The State Of Knowledge Distillation For Classification Tasks
The State Of Knowledge Distillation For Classification Tasks
我们调查了简单分类任务的各种知识提取(KD)策略,并实现了一组声称具有最新准确性的技术。我们使用标准化的模型架构、固定的计算预算和一致的训练计划进行的实验表明,这些蒸馏结果中的许多很难重现。这在使用某种形式的特征提取的方法中尤其明显。进一步的检查显示出缺乏可概括性,这些技术可能只适用于特定的架构和培训设置。我们观察到,适当调谐的经典蒸馏与数据增强训练方案相结合,比其他技术给出了正交改进。我们验证了这种方法并开源了我们的代码1。
1 Introduction
现代的深层神经网络是资源密集型的,这限制了它们在带宽受限和低功耗环境下的生存能力。目前大多数设备上运行的强大的深度学习模型的大小限制了GPU大小和电池电量有限的边缘设备。因此,近年来,模型压缩(model compression)这门试图在保持精度的同时减小特定网络规模的学科受到了广泛的关注。
模型压缩的一个很有前途的子类是知识蒸馏,它在一个较大的模型(教师)的logits上训练一个资源需求较低的较小的模型(学生)。这些逻辑被认为是教师模式的“黑暗知识”,是学生继续学习的附加信号。这些软目标更容易为学生建模,并已被证明能提高最终学生的准确性。
在这项工作中,我们着手调查丰富的知识提取景观及其在图像分类压缩方面的收获。我们有三个明确的目标
1。实施最先进的分类和验证顶级执行方法。
2。了解这些方法是如何正交工作的。
3。评估每种技术的概括性。
我们使用CIFAR10[9]数据集作为所有实验的基准,并限制所有技术,以便为所有实验使用一致的优化器、计算预算和单个数据增强方案。令人惊讶的是,我们的实验表明,vanilla知识蒸馏在经过仔细的超参数调整后表现最佳。最令人惊讶的是,特征提取技术的性能似乎比所有其他方法都差。事实上,我们遇到的最大的因素是,当我们转向不同架构的教师时,蒸馏性能的差异。
2 Knowledge Distillation
目前最常见的蒸馏损失是由Hinton等人首次提出的。[7] 2014年。Hinton等人提出的知识蒸馏,试图通过训练一个除任务损失外还有蒸馏损失的模型,提供另一条获取任务知识的途径。这种蒸馏损失是在教师网络的帮助下产生的,这种网络是“繁琐的”,即规模很大,但在任务上达到了很高的精度。蒸馏的目的是通过蒸馏损失来帮助学习,从而提高较小网络(学生)的准确性。准确的KD损失定义为:

2.1 Extensions
这些年来,许多人对知识蒸馏的概念做了进一步的修改。最初由Romero等人(2014年[12])开发的一个特定研究领域,通过在培训过程中也将教师的中间表征层视为提示来增强知识转移。提取学生任务的中间表示常被称为特征提取,是一个新兴的研究领域。最近,将特征提取引入到特定的任务和模型类型中受到了广泛的关注。各种方法都试图提取用于语言建模的BERT模型,并报告模型尺寸减小了7.5x,精度只有小幅度的降低[18],TinyBERT[8]提出了一种新的 transformer蒸馏方法,该方法通过最小化 transformer网络各层之间的均方误差来工作。
他们还提出了一个两步训练管道,首先训练一个通用的BERT模型,然后再结合数据增强技术,对该通用模型在下游任务上进行微调。消融研究证实了这种训练方法的有效性,以及多头注意attention layers的重要性。类似Sun等人的工作,2019[13],被称为“患者知识蒸馏”,通过最小化学生和教师的每个个体层的均方误差损失来提取BERT。
在图像分类领域,Heo等人,2019[5]对特征提取的现状进行了全面的调查。他们推测他们提出的方法,包括一个带margin ReLU的特征变换,蒸馏特征位置的仔细选择,以及部分L2距离函数,超过了他们以前的工作(AB蒸馏[6]),并导致了最新的精度。
一种不同于以往蒸馏技术的方法是Park等人的关系知识蒸馏(RKD),2019年[11]。RKD的区别在于它关注教师和学生产出的结构差异,而不是计算个人产出的损失。RKD引入了一个距离损失和一个角度损失,旨在弥补关系团队除了使用特征蒸馏损失和辛顿损失外,还使用这些损失和精心调整的超参数。
Mirzadeh等人,2019[10]假设学生从老师那里学到的东西太先进了,因此跟不上。为了解决这个问题,他们首先通过提炼教师来培养一个中等规模的“助理”网络。然后从这个中间助手身上提炼出这个学生网络。It结果表明,利用助教的知识转移,学生能够获得比基线知识蒸馏更高的准确性。
3 Baselines
我们选择第2.1节中描述的一组高性能技术来评估知识蒸馏的状态:激活边界蒸馏(AB)、检修蒸馏(OH)、关系知识蒸馏(RKD)和教师辅助蒸馏(TAKD)。在下一节中,我们将详细说明如何将每种方法集成到我们的评估流程中。
3.0.1 Activation-Boundary Distillation (AB)
Heo等人,2019[6]提出基于“活化边界”计算蒸馏损失,活化边界定义为正响应和负响应之间的差异。这与比较两个特征层响应的绝对大小相反。我们选择AB蒸馏法,因为作者声称CIFAR100的性能优于Hinton损失。不幸的是,我们在采用AB蒸馏法时遇到了很大的困难,即使我们可以访问作者的代码库。AB蒸馏已经在广泛的ResNets上进行了测试[17],它需要来自神经网络模型的高度特定的信息(每层的输入通道数、对模型具体各个层的访问以及每个特征输出)。因此,ResNet模型必须手动调整以适应所建议的方法。这需要选择要提取的隐藏层,根据大小差异匹配学生/教师的特征映射维度,并调整用于特征提取的超参数。我们在许多特征提取研究工作中遇到的这种特殊性,是特征提取的一个重要缺点。
该方法本身在应用ReLU之前比较特征值,并在每个层上使用自定义的“铰链式”损失。AB蒸馏分为两个阶段。首先,学生通过将其特征与教师翻译的特征对齐来初始化。在此之后,学生将接受标准知识提炼的培训。我们把这两个阶段分成60:40的部分,如文中所述。首先进行嵌入初始化,然后进行常规知识提取训练。在初步实验中,我们观察到与KD几乎没有差别,可能是因为第二蒸馏阶段占主导地位。因此,我们决定重新完成这项工作的后续工作,检修蒸馏。
3.0.2 Overhaul Distillation (OH)
OH蒸馏的操作与AB蒸馏类似,但通过重新考虑从中选择特征向量的位置来改进。在应用ReLU之前,OH选择特定的蒸馏位置并计算特征和活化边界损失。希望通过仔细选择相关的ReLU层,只考虑激活边界,只考虑最必要的信息。我们能够通过参考作者的codebase2并通过对ResNet模型进行必要的调整来获得这些信息,从而将此技术集成到我们的评估管道中。
3.1 Relational Knowledge Distillation (RKD)
RKD使用各种损失函数,所有这些函数都试图测量向量的一些相关性质。这些概念以角距离损失、距离损失和“暗秩”的形式表示,暗秩通常用于度量学习。RKD还利用了传统的KD、注意力转移(AT)[16]和FitNet[12]损失。
使用这个损失集成,RKD声称在Cifar100上性能最好。我们重新实现了RKD中不需要访问模型特定特性的部分。这意味着我们不使用AT和FitNet亏损。然而,虽然这可能会损害整体性能,但我们仍然期望比传统的知识蒸馏有所改进。不幸的是,本文中使用的CIFAR10蒸馏代码在本项目实施时并不公开3。我们根据论文的描述,通过联系作者并询问细节,重新实现了这一方法。
3.2 Teacher-Assistant Distillation (TAKD)
教师助理知识提炼[10]遵循一个简单的前提。最近的工作[3]声称自蒸馏实际上可以提高基础模型的准确性,受此启发,TAKD提出了蒸馏的多个阶段。TAKD没有从一个大老师训练成一个学生,而是使用“教师助理”(TA)。助教通常是同一体系结构的较小模型,它弥合了教师和学生之间的表达差距。这个命题是助教能够翻译学生可能无法表达的教师分类。
4 新技术
我们开发了三种新的知识蒸馏变体,我们将在下面详细介绍。
4.0.1 Simple Feature Distillation (SFD)
病人知识提取(PKD)[13]是一种用于BERT模型压缩的技术,但它的通用性足以将其转换为视觉任务。其基本思想是简单地将学生和教师每一层之间的均方误差最小化。受PKD的启发,我们实现了一种称为简单特征提取(SFD)的方法。SFD自动检索模型的所有层,并在教师层上应用max pool操作,使其减小到学生层的大小。Max pool在保持强信号的同时压缩特征层。我们用deconvolutional、插值和平均池化层进行了实验,观察到它们之间没有显著差异。
一旦特征层被匹配,学生和老师之间的均方误差损失将最小化。这种方法背后的直觉是将学生的激活与教师的压缩、翻译表示对齐。我们还尝试了最小化特征图的KL发散,并观察到最终验证精度没有差异。
4.0.2 Ensemble Distillation (MKD)
基于Hinton的观察和TAKD的论文,我们在一个“多面手”教师群体下训练一名学生。此方法简单地平均每个教师和学生输出的Hinton KD-Lost。期望学生在各种不同的信号下能更好地概括。我们使用同一架构的多个模型来表示教师群体。
4.0.3 Unsupervised Distillation (UDA)
最后,我们还借鉴了无监督数据增强学习的技术[15]。我们建立了一个训练方案,其中数据加载器使用数据扩充策略randagment[1]在同一个小批量中输出一个未经整理的图像和一个扩充的图像。此策略通过从一组手工挑选的数据扩展中随机挑选一个转换来工作,这些数据扩展在CIFAR10中工作得很好。我们通过将一个增强图像和一个未整合图像的师生登录对相加,将Hinton知识蒸馏损失最小化。我们把这种损失称为UDA-Cifar loss.。
在另一个实验中,我们将STL-10和Cifar10数据集连接起来。在培训期间,遇到Cifar10样本时-使用UDA Cifar损失,遇到STL10无监督样本时-使用UDA[15]损失。这种方法的直觉是使用更多的数据,并使用自我监督训练的范式来挤出改进。
我们确保在一个小批量中拥有相同数量的Cifar10和STL样本,正如我们观察到的,如果不使用这种硬示例挖掘,模型的性能会更差。我们称这种方法为STL。这项实验的灵感来源于观察到,一名学生从一名接受过Cifar10培训的教师那里蒸馏出来,使用STL数据集进行蒸馏,在没有接受过Cifar10培训的情况下,对Cifar10的验证准确率为83%。
5 Experiments
我们的实验包括三个主要阶段。首先,为了了解知识蒸馏的特性,我们进行了超参数和模型结构分析。根据分析结果,我们选择一个教师和参数配置,并使用相同配置运行所有实现的技术。然后,我们选择性能最好的技术,并在多次大范围运行中平均它们的性能。
5.1 Setup
我们的大多数测试都在CIFAR10[9]数据集上执行。我们之所以选择CIFAR,是因为我们在原始工作中关注图像分类,并且考虑到它的计算可行性。我们可以在更小的设备上训练CIFAR,而不需要多个GPU设置。我们测试的一个重要重点是确保公平和公平的条件。相应地,所有的知识蒸馏实验都在相同的条件下进行。我们所有的测试都是用同一个优化器执行的。启用Nesterov的随机梯度下降,动量为0.9,初始学习率为0.1,在总时间段的33%和66%时下降了0.1。权重衰减固定为0.0005。对于训练,我们使用传统的CIFAR10增强方法来增强数据。我们对每个图像进行规格化,应用随机水平翻转,并将图像随机裁剪为32x32大小,填充4。验证集仅规范化。
我们使用的模型来自几个不同的来源。由于PyTorch示例架构是为ImageNet[2]设计的,因此我们主要使用Github用户Kuangliu5流行的ResNet[4]架构,该架构经过优化以在CIFAR10和CIFAR100上实现高精度。
这些模型在验证集上很快达到了95%以上的准确率,我们认为这已经足够了。对于知识提炼,我们使用这个模型的一个重剥离版本ResNet8。ResNet8只包含三个主要块,而不是四个,并且具有更少的参数。比较对于我们最小的4层ResNet ResNet10,它有4903242个参数,占用25.28MB的空间,ResNet8只使用89322个参数,占用2.88mb的内存空间。我们将有效的ResNet8用于我们所有的知识蒸馏实验。基本精度达到89%。我们认为任何可靠地达到90%以上的技术都是成功的。
5.2 Parameter Tuning
在我们进行CIFAR10分类测量之前,我们进行了广泛的超参数搜索,以了解经典知识蒸馏中的权衡。我们问了自己两个问题。1) T和a的不同组合对蒸馏性能的影响。2) 教师的结构对表现有影响吗?
对于1)我们训练了一个ResNet8和一个Resnet26老师,每次a=[0.1,0.4,0.5,0.7,1.0]和T=[1,5,10,15,20]组合150个阶段。表1突出显示了选定的结果。结果表明,我们所建立的知识蒸馏系统对参数选择具有较强的鲁棒性,且性能差异不大。即使是使用0.1的a进行的测试,其性能也显著高于正常训练(0.8814)。
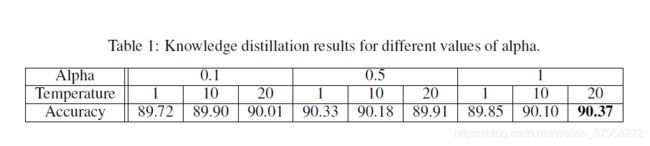
我们的第二个测试评估了模型结构对蒸馏性能的影响。再次,我们训练了150个epoch的ResNet8,并选择了不同的教师体系结构进行比较。表2突出显示了结果。有趣的是,模型架构对最终的精确性结果有很大的影响。教师(ResNet20,ResNet26)在相同的结构下获得最高的分类准确率,即使他们可能没有最高的分类准确率。
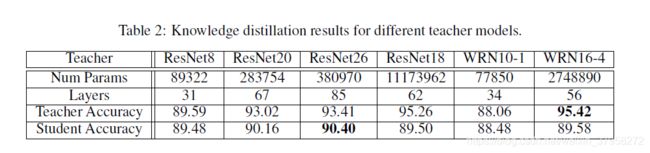
宽ResNets[17](WRN10-1和wrn16-4)和4层ResNets(ResNet18)在结构上不同,这会影响学生模拟教师输出的能力。我们还对ResNet18进行了额外的测试,以评估较高的温度值是否能改善性能,但我们没有观察到任何明显的变化效果。这个可能是因为模型之间的参数差异没有表现出足够的幅度。
根据1)和2)中的结果,我们最终决定挑选一名准确率为93.41的ResNet26教师,并为所有后续测试进行a为0.5和T为5的培训。
5.3 Cifar10 Classification Experiments
5.3.1 Preliminary Comparisons

我们使用第5.1节中描述的配置为200个阶段运行每个实现的技术。对于每次运行,我们收集所达到的最高验证精度。表3显示了结果。不幸的是,所有的特征提取技术都表现得很差,甚至无法打败正常的训练。只有RKD优于基线,但这可能是由于SFD和OH中缺少额外的知识蒸馏损失。
5.4 In-depth Analysis
我们更深入地研究了所有优于知识蒸馏的技术。我们删除了MKD,因为它无法获得比KD更高的性能。我们用350次迭代重新进行了实验,并对每种技术的结果进行了平均。表4显示了最终结果。UDA蒸馏明显优于TAKD和正常KD,这意味着无监督的数据增强损失可以提供实质性的好处。

为了验证这一性能提升不仅仅是因为常规的数据增强,我们还运行了一个带有Hinton损失的UDA测试。虽然它取得了比常规训练更好的成绩,但在最终成绩上比KD仍有显著的提高。**我们推测,简单的知识提取与复杂的增强和高参数调整相结合,可以匹配高精度的特征提取技术。**不幸的是,由于我们无法及时再现“工作”特征提取方法,我们无法证实这一假设。
6 Conclusion
我们观察到,达到95%准确度的resnet18能够将resnet8学生提取到88.5%的准确度。然而,改用resnet26教师,其最终验证准确率为93%,可以更有效地蒸馏。结果同样的resnet8学生获得了90.5%的准确率,使准确率提高了近2%。
我们还观察到,特征提取是一个困难的问题,我们所有的实验都是用最先进的方法进行的,比学生的基线表现差。有一种观点认为,学生可能太小,无法有效地模拟问题。我们的模型可能只是达到了参数化建模的极限,无法获得更好的精度。
90.5%的准确率,使准确率提高了近2%。
我们还观察到,特征提取是一个困难的问题,我们所有的实验都是用最先进的方法进行的,比学生的基线表现差。有一种观点认为,学生可能太小,无法有效地模拟问题。我们的模型可能只是达到了参数化建模的极限,无法获得更好的精度。
我们计划在未来的工作中探索剪枝和特征提取的结合,并了解如何识别神经网络的参数建模的限制。