后缀自动机SAM
后缀自动机简介
某个字符串s得后缀自动机SAM满足如下性质:
- SAM是一个有向无环图,结点称为状态,表示一个或多个不同字符串,边称为转移,表示一个字符
- SAM有一个可以到达任何结点的源点 t 0 t_0 t0,它是唯一的,从 t 0 t_0 t0出发到达任意结点经过的转移边连起来就是s得一个子串
- 从源点出发任意两条不同路径表示的字符串不同,从源点出发不能形成的路径都不是s的子串
- SAM有若干个中止结点,从源点到任意中止结点形成的字符串都是s的后缀,且s的所有后缀都可以被某个从源点到中止结点的路径表示
- 在满足上述条件的自动机中,SAM的结点数是最少的
除开最后一个性质,SAM和AC自动机看起来差不多
但其最后一个性质却能保证SAM比AC自动机有优秀得多的时间和空间复杂度
EndPos集合与Parent Tree
Endpos的定义
对字符串S的任意非空子串t,我们记endpos(t)为t在S中所有结束位置的集合(假设索引从1开始)
例如对于字符串 S = a b a b c S=ababc S=ababc,则 e n d p o s ( " a b a " ) = { 3 } , e n d p o s ( " a b " ) = { 2 , 4 } endpos("aba")=\{3\},\ endpos("ab")=\{2,4\} endpos("aba")={3}, endpos("ab")={2,4}
显然S的不同子串可能有相同的endpos,我们可以把S的所有非空子串根据其endpos集合划分成若干个等价类,即属于相同等价类的子串endpos相同
Endpos的性质
引理1:字符串S的两个不同非空子串u、w(设 ∣ u ∣ ≤ ∣ w ∣ |u|\leq |w| ∣u∣≤∣w∣),当且仅当u是w的后缀,且u每次都已w的后缀形式出现在S中时,u、w的endpos相同
显然易证
引理2:字符串S的两个不同非空子串u、w(设 ∣ u ∣ ≤ ∣ w ∣ |u|\leq |w| ∣u∣≤∣w∣)。
若u是w的子串,则 e n d p o s ( w ) ⊆ e n d p o s ( u ) endpos(w) \subseteq endpos(u) endpos(w)⊆endpos(u)
若u不是w的子串,则 e n d p o s ( w ) ⋂ e n d p o s ( u ) = ∅ endpos(w) \bigcap endpos(u) = \emptyset endpos(w)⋂endpos(u)=∅
通俗点说就是S的两个子串,他们的endpos要么是包含关系,要么不相交
引理3:同一endpos等价类中的子串长度连续,且较短者一定是较长者的后缀
由引理1,同一等价类中较短者是较长者的后缀显然成立
下面用反证法简单证明同一endpos等价类中的子串长度连续:
对于某一等价类,假设u、w分别为其中最短和最长的字符串,假设某字符串v是w的真后缀且u是v的真后缀
若v与u、w不在同一等价类中,由引理1,v一定由某次在S中不作为w的子串出现,那么u也一定会这个位置出现一次
此时u的endpos集合显然比w的大,矛盾
用Endpos构造Parent Tree
由引理2,我们不妨把endpos等价类的关系用树表示
即每个结点表示一个等价类,其中结点v是结点u的子节点,当且仅当v表示的等价类对应的endpos是u对应的endpos的子集
由此我们构造了一个森林,再为其加上一个表示空等价类的超级源点,便构成了Parent Tree
此时引理2在Parent Tree上便表示为父节点对应的等价类中的子串一定是子节点等价类中子串的后缀
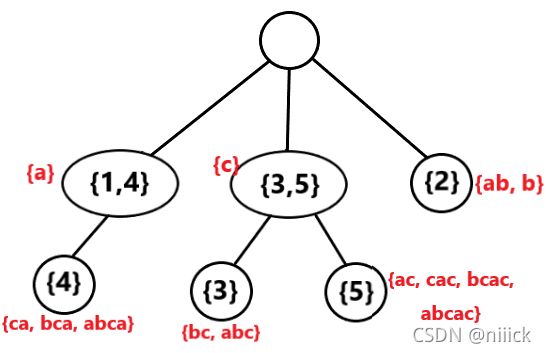
例如字符串S=abcac,其endpos等价类构造的Parent Tree如下图所示
其中结点内标注的是该结点表示的等价类对应的endpos,结点旁红字标注该结点表示的等价类中包含的子串
此处我们再引入两个引理
先定义 l e n ( p ) , m i n l e n ( p ) len(p),minlen(p) len(p),minlen(p)分别表示结点p对应等价类中最长和最短子串的长度
引理4:在Parent Tree中每个结点均满足 l e n ( f a ( p ) ) + 1 = m i n l e n ( p ) len(fa(p))+1=minlen(p) len(fa(p))+1=minlen(p)
设节点q表示的等价类中最长的子串为u,在u前添加一个字符会形成新子串w(假设w也是S的子串)
那么一定有 e n d p o s ( w ) ⊂ e n d p o s ( u ) endpos(w)\subset endpos(u) endpos(w)⊂endpos(u),也即w一定属于q的某个子节点,且是这个子结点中最短的串
由引理3与引理4可以得到一个推论
推论1:设某结点p表示的等价类中最长的串为t,则从p到Parent Tree根节点路径上所有结点表示的等价类,恰好包含了t的所有后缀
这个推论将在构造SAM的过程中用到
引理5:任意一个字符串S (|S|=n) 的endpos等价类数量的阶为O(n)
我们可以通过Parent Tree来简单理解这个引理
假设超级源点表示的endpos集合为{1,2,…,n}
那么Parent Tree就是以超级源点为根开始在每个结点上划分若干次,将划分的每部分作为子节点得到
显然如果对每个结点都只从中间划一下能得到的Parent Tree结点数最多,这个数量为 1 + ∑ i = 1 n 2 i = 2 n − 1 1+\sum_{i=1}^n 2^i=2n-1 1+∑i=1n2i=2n−1
即endpos等价类数量的阶为O(n)
该引理是保证SAM复杂度的重要前提
从Parent Tree到SAM
首先我们明确,构造好的SAM的结点数量与S的endpos等价类数量一样
且这些结点间连接着两套不同的边,分别构成含唯一源点的DAG和Parent Tree
他们之间有一个非常优美的性质
性质1:从源点出发到达某节点p的不同路径构成的所有子串,恰好是p表示的等价类中包含的所有子串
SAM的构造是一个在线算法,可以在已构造好的字符串S的SAM中继续加入字符c,形成S+c的SAM
所以构造过程就是不断在当前字符串末尾加字符的过程
接下来现以一个实例模拟这个过程
构造实例
开始前先回顾前文的一个定义: l e n ( p ) , m i n l e n ( p ) len(p),minlen(p) len(p),minlen(p)分别表示结点p对应等价类中最长和最短子串的长度
下面以S=abcac为例模拟SAM的构造
以下图中均以黑边表示DAG上的转移边,红边表示Parent Tree上子节点指向父节点的边(以下记为后缀连接)
①
初始时只有一个超级源点
加入第一个字符’a’,就新增了一个endpos等价类{a},对应endpos为{1}
我们首先创建一个表示这个等价类的新结点,然后增加转移边与后缀链接如图
(这一步不能很明确的表达SAM的构造思路所以从下一步开始讲解)

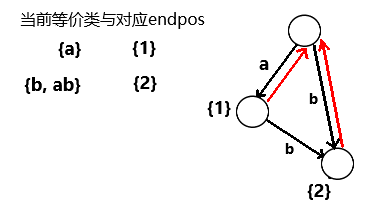
②
接下来加入字符’b’,此时新增了一个endpos等价类{ab, b},对应endpos为{2}
同样新建一个结点(记为cur)表示该等价类
========================================================
添加一条从上一轮创建的结点(记为p)到cur的转移是显然的
这样就有一条表示当前完整字符串的路径
接下来沿p的后缀链接跳到当前Parent Tree根
对经过的每个结点都添加一条到cur的转移(此处先假设这些转移都不存在)
由前文推论1和性质1可知这样可以构造出所有表示"以当前加入字符c为结尾的子串"的路径
最后将cur的后缀链接指向超级源点
加入字符’c’的过程也相同

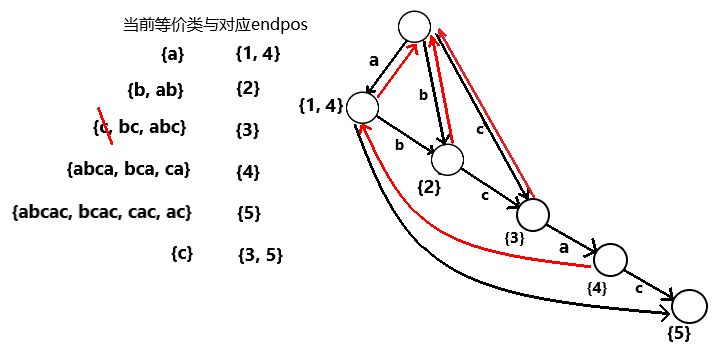
③
接下来加入字符’a’,此时新增了一个endpos等价类{abca, bca, ca},对应endpos为{4}
同时也改变了一个endpos等价类,等价类{a}的endpos从{1}变成了{1, 4}
此时构造不能再使用上文的方法,如下图
我们先创建了表示endpos {4}的结点cur,并从上一轮创建的结点p出发连接了一条转移
但根(p的第一个祖先)已有字符’a’的转移了

========================================================
当我们沿p的后缀链接跳到p的某个祖先p’,却发现p’已存在到新字符c的转移边
我们记这条转移边到达的节点为q,并设t为p表示的等价类中所包含的任意一个子串
显然endpos(t+c) = q所对应的endpos与cur的endpos的并集
若有len( q ) = len( p’ ) + 1
根据引理4可知q表示的等价类只包含一个子串,即 t+c
那么此时q所对应的endpos就变成了q所对应的endpos与cur的endpos的并集
所以我们可以直接令cur得后缀链接指向q

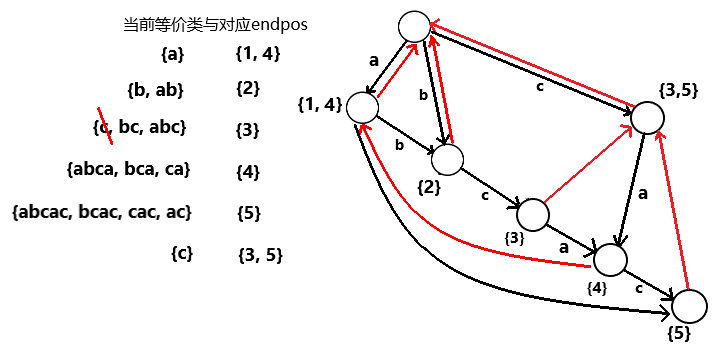
④ 最后加入字符’c’,此时新增了一个endpos等价类{abcac, bcac, cac, ac},对应endpos为{5}
同时也分裂了一个endpos等价类,等价类{c, bc, abc}的分为了{c}和{bc, abc},endpos分别为{3, 5}和{3}
我们同样先创建了表示endpos {5}的结点cur
并从p开始沿后缀链接对经过的添加到cur的转移
但在此过程中又遇到了新的情况——p’已有转移但len( q )=len( p‘ )+1
========================================================
当我们沿p的后缀链接跳到p的某个祖先p’,发现p’已存在到新字符c的转移边
同样记这条转移边到达的节点为q,并设t为p表示的等价类中所包含的任意一个子串
若有len( q ) > len( p’ ) + 1,则说明q表示的等价类中包含若干个子串
显然此时q表示的等价类中除 t+c 外其余子串endpos都没变,而endpos(t+c) = q所对应的endpos与cur的endpos的并集
所以我们从q中分裂出一个新结点单独表示 endpos(t+c)及其对应的等价类
记这个新节点为nq
显然从nq出发应该有和q一样的转移,nq的后缀链接也应该与q的后缀链接相同
由于此时nq对应的endpos为q所对应的endpos与cur的endpos的并集
所以q和cur的后缀链接都应该指向nq
此时便可以把p’及其祖先的指向q的转移c指向nq

至此SAM的构造就完成了
代码实现
我们先总结一下上文实现SAM构造的方法
每加入一个新字符c就新建一个结点cur,记上一轮新建的结点为p
从p开始沿后缀链接向根(源点)走,对经过的结点添加字符c的转移
若所有经过的结点都没有字符c的转移,则最后cur的后缀链接指向根
若某结点p’已有字符c的转移则,记该转移到达q
此时若len( q ) = len( p’ ) + 1,则cur的后缀链接指向q
若len( q ) > len( p’ ) + 1,则分裂q产生新结点nq,nq有和q一样的转移和后缀链接
将cur和q的后缀链接指向nq,并令p’及其祖先的指向q的转移c指向nq
可以证明构造SAM的时间复杂度为 O ( n ) O(n) O(n)
对每个结点定义结构体
struct state{
int ch[26]; // 转移边
int len,fa; // 等价类中最长子串长度 和 后缀链接
state(){memset(ch,0,sizeof(ch)); len=fa=0;}
}st[maxn<<1];
int last=1,sz=1;
令源点为1,上一轮新建的结点为last,初始时last指向源点
下面是主要过程
void addToSAM(int c)
{
int p=last, cur=last=++sz; // 新建节点
st[cur].len=st[p].len+1; // 新结点等价类中最长子串长度为当前完整字符串长度
while(p && !st[p].ch[c]) // p开始沿后缀链接向源点,对经过的结点添加字符c的转移
{
st[p].ch[c]=cur;
p=st[p].fa;
}
if(!p) st[cur].fa=1; // cur的后缀链接指向根
else
{
int q=st[p].ch[c];
if(st[p].len+1==st[q].len) st[cur].fa=q; //cur的后缀链接指向q
else // 分裂q
{
int nq=++sz;
st[nq].len=st[p].len+1; // nq只含有t+c
st[nq].fa=st[q].fa; // nq转移和后缀链接与q一样
memcpy(st[nq].ch, st[q].ch, sizeof(st[q].ch));
st[q].fa=st[cur].fa=nq; // cur和q的后缀链接指向nq
while(p && st[p].ch[c]==q) // p及其祖先的指向q的转移c指向nq
{
st[p].ch[c]=nq;
p=st[p].fa;
}
}
}
}
int main()
{
scanf("%s",str);
int len=strlen(str);
for(int i=0;i<len;++i)
addToSAM(str[i]-'a');
}
SAM的应用
匹配子串
Q:给定一个文本串T和一个模式串P,问P是否作为T的子串出现
A:对T构造SAM,从源点开始沿转移边不断匹配P的每个字符,能匹配完就说明P在T中出现过
不同子串个数
洛谷P2408 不同子串个数
Q:给定一个字符串S,求S有多少个本质不同的子串
A:有两种解法
方法一:
文章开头提到了SAM的一个性质
从源点出发任意两条不同路径表示的字符串不同,从源点出发不能形成的路径都不是s的子串
所以本题就是求从源点出发有多少条不同的路径
而后缀自动机是一个DAG,所以只需要做一个DAG上的DP就行了
即构造好S的SAM,设 d p [ u ] dp[u] dp[u]表示从点u出发的不同路径条数
初始时 d p [ u ] = 1 dp[u]=1 dp[u]=1,转移方程 d p [ u ] = ∑ d p [ v ] , < u , v > ∈ E dp[u]=\sum dp[v] ,
答案就是 d p [ 1 ] dp[1] dp[1],该算法时间复杂度为 O ( n ) O(n) O(n)
方法二:
注意到本质不同的子串数量就是所有等价类大小之和
根据引理3——同一endpos等价类中的子串长度连续,以及引理4——每个结点均满足 l e n ( f a ( p ) ) + 1 = m i n l e n ( p ) len(fa(p))+1=minlen(p) len(fa(p))+1=minlen(p)
我们可以得到每个结点u表示的等价类得大小,即 l e n ( p ) − l e n ( f a ( p ) ) len(p)-len(fa(p)) len(p)−len(fa(p))
所以本质不同的子串数量为 ∑ l e n ( p ) − l e n ( f a ( p ) ) \sum len(p)-len(fa(p)) ∑len(p)−len(fa(p))
该算法时间复杂度为 O ( n ) O(n) O(n)
该方法相较于方法一,可以在向SAM添加字符的过程中动态维护本质不同的子串数量
子串出现次数
洛谷P3804 【模板】后缀自动机 (SAM)
Q:给定一个字符串S,求其某个子串t的出现次数
A:
SAM中任意结点表示的等价类中包含的子串出现次数就是该等价类对应的endpos大小
而求某个结点对应endpos大小只需要在Parent Tree上dfs即可
设 n u m [ u ] num[u] num[u]表示结点u的endpos大小
若u是构造SAM时添加字符时新建的结点而不是分裂某结点得到的,初始化num[u]=1
因为这样的结点表示的等价类对应的endpos一定只含有添加新字符时的末尾位置
之后dfs从Parent Tree叶子开始 n u m [ u ] = ∑ n u m [ v ] ( f a ( v ) = u ) num[u]=\sum num[v] \ (fa(v)=u) num[u]=∑num[v] (fa(v)=u)即可得到每个结点的num
那么对于某个子串t的出现次数,只需要沿转移边找到t对应的末尾结点,输出其num
该算法时间复杂度为 O ( n ) O(n) O(n)
第k小子串
洛谷P3975 [TJOI2015]弦论
Q:给定一个字符串S,求其第k小子串
A:
先求出 d p [ u ] dp[u] dp[u]表示从点u出发的不同路径条数
从源点出发,每次按字典序枚举转移到的结点v,若dp[v]>k就进入v继续找,否则k-=dp[v]
最后输出经过的转移表示的字符即可
P3975这题还有另一个“不同位置的相同子串算作多个”的条件
此时求从点u出发的不同路径条数时初始化条件改为dp[u]=u对应的的endpos大小即可