深度学习知识点总结-激活函数
深度学习知识点总结
专栏链接:
https://blog.csdn.net/qq_39707285/article/details/124005405
本专栏主要总结深度学习中的知识点,从各大数据集比赛开始,介绍历年冠军算法;同时总结深度学习中重要的知识点,包括损失函数、优化器、各种经典算法、各种算法的优化策略Bag of Freebies (BoF)等。
本章介绍多种激活函数
文章目录
-
- 2.2.激活函数
-
- 2.2.1. 激活函数汇总
- 2.2.2. 激活函数总结分析
2.2.激活函数
任何神经网络的主要目标都是使用层次性层次结构将非线性可分的输入数据转换为更线性可分的抽象特征,这些层是线性函数和非线性函数的组合,最流行和最常见的非线性层是激活函数(AFs),如sigmoid、Tanh、ReLU、ELU、Swish和Mish。
使用不同激活函数在CIFAR10上准确率对比:

使用不同激活函数在CIFAR100上准确率对比:

使用不同激活函数在CIFAR100上训练耗时统计:
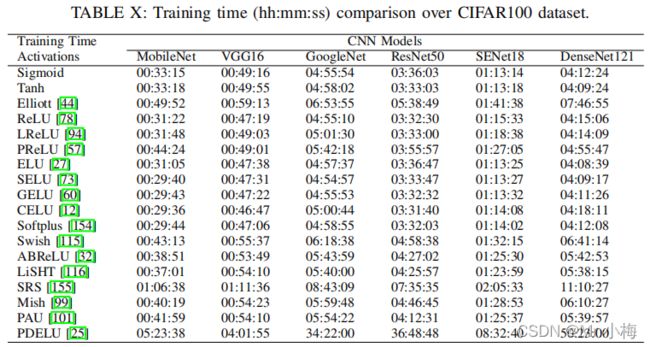
综合实验分析发现:
- Softplus、ELU和CELU激活函数更适合MobileNet;
- ReLU、Mish和PDELU在VGG16、 GoogleNet和DenseNet上表现都很好;
- ReLU、LReLU、ELU、GELU、CELU、ABReLU和PDELU更适合含有残差连接的算法,例如ResNet50,SENet18和DenseNet121等;
- 训练过程中,PDELU非常低效,另外SRS和Elliott也耗时很久。 ReLU, ELU, CELU和Softplus能在准确率和耗时中有一个很好的权衡。
2.2.1. 激活函数汇总
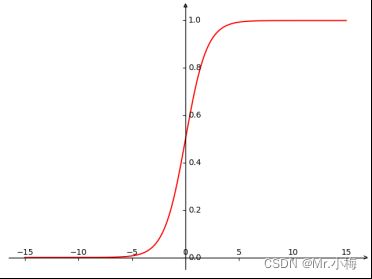
- Logistic Sigmoid

x = np.linspace(-15, 15, 1000)
y = 1 / (1 + np.exp(-x)) # sigmoid
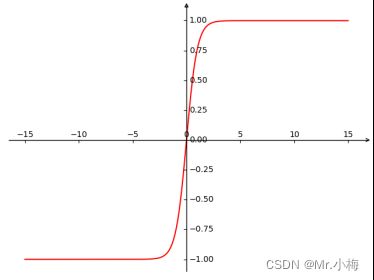
- Tanh

x = np.linspace(-15, 15, 1000)
y = np.tanh(x) # tanh
- ReLU系列
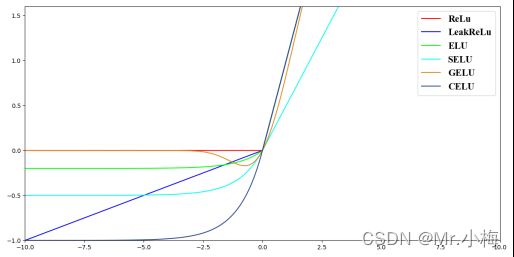
- ReLU

- LReLU
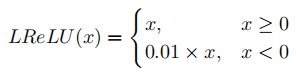
- ELU

- SELU
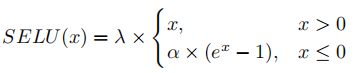
- GELU
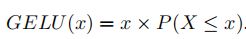
- CELU

import matplotlib.pyplot as plt
import numpy as np
import torch
import torch.nn.functional as F
fig = plt.figure(figsize=(12, 6))
plt.xlim([-10, 10])
plt.ylim([-1, 1.6])
# 定义数值
x = np.sort(np.linspace(-10,10,1000))
# ReLu 函数
relu= [max(item,0) for item in x]
# LeakReLu函数
alpha = 0.1
leakRelu = [item if item > 0 else item * alpha for item in x]
# ELU函数
alpha = 0.2
elu = [item if item > 0 else (np.exp(item) - 1) * alpha for item in x]
# SELU函数
alpha = 1
r = 0.5
selu = [item if item > 0 else (np.exp(item) - 1) * alpha for item in x]
selu = list(map(lambda x: x * r, selu))
# GELU
gelu = F.gelu(torch.Tensor(x)).numpy()
# CELU
celu = F.celu(torch.Tensor(x)).numpy()
# 绘图
plt.plot(x, relu, color="#ff0000", label=r"ReLu")
plt.plot(x, leakRelu, color="#0000ff", label=r"LeakReLu")
plt.plot(x, elu, color="#00ff00", label=r"ELU")
plt.plot(x, selu, color="#00ffee", label=r"SELU")
plt.plot(x, gelu, color="#e0861a", label=r"GELU")
plt.plot(x, celu, color="#2b4490", label=r"CELU")
plt.legend(prop={'family': 'Times New Roman', 'size': 16})
plt.show()
- PReLU

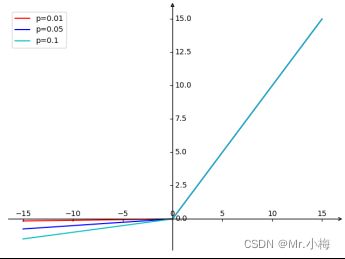
import numpy as np
from matplotlib import pyplot as plt
import mpl_toolkits.axisartist as axisartist
import torch.nn.functional as F
import torch
# 创建画布
fig = plt.figure()
# 使用axisartist.Subplot方法创建一个绘图区对象ax
ax = axisartist.Subplot(fig, 111)
# 将绘图区对象添加到画布中
fig.add_axes(ax)
# 通过set_visible方法设置绘图区所有坐标轴隐藏
ax.axis[:].set_visible(False)
# ax.new_floating_axis代表添加新的坐标轴
ax.axis["x"] = ax.new_floating_axis(0, 0)
# 给x坐标轴加上箭头
ax.axis["x"].set_axisline_style("->", size=1.0)
# 添加y坐标轴,且加上箭头
ax.axis["y"] = ax.new_floating_axis(1, 0)
ax.axis["y"].set_axisline_style("-|>", size=1.0)
# 设置x、y轴上刻度显示方向
ax.axis["x"].set_axis_direction("top")
ax.axis["y"].set_axis_direction("right")
x = np.linspace(-15, 15, 1000)
x = torch.Tensor(x)
# PReLU
y = F.leaky_relu(x, 0.01)
y2 = F.leaky_relu(x, 0.05)
y3 = F.leaky_relu(x, 0.1)
plt.plot(np.array(x), np.array(y), c="r", label="p=0.01")
plt.plot(np.array(x), np.array(y2), c="b", label="p=0.05")
plt.plot(np.array(x), np.array(y3), c="c", label="p=0.1")
plt.show()
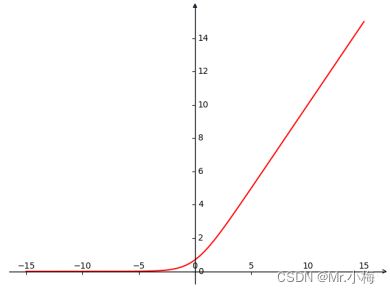
- Elliott
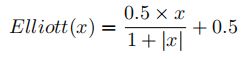
y = (0.5 * x) / (1+np.abs(x)) + 0.5

- Softplus

slu = F.softplus(torch.Tensor(x))
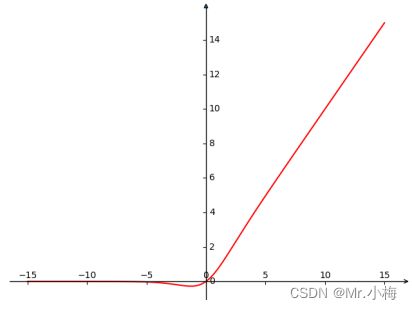
- Swish
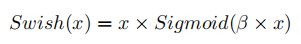
swish = x.mul(F.sigmoid(x))
-
ABReLU

-
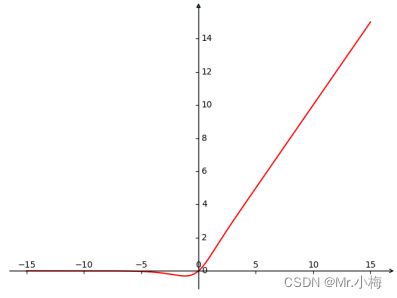
LiSHT
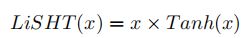
lisht = x.mul(F.tanh(x))

-
SRS

-
Mish
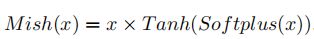
mish = F.mish(x)
-
PAU
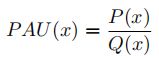
-
PDELU
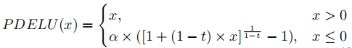
-
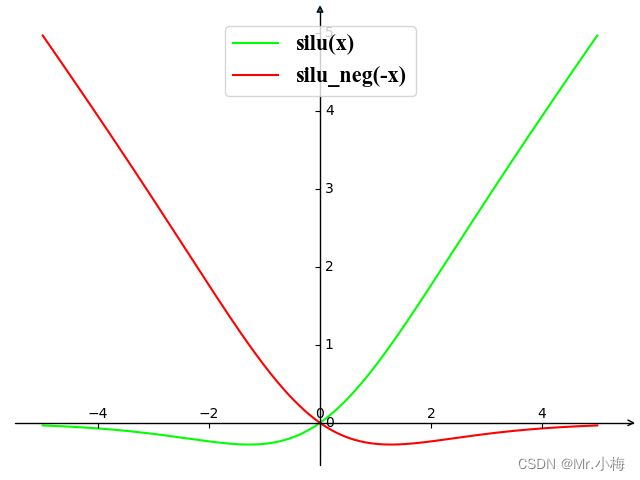
SiLU

mish = F.silu(x)
2.2.2. 激活函数总结分析
总结:
- Logistic Sigmoid和Tanh主要改进目标是解决非零均值和零梯度的问题,然而这些改进附带着复杂性增加的缺点。
- ReLU变体主要解决ReLU存在的三个问题,即负值利用不足,有限非线性和无界输出。LReLu和ABReLU在含有残差连接的模型中表现较好,但LReLU,PReLU和ABReLU在MobileNet,VGG和GoogleNet模型中表现不如ReLU好。 ReLU,Leaky ReLU和PReLU是目前模型中最常见的选择。
- 基于指数的AFs还注重更好地利用负值,并避免重要功能的饱和。然而,由于函数非光滑,大多数指数激活受到影响。
- 基于学习的自适应AFs试图找到最佳参数来表示给定数据集所需的非线性。然而,与这种AF相关的主要问题是找到更好的基函数和可训练参数的数量。如果没有正确初始化,一些AFs在训练期间会出现分歧。
改进建议:
- 为了加快训练速度,负值和正值都应用来使用,来确保平均值接近零。
- 在深度学习中,最重要的一个方面是找到与数据集复杂度相匹配的网络。如果模型的复杂度较高,则可能导致过度拟合;如果模型的复杂度较低,则可能导致欠收敛。因此,在训练期间,AF应根据模型和数据集的复杂性自动弥合这一差距。
- 卷积神经网络应避免Logistic Sigmoid和Tanh,因为会导致收敛性差。然而,这种类型的AFs通常被用作RNN中的门(gates)。
- ReLU、Mish和PDELU激活函数在VGG16和GoogleNet中表现出良好的性能。ReLU、LReLU、ELU、GELU、CELU和PDELU函数更适合于具有含有残差连接的网络。
- 一般来说,带参数的AFs具有更好的收敛性,因为它可以通过从数据中学习参数来更快地适应数据。例如,PAU、PReLU和PDELU表现出更好的收敛性。
- 一些AFs会增加训练时间,例如PDELU和SRS。然而,诸如ReLU、SELU、GELU和Softplus等AFs可以达到准确率和训练时间的折衷。
- 由于使用负值,指数AFs通常会导致线性增加。
- Tanh和SELU AFs与PReLU、LiSHT、SRS和PAU更适合语言翻译。
建议使用PReLU、GELU、Swish、Mish和PAU AFs进行语音识别。