
- 2)LDA
- 四、降维的非线性技术
-
- A. 全局非线性
-
- 1)MDS
- 2) ISOMAP
- 3) KPCA
- 4)DM
- 5) 多层自动编码器
- B.全局非线性技术
-
- 1)LLE
- 2)LEM
- 3)HLLE
- 4)LTSA
- 五、技术特点
-
- A. 一般属性
- B. 计算复杂度
- C. 样本外扩展
- D. 监督
- 六、 实验
-
- A. 实验设置
- B. 人工数据集
- C. 自然数据集
- 七.讨论
- 八.总结
摘要
近年来,人们对非线性降维的兴趣日益浓厚。这导致提出了各种新的非线性技术的建议,这些技术据称能够处理复杂的低维数据。这些技术在人工任务(例如Swiss Roll任务)上表现优于传统的线性技术。迄今为止,降维技术尚未以系统的方式进行比较。在本文中,我们讨论和比较了十种用于降维的非线性技术。我们研究了非线性技术在人工和自然任务上的降维性能,并将它们与两种主要线性技术的性能进行比较:(1)主成分分析和(2)线性判别分析。实验表明,用于降维的非线性技术在选定的人工任务上表现良好,但在许多实际任务中却不优于线性技术。本文的结论是,这些结果表明,尽管具有理论上的能力可以找到复杂的低维嵌入物,但用于降维的非线性技术在实际任务中仍无法胜过传统的线性技术。我们预见到,用于减少尺寸的非线性技术的性能将通过开发新技术来提高,这些新技术通过许多单独的线性模型来代表流形的整体结构。
一、引言
降维是将高维数据转换为降维的有意义的表示。理想地,简化表示具有与数据的固有维数相对应的维数。数据的固有维数是说明观察到的数据属性所需的最少参数数[24]。降维在许多领域都很重要,因为它通过减轻维数的诅咒和其他高维空间的不希望有的特性,促进了高维数据的分类,可视化和压缩[40]。
近年来,提出了许多用于降维的非线性技术[4],[20],[34],[45],[59],[63],[70],[68],[83] ]。这些技术具有处理复杂非线性数据的能力,因此构成了用于降维的传统线性技术,例如主成分分析(PCA)和线性判别分析(LDA)。特别是对于现实世界的数据,非线性降维技术可能会提供一个优势。先前的研究表明,在高度非线性的人工任务上,非线性技术的性能优于线性方法。例如,瑞士卷数据集包括一组点,这些点位于三维空间内的螺旋状二维流形上。大量的非线性技术完全能够找到此嵌入,而线性技术则无法做到这一点。与在人工数据集上取得的成功相反,非线性降维技术在自然数据集上的成功应用很少。同样,不清楚各种降维技术在人工和自然任务上的性能在多大程度上有所不同。
本文提出了线性和非线性降维技术的系统比较研究。它对降维技术进行了理论和实证评估。它研究了线性技术PCA [36]和LDA [23],以及十种非线性技术:多维缩放(MDS)[15],[43],Isomap [69],[70],内核PCA [52],[63] ,扩散图[45],[53],多层自动编码器[19],[34],局部线性嵌入(LLE)[59],拉普拉斯特征图[4],Hessian LLE [20],局部切线空间分析(LTSA) [83]和本地线性协调(LLC)[68]。我们的比较评审和评估包括除自组织图[42]及其概率扩展GTM [9]以外的所有降维主要技术,因为我们认为这些技术是聚类技术。我们也没有讨论诸如ICA的盲源分离技术[5]。由于篇幅所限,我们的比较研究并未涵盖许多非线性技术,其中大多数是十种已审查的降维技术的变体或扩展。未讨论的技术包括主曲线[13],广义判别分析[3],核图[66],最大方差展开[78],共形特征图[64],局部性保留投影[30],线性局部切线空间对齐[81],随机邻近嵌入[1],FastMap [22],测地零空间分析[11],以及基于线性模型整体对齐的各种方法[10],[58],[76]。
本文其余部分的概述如下。在第二部分中,我们给出了降维的正式定义。第三节简要讨论了减少维数的两种线性技术。随后,第四节描述并讨论了十种用于降维的非线性技术。第五节评估了所有关于理论特征的技术。然后,在第六节中,我们对对人工和自然数据集进行降维的技术进行了经验评估。第七节讨论了实验结果,并指出了非线性技术用于降维的弱点和改进点。第八节总结了将非线性降维技术应用于现实世界任务的附加价值。
二、降维
(非线性)降维的问题可以定义如下。假设我们有一个n×D矩阵X,该矩阵X由n个维数为D的数据向量xi组成,并且该数据集的固有维数为d(其中d
三,减少尺寸的线性技术
在第二节中,我们正式定义了降维问题,并提出了降维技术的分类法。在分类学中,将维数减少的技术分为线性技术和非线性技术。在本节中,我们讨论降低维数的两种主要线性技术:
(1)PCA和(2)LDA。我们将在第III-.1小节和第III-.2小节中讨论PCA和LDA。在整个论文中,我们用xi表示高维数据点,其中xi是D维数据矩阵X的第i行。xi的低维对应物用yi表示,其中yi是d的第i行。维数据矩阵Y。
1)PCA
PCA:主成分分析(PCA)[36]构建了数据的低维表示,它描述了数据中尽可能多的差异。这是通过找到数据降维的线性基础来完成的,其中数据中的变化量最大。
用数学术语,PCA试图找到使MT covX-X M最大化的线性映射M,其中covX-X是零均值数据X的协方差矩阵。可以证明该线性映射是由d形成的。零均值数据2的协方差矩阵的主特征向量(即主成分)。因此,PCA解决了本征问题。

求解d个主特征值的特征问题。数据点xi的低维数据表示yi通过将它们映射到线性基础M上来计算,即Y =(X-X′)M。
PCA已成功应用于众多领域,例如面部识别[74]和硬币分类[37]。 PCA的主要缺点是协方差矩阵的大小与数据点的维数成正比。结果,特征向量的计算对于非常高维的数据可能是不可行的。近似方法,例如Simple PCA [56],通过应用迭代的Hebbian方法来解决此问题,以便估计协方差矩阵的主要特征向量。
2)LDA
LDA:线性判别分析(LDA)[23]试图最大化属于不同类的数据点之间的线性可分离性。与本文研究的大多数其他降维技术相比,LDA是一种监督技术。
LDA找到一个线性映射M,该映射在数据的低维表示中最大化线性类的可分离性。在LDA中用来表示线性类别可分离性的标准是类别内散布Sw和类别间散布Sb,它们的定义是

其中Pc是类别标签c的类别优先级,covXc-X¯c是分配给类别c 属于C的零平均数据点xi的协方差矩阵(其中C是可能的类别的集合),而covX-X¯是 零均值数据X的协方差矩阵。LDA通过找到使所谓的Fisher最大化的线性映射M来优化数据低维表示中类内散点Sw和类间散点Sb之间的比率。 可以通过在要求d <| C |下计算(d)的d个主要特征向量来实现这种最大化。 X中数据点的低维数据表示Y可以通过将它们映射到线性基础M上来计算,即Y =(X-X′)M。
LDA已成功应用于大量分类任务。 成功的应用包括语音识别[28]和文档分类[73]。
四、降维的非线性技术
在第三节中,我们讨论了建立和很好理解的两种主要的降维线性技术。相反,大多数用于降维的非线性技术是最近提出的,因此研究较少。在本节中,我们讨论了十种用于降维的非线性技术。降维的非线性技术可以分为三种主要类型3:(1)试图以低维表示形式保留原始数据的全局属性的技术,(2)试图以低维表示形式保留原始数据的局部属性的技术低维表示,以及(3)对许多线性模型进行全局对齐的技术。在第IV-A小节中,我们讨论了五种用于降维的全局非线性技术。 IV-B小节介绍了用于降低维数的四种局部非线性技术。第IV-C节介绍了一种对多个线性模型进行全局对齐的方法。
A. 全局非线性
用于降维的全局非线性技术是试图保留数据的全局属性的技术。 本小节介绍了五种用于降维的全局非线性技术:(1)MDS,(2)Isomap,(3)内核PCA,(4)扩散图和(5)多层自动编码器。 该技术在第IV-A.1至IV-A.5小节中讨论。
1)MDS
MDS:多维缩放(MDS)[15],[43]代表非线性技术的集合,该技术将高维数据表示映射到低维表示,同时尽可能保留数据点之间的成对距离 。 映射的质量以应力函数表示,应力函数是数据的低维和高维表示中成对距离之间误差的度量。 应力函数的两个重要示例是原始应力函数和Sammon成本函数。 原始应力函数定义为

Sammon 成本函数不同于原始应力函数,因为它更加强调保留原本很小的距离。可以使用各种方法对应力函数进行最小化,例如对距矩阵的特征分解、偶联梯度方法或伪牛顿方法 [15]。
MDS广泛用于数据的可视化,例如,在fMRI分析和分子建模[75]中。MDS 的普及导致了 SPE [1]、SNE [33] 和FastMap [22]等变体的建议。
2) ISOMAP
Isomap:多维缩放在许多应用中被证明是成功的,但事实是,它基于欧氏距离,没有考虑到相邻数据点的分布。如果高维数据位于弯曲流形上或附近(如瑞士卷数据集 [69])中,MDS 可能会将两个数据点视为近点,而它们在流形上的距离比典型的点间距离大得多。 Isomap [69] 是一种通过尝试在数据点之间保持对位测地线(或曲线)距离来解决此问题的技术。测地距离是多面体上测量的两个点之间的距离。
在Isomap [69] 中,数据点之间的测地线距离xi 是通过构造邻域图 G计算的,其中每个数据点 xi都与数据集 X中的 k 最近邻居 xij 相连。图形中两个点之间的最短路径对这两个点之间的测地测量距离形成良好的(过)估计值,并且可以使用 Dijkstra 的最短路径算法/基于贪心算法的一种最短路径算法/轻松计算。计算 X 中所有数据点之间的测地测量距离 ,从而形成一对地测距离矩阵。y通过对结果的距离矩阵应用多维缩放(参见第 IV-A.1 节),计算低维空间 Y中的数据点 yi低维表示 x i。
Isomap算法的一个重要弱点是其拓扑不稳定性 [2]。Isomap 可能在邻域图 G 中构造错误连接G。这种短路[47]会严重损害Isomap的性能。提出了几种方法来克服短路问题,例如,在最短路径算法 [14] 中删除总流量较大的数据点,或者删除违反邻域图 [62] 局部线性的最近邻域。此外,Isomap 可能患有流形中的孔,这个问题可以通过用孔撕开流形来解决 [47]。 Isomap的第三个缺点是,如果流形是非凸 [70],它可能会失败。尽管存在这些弱点,Isomap 仍成功地应用于木材检测 [54] 和生物医学数据可视化等任务 [49]。
3) KPCA
核PCA:核PCA(KPCA)是使用核函数[63]构建的高维空间中传统线性PCA的重新配方。近年来,使用"核技巧"重新制定线性技术,提出了诸如核回归和支持向量机等成功技术的建议[65]。内核PCA包含内核矩阵的主特征向量,而不是协方差矩阵的特征向量。 由于内核矩阵类似于使用内核函数构造的高维空间中数据点的乘积,因此在内核空间中对传统PCA的重新编写非常简单。PCA在内核空间中的应用为内核PCA提供了构建非线性映射的属性。
内核 PCA 计算数据点 xi的内核矩阵K 。内核矩阵中的定义为
kij = κ(xi,xj) (7)
其中k是一个内核函数[65]。使用条目的以下修改对内核矩阵K中心化
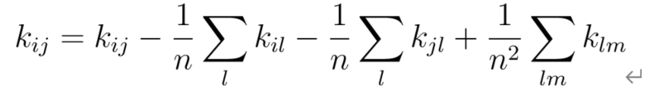
中心化操作对应于减去传统 PCA 中要素的平均值。它确保内核函数定义的高维空间中的要素是零均值。随后,计算矩阵的主要特征向量vi。 可以证明,协方差矩阵i的特征向量(在由构成的高维空间中)是核矩阵vi的特征向量的缩放版本。
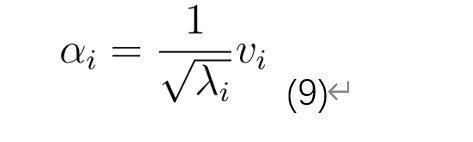
为了获得低维数据表示,数据被投影到协方差矩阵的特征向量上。投影的结果(即低维数据表示形式 Y))由
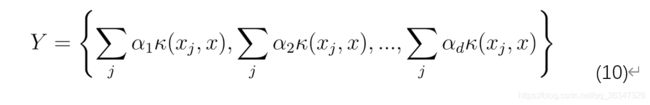
其中α是内核矩阵计算中使用的内核函数。由于内核PCA是一种基于内核的方法,内核PCA执行的映射高度依赖于内核函数*的选择。内核函数的可能选择包括线性内核(使内核 PCA 等于传统的 PCA)、多面内核和高斯内核 [65]。
内核 PCA 已成功应用于语音识别 [50]和新颖检测 [35]。内核 PCA 的一个重要缺点是内核矩阵的大小与数据集中的实例数是平方的。提出了解决此缺点的方法在[72]。
4)DM
扩散图:扩散图(DM)框架[45],[53]源自动力学系统领域。 扩散图基于在数据图上定义马尔可夫随机游动。 通过执行多个时间步长的随机游走,可以获得数据点附近的度量。 使用该措施,定义了所谓的扩散距离。 在数据的低维表示中,尽可能保持成对的扩散距离。
在扩散图框架中,首先构建数据图。 使用高斯核函数计算图中边缘的权重,从而得出带有项的矩阵W
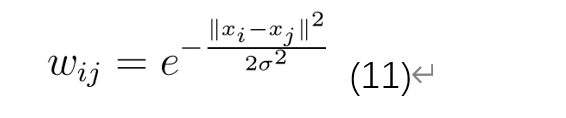
其中 d表示高斯方的方差。随后,矩阵 W的规范化以使其行加起来为 1的方式执行。通过这种方式,矩阵 P(1) 变为

由于扩散图源自动态系统理论,因此生成的矩阵P(1) (被认为是定义动态过程的正向过渡概率矩阵的 Markov 矩阵。因此,矩阵 P(1)表示在(单个时间步长中从一个数据点过渡到另一个数据点的概率。 t时步P(t)的正向概率矩阵由(P(1))t给出。使用随机向前走概率 ,扩散距离为
定义者
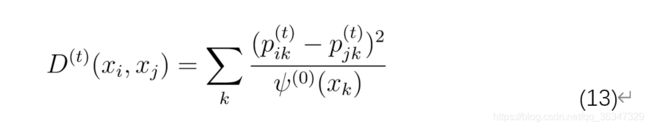
在方程中,φ(xi) 用于将更多权重归因于具有高权重的图形部分密度。它由 定义,其中mi是i 定义的节点x的度,mi = Σ(j) pji。从公式13可以看出,具有高正向过渡概率的数据点对具有较小的扩散距离。扩散距离背后的关键思想是它基于穿过图形的许多路径。 在数据Y的低维表示中,扩散图试图保留扩散距离。 使用关于随机游走的谱理论,可以证明保留扩散距离的低维表示Y是由随机向量的d个非平凡本征向量形成:
P(t)Y = λY (14)
因为图是完全连接的,所以最大特征值是微不足道的(即lambd1 = 1),因此其特征向量v1被丢弃。 低维表示Y由接下来的d个主要特征向量给出。 在低维表示中,特征向量通过其对应的特征值进行归一化。 因此,低维数据表示为
Y = {λ2v2,λ3v3,…,λd+1vd+1} (15)
5) 多层自动编码器
多层自动编码器:多层编码器是具有奇数个隐藏层[19],[34]的前馈神经网络。中间的隐藏层有d个节点,输入和输出层有D个节点。图2中示意性地显示了一个自动编码器的示例。对网络进行了训练,以最大程度地减少网络输入和输出之间的均方误差(理想情况下,输入和输出相等)。在数据点xi上训练神经网络会导致一个网络,其中中间隐藏层给出了数据点的d维表示,该维表示在X中保留了尽可能多的信息。当数据点xi用作输入时,可以通过提取中间隐藏层中的节点值来获得低维表示yi。如果在神经网络中使用线性激活函数,则自动编码器与PCA非常相似[44]。为了使自动编码器学习高维和低维数据表示之间的非线性映射,通常使用S型激活函数。
多层自动编码器通常具有大量连接。因此,反向传播方法收敛缓慢,并且很可能陷入局部极小值。在[34]中,通过使用受限玻尔兹曼机(RBM)[32]执行预训练克服了这一缺点。 RBM是神经网络,其单位是二进制的和随机的,并且其中隐藏的单位之间不允许连接。使用基于模拟退火的学习方法,RBM可以成功地用于训练具有许多隐藏层的神经网络。一旦执行了使用RBM的预训练,就可以使用反向传播对网络权重进行微调。作为一种替代方法,遗传算法[57]可用于训练自动编码器
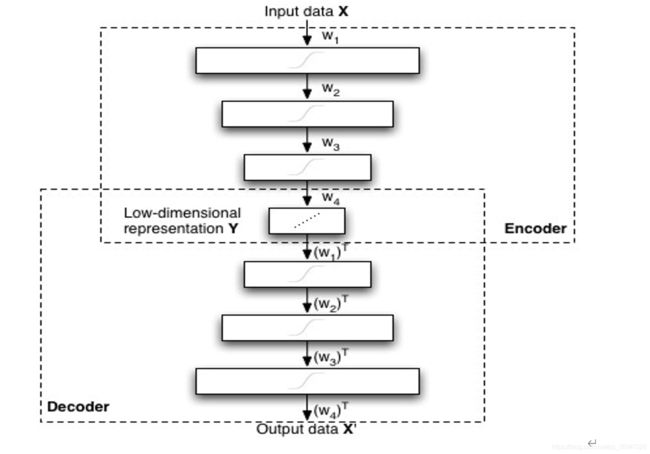
图2. 自动编码器的原理图结构。
B.全局非线性技术
IV-A小节介绍了五种降维技术,这些技术试图保留数据的整体属性。相反,用于减少维数的局部非线性技术仅基于保留数据点周围小邻域的属性。本小节介绍了用于降维的四种局部非线性技术:(1)LLE,(2)Laplacian特征图,(3)Hessian LLE和(4)子IV-B.1至IV-B.4中的LTSA。这些技术的核心主张是,通过保留数据的局部属性,还可以保留数据流形的全局布局。本质上,可以将用于降维的本地技术视为内核PCA的特定本地内核功能的定义。因此,可以在内核PCA框架[6],[29]中重写这些技术。在本文中,我们不再进一步阐述降维局部方法与内核PCA之间的理论联系。
1)LLE
LLE:局部线性嵌入(LLE)[59]是一种用于降维的局部技术,与Isomap相似,因为它构造了数据点的邻域图表示。与Isomap相比,它尝试仅保留数据的局部属性,从而使LLE对短路的敏感性低于Isomap。此外,保留局部特性可成功嵌入非凸形流形。在LLE中,通过将数据点写为其最近邻居的线性组合来构造数据流形的局部属性。在数据的低维表示中,LLE尝试尽可能保持线性组合中的重构权重。
LLE通过将数据点写为其最接近的k个邻居xij的线性组合Wi(所谓的重构权重)来描述数据点xi周围的流形的局部属性。因此,LLE通过数据点xi及其最近的邻居拟合超平面,从而假定流形是局部线性的。局部线性假设意味着数据点xi的重构权重Wi对于平移,旋转和重新缩放不变。由于这些变换的不变性,超平面到较低维空间的任何线性映射都将重建权重保留在较低维空间中。换句话说,如果低维数据表示保留了流形的局部几何形状,则从高维数据表示中的邻居重构数据点xi的重构权重Wi也将从低维数据中的邻居重构数据点yi表示。结果,找到d维数据表示Y等于最小化成本函数
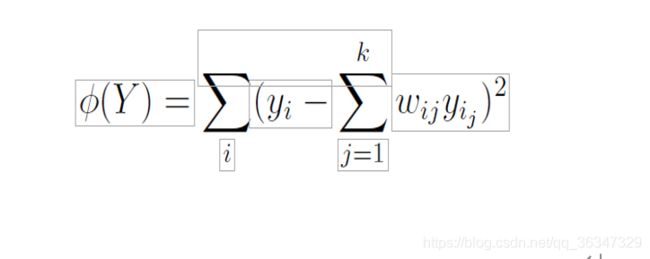
可以表明通过计算对应于(I -W)的最小d个非零特征值的特征向量来找到使该成本函数最小的低维表示yi的坐标。在这个公式中,I是n×n单位矩阵。 LLE已成功应用于例如超分辨率[12]和声源定位[21]。但是,也有一些实验研究报告了LLE的性能较弱。在[49]中,据报道LLE甚至在简单的合成生物医学数据集的可视化中均失败。在[39]中,据称LLE在感知运动动作的推导方面比Isomap差。一种可能的解释是,当LLE面对带有孔的流形时,存在困难[59]。
2)LEM
拉普拉斯特征图:与LLE相似,拉普拉斯特征图通过保留流形的局部属性来发现低维数据表示[4]。在拉普拉斯特征图中,局部属性基于相邻邻居之间的成对距离。拉普拉斯特征图可计算数据的低维表示,其中数据点与其k个最近邻居之间的距离最小。这是以加权的方式完成的,即在低维数据表示中数据点与其第一近邻之间的距离比该数据点与其第二近邻之间的距离对成本函数的贡献更大。使用频谱图理论,将成本函数的最小化定义为一个本征问题。
拉普拉斯特征图算法首先构造一个邻域图G,其中每个数据点xi连接到它的k个最近邻居。对于图G中所有通过一条边连接的点xi和xj,使用高斯核函数(请参见公式11)计算边的权重,从而得出稀疏的邻接矩阵W。在低维表示yi的计算中,最小化的成本函数由下式给出
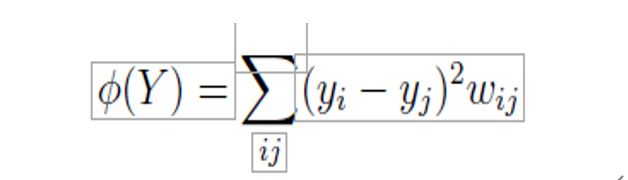
在成本函数中,大权重wij对应于数据点xi 和 xj之间的小距离。因此,其低维表示yi和yj之间的差异对成本函数有很大贡献。因此,在低维表示中,高维空间中的附近点在低维表示中更紧密地结合在一起。图W的度矩阵M和图拉普拉斯算子L的计算允许将最小化问题表述为特征问题。 W的度矩阵M是对角矩阵,其项是W的行总和(即mii =)。图拉普拉斯算子L由L = M-W计算得出。 可以证明以下成立
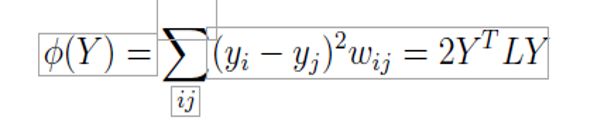
对于d个最小的非零特征值。对应于最小非零特征值的d个特征向量vi形成了低维数据表示Y。
拉普拉斯特征图已成功应用于例如聚类[80]和人脸识别[31]。
3)HLLE
Hessian LLE:Hessian LLE(HLLE)[20]是LLE的一种变体,它在将低维数据集嵌入到低维空间中的情况下,将低维数据流的“弯曲度”最小化是局部等距的。这是通过矩阵H的特征分析完成的,该矩阵描述了数据点周围流形的弯曲度。通过每个数据点上的局部Hessian测量流形的弯曲度。局部Hessian在数据点的局部切线空间中表示,以便获得局部Hessian的表示,该表示不随数据点位置的不同而变化。可以表明,可以通过对H进行特征分析来找到低维表示的坐标。
Hessian LLE首先使用欧几里得距离为每个数据点xi标识k个最近邻居。在附近,假定流形的局部线性。因此,可以通过将PCA应用于点k的最近邻xij来找到点xi处的局部切线空间的基础。换句话说,对于每个数据点xi,确定点xi处的局部切线空间的基础。
通过计算协方差矩阵的d个主要特征向量M = {m1,m2,…,md} cov xij -xij(均)。 注意,以上要求k d。 随后,计算局部切线空间坐标中在点xi处的流形的Hessian估计量。 为了做到这一点,设一矩阵Zi,该矩阵Zi包含(在列中)直到第d阶的M的所有叉积(包括具有一的列)。 通过对矩阵Zi进行Gram-Schmidt正交归一化来对矩阵Zi进行归一化。 现在,通过矩阵Zi的最后d(d + 1)列的转置来给出切线Hessian Hi的估计。 使用局部切线坐标中的Hessian估计量,可以构造带有条目的矩阵H
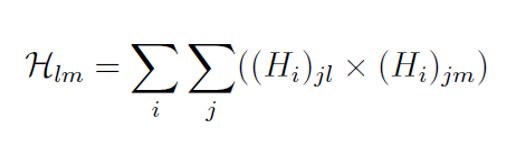
矩阵H表示关于高维数据流形的曲线的信息。对H进行特征分析以找到最小化流形弯曲度的低维数据表示形式。选择对应于H的d个最小非零特征值的特征向量,并形成矩阵Y,该矩阵Y包含数据的低维表示。
4)LTSA
LTSA:类似于Hessian LLE,局部切线空间分析(LTSA)是一种使用每个数据点的局部切线空间描述高维数据的局部属性的技术[83]。 LTSA基于以下观察结果:如果假设流形的局部线性,则存在从高维数据点到其局部切线空间的线性映射,并且存在从对应的低维数据点到对象的切线空间的线性映射。相同的局部切线空间[83]。 LTSA尝试以这种方式对齐这些线性映射,以使它们从低维表示形式构造流形的局部切线空间。换句话说,LTSA同时搜索低维数据表示的坐标,并搜索低维数据点到高维数据的局部切线空间的线性映射。
与Hessian LLE类似,LTSA从数据点xi处的局部切线空间的计算基础开始。这是通过在与数据点xi相邻的k个数据点xij上应用PCA来完成的。从xi附近到局部切线空间theti的映射Mi。局部切线空间i的一个特性是,存在从局部切线空间坐标thetij到低维表示yij的线性映射Li。使用局部切线空间的此属性,LTSA执行以下最小化。
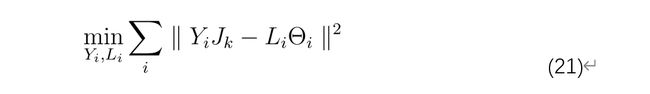
其中 Jk是大小为k [65]的中心矩阵。可以看出,最小解是由与B的d个最小非零特征值对应的对齐矩阵 B的特征向量形成的。对齐矩阵B的项是通过迭代求和(对于所有矩阵Vi和 从bij = 0对于8ij(对于所有矩阵Vi,并从bij = 0 开始 任意ij))
BNiNi = BNiNi + Jk(I − ViViT )Jk (22)
其中 Ni 是一个选择矩阵,其中包含数据点 x i 的邻域的索引。随后,通过计算与对称矩阵 的d个最小非零特征向量的特征向量来获得低维表示Y。在[71]中,报道了LTSA在微阵列数据中的成功应用。
C. 线性模型的对齐
在前面的子节中,我们讨论了通过保留数据的全局或局部属性来计算低维数据表示的技术。执行线性模型全局对齐的技术计算多个线性模型,并通过对齐这些线性模型构造低维数据表示。在第IV-C.1分节中,我们提出一种这样的技术,即,LLC。
LLC:本地线性协调 (LLC) [68] 计算因子分析的混合物,然后对线性模型的混合物进行全局对齐。此过程包括两个步骤:(1) 通过期望最大化 (EM) 算法计算数据上的因子分析器混合物,(2) 对齐线性模型,以便使用 LLE 变体获取低维数据表示。在[11]中提出了一种称为多张图表的类似技术。
LLC 首先使用 EM 算法 [25] 构造 m 因子分析仪的混合物。因子分析器的混合物输出m 本地数据表示 zij 和相应的责任 rij 每对应了每个数据点xi(其中 j 属于{1,…m})。责任 rij 描述了数据点 xi 与线性模型 j的对应程度,并满足sigemajrij = 1。使用线性模型和相应的责任计算责任加权数据表示uij = rijzij。 责任加权数据表示uij存储在n××mD块矩阵U中。基于 U和M = (I + W)T (I - W)给出的矩阵 M 进行线性模型的对齐。在这里,矩阵W包含 LLE 计算的重建权重(参见子节 IV-B.1),I表示nxn 单位矩阵。LLC通过解决广义特征问题来对齐线性模型
Av = λBv (23)
以此求解d个最小的非零特征值。 在等式中,A是M的转置U的乘积,B是U的乘积。特征向量vi形成矩阵L,可以证明该矩阵定义了从责任加权数据表示U到底层低权重的线性映射。 因此,低维数据表示通过计算Y = UL获得。
五、技术特点
在前面两节中,我们概述了降维维度技术概述。本节通过四种理论特征来评估这些技术。首先,我们评估技术的四个一般属性和基本假设(第五-A节)。其次,我们评估技术的计算复杂性及其内存复杂性(第 V-B 节)。第三,讨论了技术的样本外扩展(第五-C小节)。第四,我们通过维度减少技术来评估类标签信息的利用(第五-D小节)。在所有评估中,我们不会考虑 MDS,因为 MDS 不代表一个,而是度量和非度量技术的集合。
A. 一般属性
表一列出了与技术相关的四个常规属性:(1) 技术是否假定数据被采样密集,(2) 邻近度是否可以用作输入而不是数据本身,(3) 是否是凸函数(4)是否必须优化的自由参数
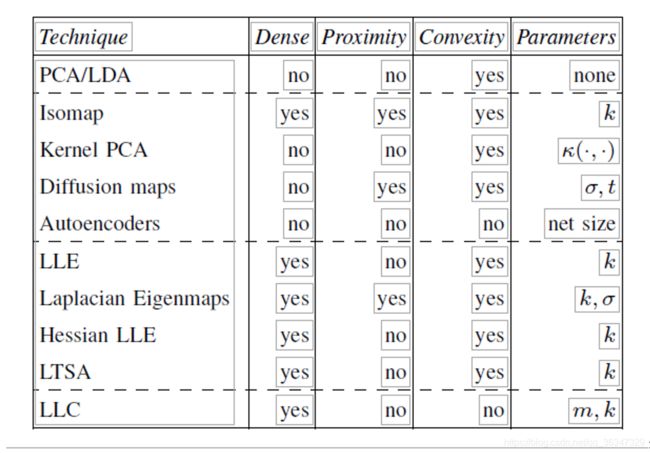
我们简要讨论了下面的四个一般属性。首先,表 I 中描述的常规属性显示,使用邻域图的降维技术都需要对数据进行采样密集,因为这些技术均应遵循局部线性假设。密集采样表明局部线性假设(在某种程度上)相对于流形的曲率和尺寸是有效的。此属性其实是一个缺点,因为在实际的应用程序中,数据量通常很少。因此,在维度减小中采用邻域图的非线性技术在采样不佳的数据上性能较差。
其次,表一显示,一些非线性技术允许使用邻近输入。允许邻近作为输入的属性扩展了技术适用范围,例如,数据是离散但存在适当距离度量的任务。在这方面,一些非线性技术在降维方面比线性技术具有优势。
第三,表一显示,大多数降维技术优化了凸成本函数,这是有利的,因为它允许找到成本函数的全局最优值。由于其非凸成本函数,LLC和自动编码器可能会遭受卡在局部最优的状态。
第四,表一显示,降维的非线性技术都有需要优化的自由参数。自由参数直的是直接影响优化的成本函数的参数。读者应注意,用于降维的迭代技术具有其他自由参数,如学习速率和最大迭代次数。表一显示,在自由参数数量方面,用于降维的线性技术相对于非线性技术具有优势,因为如何选择合适的参数本身就是一个问题。
综上,表一显示,与线性技术相比,用于降维的非线性技术具有一种或多种缺点的一般特性。相反,一些非线性技术的优点是允许邻近作为输入。
B. 计算复杂度
降维技术的计算复杂度对其适用性具有重要意义。如果所需的内存或计算资源变得太大,应用程序将变得不可行。降维技术的计算复杂性由数据点n的数量、原始维度 D、目标维度 d以及参数(如,最近k邻域(基于邻域图的技术))和迭代次数 i(迭代技术)等参数决定。在表二中,我们概述了技术主要部分的计算和存储复杂性。在表中,p 表示稀疏矩阵中非零元素的比率,m 表示因子分析器混合中的模型数,w表示神经网络中权重的数量。下文阐明了表二的复杂性。 对于线性技术 PCA 和 LDA,样本外扩展(即如何在低维空间中嵌入新数据点)非常简单。在 PCA 和 LDA 中,通过将新数据点与线性映射矩阵 M 相乘来计算M样本外扩展。类似的方法对于内核 PCA 也是可行的。对于自动编码器,因为受训练的网络定义了从高维数据表示到低维数据表示的转换,因此可以轻松执行样本外扩展,。 在许多实际应用中,需要有监督的学习设置。降维技术支持监督学习的程度对于此类应用非常重要。降维技术可以通过 Fisher 标准(如 LDA 中所做的那样)利用类标签中的信息。在广义鉴别分析 [3]中,Fisher 标准在由核函数(类似于内核 PCA)构建的高维空间中最大化,从而允许非线性映射。[84]中提议将Fisher标准纳入MDS的变体。然而,[84]中介绍的方法很难最小化复杂的非凸成本函数,导致效果不佳。在[60]中,自动编码器的监督变体具有强大的性能。针对此提出尝试利用局部非线性技术中的类标签如LLE和LTSA。在这两种技术中,相似性矩阵delt都替换为相似性矩阵 delt’ ,delt‘’包含有关数据的局部属性和数据点的类标签的信息。这种方法的缺点是不允许适当的样本外扩展。 在上一节中,我们评估了用于降维的线性和非线性技术理论属性,表明与非线性技术(就以下五个属性中的一个或多个)比较,线性降维技术具有优势:(1) 基本假设,(2) 自由参数,(3) 计算复杂性,(4)样本外扩展和 (5) 监督。本节对降维线性和非线性技术的性能进行了系统的实验比较。通过测量两种类型的数据集的分类任务中的泛化误差来执行评估:(1) 人工数据集和 (2) 自然数据集。 在实验中,我们将降维技术应用于数据的高维表示,并根据获得的数据的低纬表示评估各种分类器的泛化性能。我们进行这种基于分类的技术评估的动机,而不是基于测量重建误差的动机是,对于大多数自然任务而言,真正的低维数据表示是未知的。 在表三中,我们介绍了使用降维技术处理的人工数据集训练的线性判别分类器的泛化误差。左列指示数据集的名称以及我们减少三维数据集的维度。每个数据集的最佳性能技术以粗体显示。从表三的结果中,我们可以进行五个观察。首先,我们发现没有一种方法优于数据集上的所有其他方法。在实验结果中,LDA、Isomap、扩散图、Hessian LLE、LTSA和LLC在选定的数据集上均处于优势。 在上一节中,我们观察到非线性技术虽然能够学习复杂非线性流形的结构,但在自然数据集不优于线性技术。在本节中,我们将讨论非线性技术的各种弱点,这些弱点解释了我们的实验结果。我们的结果表明,不采用邻域图(例如内核 PCA、扩散贴图和自动编码器)的非线性降维技术在人工数据集和自然数据集上的表现并不优于线性技术。最有可能的是由于这些技术的以下四个弱点。首先,基于内核的方法,如内核PCA需要选择一个合适的内核函数,这是一个很难的问题。通常,内核方法中的模型选择使用某种形式的保持测试 [26]执行,从而导致计算成本高。内核方法模型选择的替代方法基于,例如,使用半限定编程[46]、[79]最大化类间边距或数据方差。其次,根据参数的选择,用于降维的全局技术可能遭受与局部技术类似的弱点(例如,当使用值较小的高斯内核时)。第三,具有非凸成本函数(如自动编码器)的技术收敛较慢,并陷入局部最小区域。第四,在[79]中,高斯内核在降维方面的使用通常会导致性能不佳。这一说法由使用扩散图的实验结果的支持。 本文对降维技术进行了回顾和比较研究。从获得的结果可以得出结论,非线性降维技术虽然具有更高的建模能力,但还不能超过线性技术。将来,我们预见非线性技术的发展,他们将在许多个线性模型中表示数据流形几何形状。基于线性模型(如 LLC)全局对齐的技术是朝着这一目标迈出的良好一步,正如我们在自然数据集上的实验结果表明的。
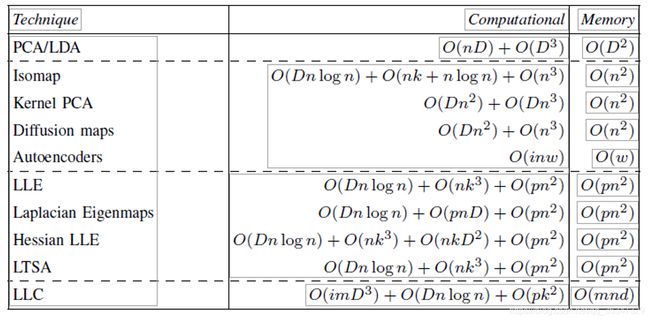
PCA和LDA中所需的协方差矩阵的计算具有O(nD)的计算复杂度。使用O(D3)中的幂方法对所需的D×D协方差矩阵进行特征分析。由于PCA和LDA存储D×D协方差矩阵,因此它们的存储复杂度为O(D2)。
Isomap、扩散贴图和内核PCA 使用O(n3))中的方法对nx n矩阵进行特征分析。Isomap执行 n 次其他最近邻居搜索,具有计算复杂性 O(Dnlogn) [41],并在O(nk+ nlogn) 中的邻域图上执行 Dijkstra 的算法O(使用斐波那契堆实现)。扩散映射和内核 PCA 在O(Dn2)中执行额外的内核计算(对于高斯内核)。 由于 Isomap、扩散映射和内核 PCA 存储完整的 nxn 内核矩阵,因此这些技术的内存复杂性为 O(n2)。)
与上面讨论的技术相比,自动编码器是迭代的。使用反向传播训练自动编码器在O(inw)中执行。自动编码器的训练收敛速度可能非常缓慢,尤其是在输入和目标维度非常高的情况下(因为这在网络中会产生大量权重)。自动编码器的内存复杂性为 O(w)。
与内核 PCA 类似,用于降维的局部技术执行对nx n矩阵的特征分析。但是,对于局部技术,nxn 矩阵是稀疏的。矩阵的稀疏性是有益的,因为它降低了基因分析的计算复杂性。稀疏矩阵的特征分析(使用Arnoldi或Jacobi-Davidsson方法)具有计算复杂性O(pn2)其中p是稀疏矩阵中非零到零元素的比率。对于 LLE 和 Laplacian Eigenmaps,p 的值通常低于 Hessian LLE 和 LTSA 的值,从而使得前一种的计算强度降低。除了稀疏权重矩阵的特征分析外,LLE、Laplacian Eigenmaps、Hessian LLE和LTSA在O(Dn logn)中构造了一个最接近的邻图。此外,LLE 在 O(nk3))中求解n个大小k xk 的线性方程组。Laplacian Eigenmaps在O(pnD)中执行稀疏高斯内核计算。Hessian LLE和LTSA在O(nk3)中计算大小为k xk的n矩阵的特征分解。此外,Hesiian LLE对k×D矩阵执行n次Gram-Schmidt正交化,运算复杂度为O(nkD2)。)
LLC 是一种既包含迭代部分又包含频谱部分的技术。首先,LLC为i个迭代执行EM算法,以构造m因子分析仪的混合物。因此,该部分的计算复杂性受O(imD3))的约束。随后,LLC在O(nlogn))中执行k邻近,解决(O(pk2)中大小k x k的广义本征问题。由于 EM 算法存储了 m因子分析器的数据表示形式,所以LLC 的内存复杂性为O(mnd)。
从上述降维技术的计算和内存复杂性评估中,我们观察到非线性技术与线性技术相比存在计算劣势(如果我们假设D C. 样本外扩展
对于其他非线性降维技术,样本外扩展并不简单。介绍了一种用于 Isomap、LLE和 Laplacian Eigenmaps 的样本外扩展方法[8],其中在内核 PCA 中重新定义了这些技术
框架,从而允许样本外扩展。在 [14] [18] 中提出了类似的Isomap样本外扩展方法。[48]中提出了一种可用于所有非线性降维技术的样本外扩展估计方法。该方法在高维表示中查找新数据点的最近邻域,并计算从最近邻域到其相应低维表示的线性映射。通过在此数据点上应用相同的线性映射,可以找到新数据点的低维表示形式。
从上面的评估中,我们观察到线性和非线性的降维技术相似,因为它们允许样本外扩展。但是,对于许多非线性技术,只能使用估计方法执行样本外扩展,从而导致样本外扩展中的估计误差。D. 监督
从上面的评估中,我们发现线性和非线性是相似的,因为它们允许利用数据的类标签。Fisher 标准可以在非线性技术中最大化,并且监督自动编码器在某些任务上表现出色。但是由于缺乏适当的样本外扩展,将监督纳入本地非线性技术的尝试通常不适用。六、 实验
我们的实验设置在第六-A分节中进行了描述。在第六-B分节中,介绍了我们对七个人工数据集的实验结果。第VI-C小节介绍了七个自然数据集的实验结果。A. 实验设置
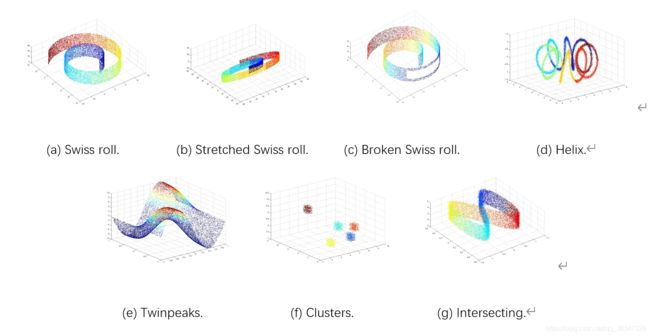
我们对7个人工数据集和7个自然数据集进行了实验。我们进行实验的人工数据集是:(1) 瑞士卷数据集,(2) 拉伸的瑞士卷数据集,(3) 破碎的瑞士卷数据集,(4) 螺旋数据集,(5) 双峰数据集,(6) 聚类数据集,(7) 相交数据。图 3 显示了七个人工数据集的图。属于同一类的数据点分配相同的颜色。所有人工数据集(聚类数据集除外)均由 20,000 个样本组成。聚类数据集由 3,000 个样本组成。人工数据集的实验结果可用于调查技术在多面数的曲率变化、流形中的相交处以及具有多个小流形中的情况下如何处理的数据集上执行。
对于我们对自然数据集的实验,我们选择了七个数据集来表示来自各种域的任务:(1) MNIST 数据集,(2) COIL20 数据集,(3) ADA 数据集,(4) GINA 数据集,(5) HIVA 数据集,(6) NOVA 数据集,(7) SYLVA 数据集。
MNIST 数据集是包含 60,000 个手写数字的数据集,我们随机选择了 20,000 位数字进行实验。由于 MNIST 数据集中的图像大小为 28 × 28,因此可以视为 784 维空间中的点。COIL20 数据集包含 20 个不同对象的图像,从 72 个视点进行描绘。图像的大小为 32×32 像素,导致 1,024 维空间。ADA、GINA、HIVA、NOVA 和 SYLVA 数据集是二进制的分类数据集,用于最近的NIPS基准测试。ADA 数据集源自营销域,由 48 维空间中的 4,147 个数据点组成。GINA 数据集是手写识别数据集,包含由 970 个要素描述的 3,153 个数据点。HIVA 数据集是一个化学数据集,包含 3,845 个数据点,尺寸为 1,617 个维度。NOVA 数据集是一个文本分类数据集,包含 1,754 个样本,位于 16,969 维空间中。SYLVA 数据集源自生态领域,由 13,086 个数据点组成,具有 216 个维度。自然数据集实验的结果提供了对维度缩减技术在真实数据集上表现的见解。
在人工数据集上,我们使用线性区分分类器进行了实验。线性区判别分类器的选择是出于以下知识:人工数据集中的所有类边界都是线性的(在高维数据表示中)。在自然数据集上,我们使用五个分类器进行了实验:(1) 1 最近的邻域分类器,(2) 线性判别器,(3) 二次判别器,(4) 朴素的贝叶斯分类器,(5) 最小二乘支持向量机 (LS-SVM)。通过使用五个不同的分类器,我们确保所选分类器不会影响结果。所有实验的结果都是通过10倍交叉验证获得的。实验中使用的参数设置是通过初步实验中的保持测试确定的。
在实验中,我们不考虑技术的样本外扩展。我们进行了没有外扩展的实验,因为我们想知道的是降维技术本身的质量。此外,通过将新样本添加到现有数据、执行降维并在低维空间中对测试样本进行分类,可以轻松执行样本外扩展。
B. 人工数据集
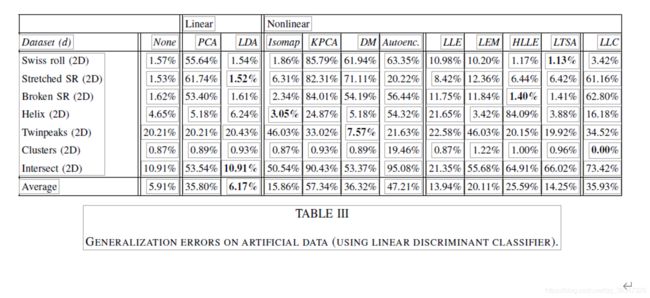
其次,我们观察到,大多数采用邻域图(即,Isomap,LLE,Laplacian Eigenmaps,Hessian LLE和LTSA)的非线性技术在人工数据集上优于PCA。另一方面,不采用邻域图(即扩散贴图、内核 PCA 和自动编码器)的非线性技术对瑞士卷数据集等数据集的性能较差。LLC 在人工数据集上表现出了与 PCA 相当的性能。第三,我们观察到,大多数技术在面对相交数据集时存在严重问题。除 LDA 外,所有技术都混合了相交数据集的二维表示中的类。第四,将拉伸的瑞士卷数据集的结果与正常瑞士卷数据集的结果进行比较,得出LLC在拉伸的瑞士卷数据集中的曲率变化中受到严重影响。 Isomap、Hessian LLE 和 LTSA 也受到流形曲率变化的影响。结果没有表明数据流形中存在孔对技术的性能有负面影响。
第五,表三的结果表明,四种降维技术在所有非相交人工数据集上取得了良好的性能:(1) LDA,(2) LLE,(3) 拉普拉西亚Eigenmaps和(4)LTSA。
图4显示了由降维技术10构建的瑞士卷数据集的二维表示。从描述的表示形式中,我们得出三个观察结果。首先,我们观察到,不构造数据邻域图的技术(即PCA、LDA、扩散贴图、内核PCA和自动编码器)无法成功学习瑞士卷的二维结构。其次,我们观察到,LLE和Laplacian Eigenmaps构建的低维表示包含全局径向失真,有时称为折叠[11]。这些径向失真导致最初为线性的流形上的类边界中的非线性。第三,这些图表明 Laplacian Eigenmaps能够学习流形的整体结构,但在流形的低维表示中局部扭曲。局部失真是Laplacian Eigenmaps中最小化的成本函数的结果,其目的是在数据的低维表示中最小化近数据点之间的距离。C. 自然数据集
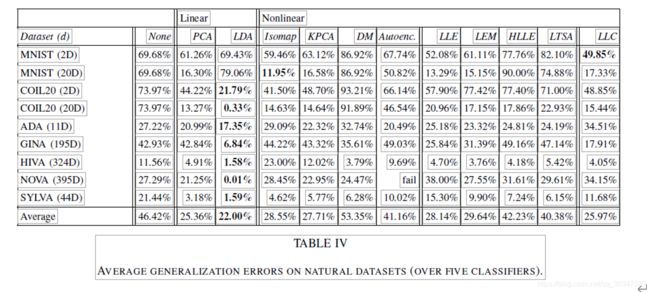
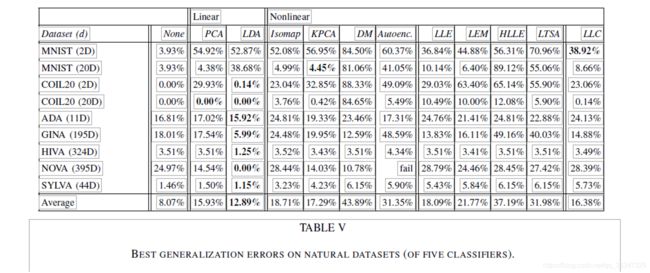
表四显示了我们在七个真实数据集中量上测量的平均泛化误差。泛化误差在五个分类器以上平均:(1) 1 个接近的邻域分类器,(2) 线性判别器,(3) 二次判别器,(4) 朴素贝叶斯分类器,(5) 最小二乘-支持向量机。表五报告五个分类器的最佳泛化误差。在表中,左列指示数据集的名称以及我们试图转换为高维数据的目标维度。请注意,对于 Hessian LLE 和 LTSA,实际低维表示的维度不高于12,因为我们设置了 k = 12。对于 LDA,低维数据表示的实际维度不超过类数减去 1。数据集的最佳性能技术以粗体显示。
从表四和表五的结果中,我们得出三个结论。首先,我们观察到,结果表明非线性降维技术的强大性能并不从人工数据集推广到自然数据集。平均而言,LDA和PCA这两种线性技术在降维方面优于非线性技术。LLC 是唯一能与 PCA 媲美的非线性技术。其次,结果表明,尽管在人工数据集上性能较差,内核PCA在自然数据集上的性能较好。此观察甚至适用于具有可直观清晰识别的数据集,例如 COIL20 数据集(因为它包含旋转对象的图像)。与内核 PCA 相比,局部非线性技术在 COIL20 数据集上的性能较差。第三,我们观察到,对于具有高维数 D(如 NOVA 数据集)的数据集,使用自动编码器是不可行的。在我们的实验中,由于内存不足(在具有 32GB RAM 的服务器上),自动编码器未能降低 NOVA 数据集的维数。七.讨论
基于邻域图的非线性降维技术不受上述弱点的影响,但在自然数据集上表现不佳。最有可能的是,自然数据集的性能不佳是由于以下四个弱点造成的。首先,有理论论证认为,基于邻域图的技术在嵌入流形的维度(即数据的内在维度)上受到维度的影响[7]。对于高固有维度,允许邻域图正确描述数据所需的数据点数量呈指数级增长。显然,对于低固有维数的人工数据集,此弱点不适用。然而,在大多数实际任务中,数据的内在维度要高得多。其次,在流形周围存在噪音时,流形的局部特性不一定遵循流形的全局结构(例如,例如[10],[58])。换句话说,局部技术在流形上过度拟合。通过构建多个线性模型,然后对齐这些线性模型(如 LLC 中所示),可以克服此缺点。在这种方法中,低维数据表示中流形的全局几何体不会因流形过度拟合而失真。LLC 方法的缺点是使用 EM 算法构造因子分析仪的混合物。EM 算法受到局部最小值的影响,并且对异常值非常敏感 [16]。此外,线性模型的全局对齐需要仔细优化所使用的线性模型的数量(除了优化线性模型的参数)。第三,局部的降维方法受到折叠[11]的影响。折叠是由相对于流形的采样密度(部分)过高的k的值引起的。折叠的结构违反了局部线性假设,从而导致径向或其他失真。在真实数据集中,由于数据的采样密度不等于整个流形(例如,因为前一个不是均匀分布在流形上),因此可能发生折叠。可能解决此问题的方法是自适应邻域选择。自适应邻域选择技术在[51]、[61]、[77]中介绍。第四,局部降维技术的问题是它们对异常值的敏感性[13]。在局部降维技术中,异常值连接到其 k 最近的邻居,即使它们非常遥远。因此,异常值会降低局部技术的性能,以降低维度。解决此问题的一种可能方法是使用邻域。在邻域中,数据点连接到位于radius范围内的所有数据点。解决异常值问题的另一种方法是预处理数据,以便从数据中删除异常值 [55],[82]。
本文的实证结果与文献中报告的研究结果一致。在选定的数据集上,降维的非线性技术优于线性技术[54],[71],但在许多其他自然数据集上,降维的非线性技术表现不佳[27]、[38]、[39]、[49]。今后的工作应着眼于提高非线性技术的结果。最重要的是,必须减少基于邻域图的降维技术对维度影响的易感性和对噪声的敏感性。通过设计新技术来解决这些问题,这些技术可在多个模型之间共享有关数据流形全局几何的信息 [7]。LLC在自然数据集实验中的相对良好的性能验证了这个说法。今后的工作应解决LLC中线性模型混合的构造中局部极小值的问题。八.总结